(Inkoly/Shutterstock)
Genai entrou em cena rápido e furioso quando o ChatGPT foi lançado em 30 de novembro de 2022. A busca por modelos maiores e melhores mudou o {hardware}, o knowledge heart e o poder A paisagem e os modelos fundamentais ainda estão em rápido desenvolvimento. Um dos desafios no HPC e na computação técnica é descobrir onde Genai “se encaixa” e, mais importante, “o que tudo isso significa” em termos de descobertas futuras.
De fato, os efeitos do mercado de destaque de recursos foram principalmente devido à criação e treinamento de grandes modelos de IA. O mercado de inferência esperado (implantando os modelos) pode exigir HW diferente e deve ser muito maior que o mercado de treinamento.
E quanto ao HPC?
Além de tornar as GPUs escassas e caras (mesmo na nuvem), essas mudanças rápidas sugeriram muitas perguntas na comunidade do HPC. Por exemplo;
- Como o HPC pode alavancar Genai? (Pode?)
- Como se encaixa nas ferramentas e aplicativos tradicionais de HPC?
- O Genai escreve código para aplicativos HPC?
- Genai pode raciocinar sobre ciência e tecnologia?
As respostas a essas e outras perguntas estão próximas. Muitas organizações estão trabalhando nessas questões, incluindo o Trilhão de consórcio de parâmetros (TPC) – IA generativa para ciência e engenharia.
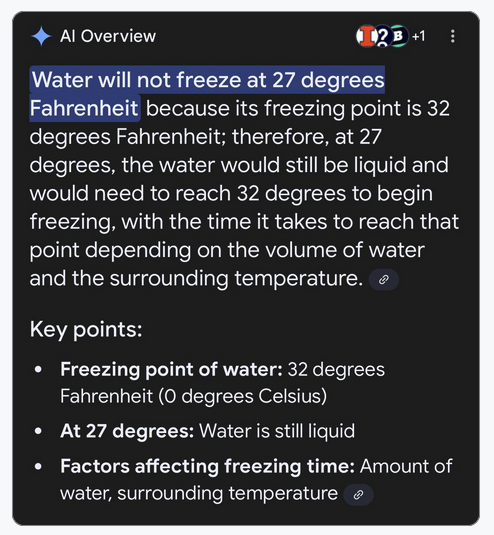
O que foi relatado, no entanto, é que, com todas as melhorias no LLMS, eles continuam, de tempos em tempos, para fornecer respostas imprecisas ou erradas (eufemisticamente chamadas de “alucinações”). Considere o seguinte immediate de pesquisa e a resposta subsequente gerada pela IA. Alguém fez uma pergunta de química no nível da escola primária: “A água congelaria a 27 graus F?” E a resposta é comicamente errada e parece sujeita a raciocínio defeituoso. Se Genai trabalhar em ciência e tecnologia, os modelos devem ser aprimorados.
Talvez mais dados o façam ajuda
A “inteligência” do LLMS inicial foi aprimorada, incluindo mais dados. Como resultado, os modelos se tornaram maiores, exigindo mais recursos e tempo de computação. Conforme medido por alguns benchmarks emergentes, a “inteligência” dos modelos melhorou, mas há um problema com essa abordagem. Modelos de escala significa encontrar mais dados e, em um sentido simples, os fabricantes de modelos já rasparam uma grande quantidade de Web em seus modelos. O sucesso da LLMS também criou mais conteúdo da Web na forma de artigos de notícias automatizados, resumos, postagens de mídia social, escrita criativa and so on.
Não há números exatos; As estimativas são essa 10-15% do conteúdo textual da Web hoje foi criado pela IA. As previsões indicam que até 2030, o conteúdo gerado pela IA poderia compreender mais de 50% dos dados textuais da Web.
No entanto, há preocupações sobre os LLMs que comem seus próprios dados. Sabe -se geralmente que os LLMs treinados nos dados gerados por outros modelos de IA levarão a uma degradação no desempenho em relação às gerações sucessivas – uma condição chamada modelo de colapso do modelo. De fato, os modelos podem alucinar o conteúdo da Net (“Não, a água não congelará a 27F”), que pode se tornar um novo modelo – e assim por diante.
Além disso, o lançamento recente de ferramentas de geração de relatórios como o OpenAI Deep Analysis e o Gemini Deep Analysis do Google facilita para os pesquisadores criar trabalhos e documentos, sugerindo tópicos para pesquisar ferramentas. Agentes como pesquisas profundas são projetadas para realizar pesquisas extensas, sintetizar informações de várias fontes da Net e gerar relatórios abrangentes que inevitavelmente irão Encontre o seu caminho para o treinamento de dados Para a próxima geração de LLMs.

Espere, não criamos nosso ter dados
O HPC cria pilhas de dados. Os números tradicionais de hpc flexionam para avaliar modelos matemáticos usando dados e parâmetros de entrada. Em certo sentido, os dados são únicos e originais e oferecem as seguintes opções
- Limpo e completo – sem alucinações, sem dados ausentes
- Ajustável – podemos determinar a forma dos dados
- Preciso – frequentemente testado contra experimento
- Quase ilimitado – gerar muitos cenários
Parece não haver cauda para comer com dados científicos e técnicos. Um bom exemplo é o Microsoft Aurora (não deve ser confundido com os resultados climáticos do sistema climático baseado em Aurora Exascale) de Argonne) (coberto em hpcwire).
Usando esse modelo, a Microsoft afirma que o treinamento da Aurora em mais de um milhão de horas de dados meteorológicos e climáticos resultou em um aumento de 5.000 vezes na velocidade computacional em comparação com a previsão numérica. Os métodos de IA são agnósticos de Quais são as fontes de dados usado para treiná -los. Os cientistas podem treiná -los em dados tradicionais de simulação, ou também podem treiná -los usando actual Dados de observação, ou uma combinação de ambos. Segundo os pesquisadores, os resultados da Aurora indicam que aumentar a diversidade do conjunto de dados e também o tamanho do modelo pode melhorar a precisão. Os tamanhos de dados variam de acordo com algumas centenas de terabytes até um petabyte de tamanho.
Grandes modelos quantitativos: LQMS
A chave para a criação de LLMs é a conversão de palavras ou tokens em vetores e treinamento usando muitas Matrix Math (GPUs) para criar modelos representando relacionamentos entre os tokens. Usando a inferência, os modelos prevêem o próximo token enquanto respondem a perguntas.
Já temos números, vetores e matrizes em ciências e engenharia! Não queremos prever a próxima palavra como grandes modelos de Langue; Queremos prever números usando grandes modelos quantitativos ou LQMs.
Construir um LQM é mais difícil que prédio um LLM e requer uma compreensão profunda do sistema que está sendo modelado (IA), acesso a grandes quantidades de dados (huge knowledge) e ferramentas computacionais sofisticadas (HPC). Os LQMs são construídos por equipes interdisciplinares de cientistas, engenheiros e analistas de dados que trabalham juntos em modelos. Uma vez concluído, o LQMS pode ser usado de várias maneiras. Eles podem ser executados em supercomputadores para simular diferentes cenários (ou seja, aceleração do HPC) e permitir que os usuários explorem perguntas “e se” e prevêem resultados sob várias condições mais rapidamente do que o uso de modelos numéricos tradicionais.
Um exemplo de uma empresa com sede em LQM é a Sandbotaq, coberto de Aiwire Isso foi saído do Google em março de 2022.
Seu financiamento whole é relatado como US $ 800 milhões e eles planejam se concentrar em criptografia, sensores quânticos e LQMs. Seus esforços de LQM se concentram em ciências da vida, energia, produtos químicos e serviços financeiros.
Mas …, gerenciamento de dados
Lembre -se de huge knowledge, nunca foi embora e está ficando maior. E pode ser um dos maiores desafios para a geração de modelos de IA. Conforme relatado em Bigdatawire“Os inibidores tecnológicos mais frequentemente citados para implantações de IA/ml são armazenamento e gerenciamento de dados (35%) – significativamente maior que a computação (26%),Relatório recente da S&P World Market Intelligence.
Além disso, é computacionalmente viável realizar processamento de IA e ML sem GPUs; No entanto, é quase impossível fazê-lo sem o armazenamento adequado de alto desempenho e escalável. Um fato pouco conhecido sobre a ciência de dados é que 70% a 80% do tempo gasto em projetos de ciência de dados está no que é comumente conhecido como engenharia de dados ou análise de dados (o tempo não gasto em modelos em execução).
Para entender completamente as necessidades de armazenamento do modelo, Glen Lockwood fornece uma excelente descrição do processo de armazenamento e gerenciamento de dados de modelos de AI em uma postagem recente do weblog.
Ciclo Virtuoso AI de Andrew Ng
Se alguém considera Andrew NgO ciclo virtuoso da IA, que descreve como as empresas usam a IA para criar produtos melhores, a vantagem de usar a IA fica clara.
 O ciclo, como ilustrado na figura, tem as seguintes etapas
O ciclo, como ilustrado na figura, tem as seguintes etapas
- Inicia com usuário atividade, que gera dados sobre o comportamento do usuário
- Dados deve ser gerenciado – com curadoria, marcada, arquivada, armazenada, movida
- Os dados são executados Aique outline hábitos e propensões do usuário
- Permite que as organizações construam melhores produtos
- Atrai mais usuários, o que gera mais dados
- E o ciclo continua.
A estrutura do ciclo virtuoso da IA ilustra o loop auto-reforçador da inteligência synthetic, onde os algoritmos aprimorados levam a melhores dados, o que, por sua vez, aprimora ainda mais os algoritmos. Este ciclo explica como os avanços em uma área de IA podem acelerar o progresso em outros, criando um ciclo virtuoso de melhoria contínua.
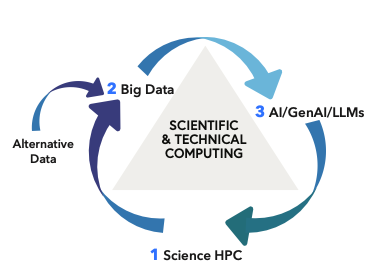
O ciclo virtuoso para a computação científica e técnica
Semelhante ao ciclo virtuoso para a criação de produtos, um ciclo virtuoso para a computação científica e técnica se desenvolveu em muitos domínios. Conforme descrito na imagem, o ciclo digital inclui HPC, Massive Knowledge e IA em um loop de suggestions positivo. O ciclo pode ser descrito do seguinte modo;
- Pesquisa científica e HPC: a ciência do neto requer capacidade de HPC e tem a capacidade de gerar um quantity muito alto de dados.
- Dados Feeds Modelos de IA: o gerenciamento de dados é elementary. Altos volumes de dados devem ser gerenciados, limpos, selecionados, arquivados, adquiridos, armazenado
- Os modelos de “dados” melhoram a pesquisa: armados com informações dos dados, os modelos de IA/LLMS/LQMS analisam padrões, aprendem com exemplos e fazem previsões. Os sistemas HPC são necessários para treinamento, inferência e previsão de novos dados para a etapa 1.
- Espuma, enxágue, repita
Usando este ciclo virtuoso Os usuários se beneficiam desses indicadores -chave:
- Loops de suggestions positivo: Como Crescimento viral, loops de suggestions positivo impulsionam o sucesso da IA.
- Melhorias levam a mais uso, o que por sua vez combuste aprimoramentos adicionais.
- Efeitos de rede: quanto mais usuários, melhores os modelos de IA se tornam. Uma base de usuários forte reforça o ciclo.
- Ativo estratégico: as idéias orientadas pela IA se tornam um ativo estratégico. Pesquisa científica que aproveita esse ciclo oferece uma vantagem competitiva.
A manifestação prática do ciclo virtuoso da IA não é apenas uma estrutura conceitual, mas está reformulando ativamente o ambiente de pesquisa digital. À medida que as organizações de pesquisa adotam e entendem a IA, elas começam a obter os benefícios de um ciclo contínuo de descoberta, inovação e melhoria, se mantendo perpetuamente para a frente.
O novo acelerador de HPC
O HPC está constantemente procurando maneiras de acelerar o desempenho. Embora não seja uma peça específica de {hardware} ou software program, o ciclo virtuoso de IA visto como um todo é um grande salto de aceleração para a ciência e a tecnologia. E estamos no início da adoção.

Esta nova period do HPC será construída no LLMS e LQMS (e outras ferramentas de IA) que fornecem aceleração usando “modelos de dados”Derivado de numérico dados e actual dados. HPC tradicional, verificado e testado “modelos numéricos”Será capaz de fornecer dados de treinamento bruto e possivelmente ajudar a validar os resultados dos modelos de dados. À medida que o ciclo acelera, a criação de mais dados e o uso de ferramentas de huge knowledge se tornará essencial para o treinamento da próxima geração de modelos. Finalmente, computação quântica, conforme coberto por Qcwirecontinuará a amadurecer e acelerar ainda mais esse ciclo.
A abordagem não é isenta de perguntas e desafios. O ciclo de aceleração criará mais pressão sobre os recursos e soluções de sustentabilidade. Mais importante ainda, o ciclo virtuoso para a computação científica e técnica comerá sua cauda?
Mantendo você no loop virtuoso
A Tabor Communications oferece publicações que fornecem cobertura líder do setor em HPC, computação quântica, huge knowledge e IA. Não é por acaso que esses são componentes do ciclo virtuoso para a computação científica e técnica. Nossa cobertura está convergindo para o ciclo virtuoso há muitos anos. Planejamos entregar HPCAssim, QuantumAssim, Massive knowledgee Ai No contexto do ciclo virtuoso e ajuda nossos leitores a se beneficiar dessas mudanças rápidas que estão acelerando a ciência e a tecnologia.