Você já se perguntou como seu telefone entende comandos de voz ou sugere a palavra perfeita, mesmo sem uma conexão com a Web? Estamos no meio de uma grande mudança de IA: do processamento baseado em nuvem à inteligência no dispositivo. Não se trata apenas de velocidade; É também sobre privacidade e acessibilidade. No centro deste turno está incorporando o NECEDEMMA, o novo modelo de incorporação aberta do Google. É compacto, rápido e projetado para lidar com grandes quantidades de dados diretamente no seu dispositivo.
Neste weblog, exploraremos o que é o incorporação, seus principais recursos, como usá -lo e os aplicativos que ele pode impulsionar. Vamos mergulhar!
O que exatamente é um “modelo de incorporação”?
Antes de mergulharmos nos detalhes, vamos quebrar um conceito central. Quando ensinamos um computador a entender o idioma, não podemos simplesmente alimentar as palavras, porque os computadores processam apenas números. É aí que entra um modelo de incorporação. Funciona como um tradutor, convertendo texto em uma série de números (a vetor) isso captura significado e contexto.
Pense nisso como uma impressão digital para o texto. Quanto mais duas peças de texto são, mais próximas suas impressões digitais estarão em um espaço multidimensional. Essa ideia simples alimenta aplicativos como pesquisa semântica (encontrando significado em vez de apenas palavras -chave) e chatbots que recuperam as respostas mais relevantes.
Entendendo a incorporação de incorporação
Então, o que faz INCEDDINGGEMMA especial? É tudo sobre fazer mais com menos. Construído pelo Google DeepMind, o modelo tem apenas 308 milhões de parâmetros. Isso pode parecer enorme, mas no mundo da IA é considerado leve. Esse tamanho compacto é sua força, permitindo que ele seja executado diretamente em um smartphone, laptop computer ou mesmo um pequeno sensor sem depender de uma conexão de knowledge heart.
Essa capacidade de trabalhar no dispositivo é mais do que apenas um recurso interessante. Representa uma mudança de paradigma actual.
Principais recursos
- Privacidade incomparável: Seus dados permanecem no seu dispositivo. O modelo processa tudo localmente, para que você não exact se preocupar com suas consultas privadas ou informações pessoais sendo enviadas para a nuvem.
- Funcionalidade offline: Sem web? Sem problemas. Os aplicativos criados com o EmbeddingDemma podem executar tarefas complexas, como pesquisar em suas anotações ou organizar suas fotos, mesmo quando você estiver completamente offline.
- Velocidade incrível: Sem latência ao enviar dados para um servidor, o tempo de resposta é instantâneo.
E aqui está a parte authorized: apesar de seu tamanho compacto, o EmbeddingGemma oferece desempenho de última geração.
- Ele mantém o rating mais alto para um modelo de incorporação de texto multilíngue aberto abaixo de 500m no enorme texto que incorpore o benchmark (MTEB).
- Seu desempenho é comparável ou excede o dos modelos quase o dobro do seu tamanho.
- Isso se deve ao seu design altamente eficiente, que pode ser executado em menos de 200 MB de RAM com quantização e oferece uma baixa latência de inferência de sub-15ms no Edgetpu para 256 tokens de entrada, tornando-o adequado para aplicações em tempo actual.
Leia também: Como escolher a incorporação correta para o seu modelo de pano?
Como o incorporação de incorporação é projetado?
Um dos recursos de destaque do IncledDinggemma é o Matryoshka Illustration Studying (MRL). Isso oferece aos desenvolvedores a flexibilidade de ajustar as dimensões de saída do modelo com base em suas necessidades. O modelo completo produz um vetor 768 dimensional detalhado para a qualidade máxima, mas pode ser reduzido para 512, 256 ou até 128 dimensões com pouca perda de precisão. Essa adaptabilidade é especialmente valiosa para dispositivos com restrição de recursos, permitindo pesquisas mais rápidas de similaridade e requisitos de armazenamento mais baixos.
Agora que entendemos o que torna o incorporador poderoso, vamos vê -lo em ação.
Incorporando Gemma: Handson
Vamos criar um pano usando a incorporação de Gemma e Langgraph.
Conjunto 1: Baixe o conjunto de dados
!gdown 1u8ImzhGW2wgIib16Z_wYIaka7sYI_TGKEtapa 2: Carregue e pré -processando os dados
from pathlib import Path
import json
from langchain.docstore.doc import Doc
# ---- Configure dataset path (replace if wanted) ----
DATA_PATH = Path("./rag_demo_docs052025.jsonl") # similar file identify as earlier pocket book
if not DATA_PATH.exists():
elevate FileNotFoundError(
f"Anticipated dataset at {DATA_PATH}. "
"Please place the JSONL file right here or replace DATA_PATH."
)
# Load JSONL
raw_docs = ()
with DATA_PATH.open("r", encoding="utf-8") as f:
for line in f:
raw_docs.append(json.hundreds(line))
# Convert to Doc objects with metadata
paperwork = ()
for i, d in enumerate(raw_docs):
sect = d.get("sectioned_report", {})
textual content = (
f"Situation:n{sect.get('Situation','')}nn"
f"Influence:n{sect.get('Influence','')}nn"
f"Root Trigger:n{sect.get('Root Trigger','')}nn"
f"Advice:n{sect.get('Advice','')}"
)
paperwork.append(Doc(page_content=textual content))
print(paperwork(0).page_content)
Etapa 3: Crie um db de vetor
Use os dados pré -processados e a incorporação da GEMMA para criar um db de vetor:
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
persist_dir = "./reports_db"
assortment = "reports_db"
embedder = HuggingFaceEmbeddings(model_name="google/embeddinggemma-300m")
# Construct or rebuild the vector retailer
vectordb = Chroma.from_documents(
paperwork=paperwork,
embedding=embedder,
collection_name=assortment,
collection_metadata={"hnsw:house": "cosine"},
persist_directory=persist_dir
)Etapa 4: Crie um Retriever híbrido (semântico + BM25 Palavra -chave Retriever)
# Reopen deal with (demonstrates persistence)
vectordb = Chroma(
embedding_function=embedder,
collection_name=assortment,
persist_directory=persist_dir,
)
vectordb._collection.rely()
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain.retrievers import ContextualCompressionRetriever
# Base semantic retriever (cosine sim + threshold)
semantic = vectordb.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"okay": 5, "score_threshold": 0.2},
)
# BM25 key phrase retriever
bm25 = BM25Retriever.from_documents(paperwork)
bm25.okay = 3
# Ensemble (hybrid)
hybrid_retriever = EnsembleRetriever(
retrievers=(bm25, semantic),
weights=(0.6, 0.4),
okay=5
)
# Fast check
hybrid_retriever.invoke("What are the key points in finance approval workflows?")(:3)
Etapa 5: Crie nós
Agora vamos criar dois nós – um para recuperação e outro para a geração:
Definindo estado de Langgraph
from typing import Record, TypedDict, Annotated
from langgraph.graph import StateGraph, START, END
from langchain.docstore.doc import Doc as LCDocument
# We preserve overwrite semantics for all keys (no reducers wanted for appends right here).
class RAGState(TypedDict):
query: str
retrieved_docs: Record(LCDocument)
reply: strNó 1: Recuperação
def retrieve_node(state: RAGState) -> RAGState:
question = state("query")
docs = hybrid_retriever.invoke(question) # returns checklist(Doc)
return {"retrieved_docs": docs}Nó 2: Geração
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
PROMPT = ChatPromptTemplate.from_template(
"""You might be an assistant for Analyzing inner stories for Operational Insights.
Use the next items of retrieved context to reply the query.
If you do not know the reply or there is no such thing as a related context, simply say that you do not know.
give a well-structured and to the purpose reply utilizing the context data.
Query:
{query}
Context:
{context}
"""
)
def _format_docs(docs: Record(LCDocument)) -> str:
return "nn".be a part of(d.page_content for d in docs) if docs else ""
def generate_node(state: RAGState) -> RAGState:
query = state("query")
docs = state.get("retrieved_docs", ())
context = _format_docs(docs)
immediate = PROMPT.format(query=query, context=context)
resp = llm.invoke(immediate)
return {"reply": resp.content material}
Construct the Graph and Edges
builder = StateGraph(RAGState)
builder.add_node("retrieve", retrieve_node)
builder.add_node("generate", generate_node)
builder.add_edge(START, "retrieve")
builder.add_edge("retrieve", "generate")
builder.add_edge("generate", END)
graph = builder.compile()
from IPython.show import Picture, show, display_markdown
show(Picture(graph.get_graph().draw_mermaid_png()))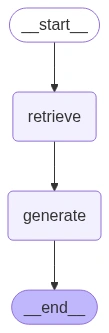
Etapa 6: execute o modelo
Agora vamos executar alguns exemplos no pano que construímos:
example_q = "What are the key points in finance approval workflows?"
final_state = graph.invoke({"query": example_q})
display_markdown(final_state("reply"), uncooked=True)
example_q = "What brought on bill SLA breaches within the final quarter?"
final_state = graph.invoke({"query": example_q})
display_markdown(final_state("reply"), uncooked=True)
example_q = "How did AutoFlow Perception enhance SLA adherence?"
final_state = graph.invoke({"query": example_q})
display_markdown(final_state("reply"), uncooked=True)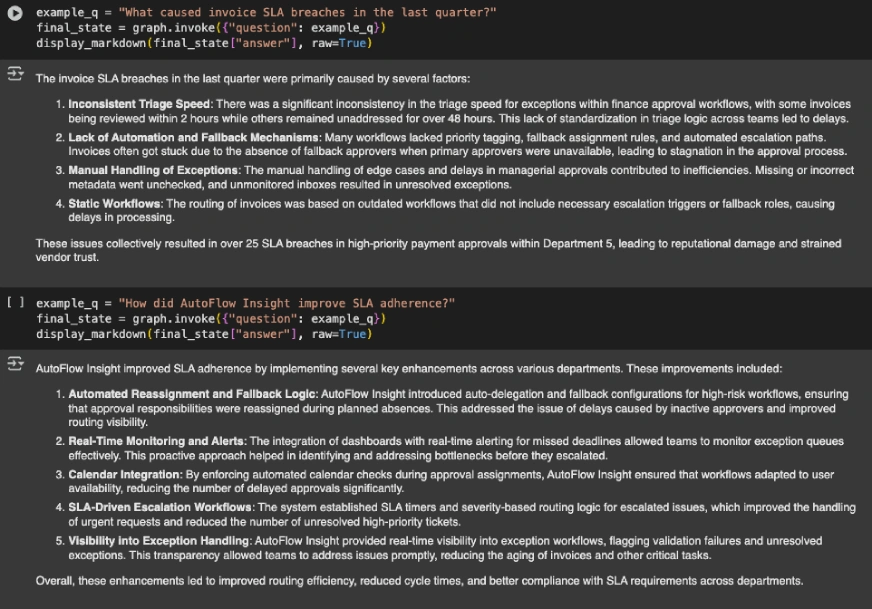
Confira o caderno inteiro aqui.
Incorporando Gemma: Benchmarks de desempenho
Agora que vimos incorporação em ação, vamos ver rapidamente como ele se sai contra seus colegas. O gráfico a seguir quebra as diferenças entre todos os principais modelos de incorporação:
- O incorporador alcança uma pontuação média de MTEB de 61,15, batendo claramente a maioria dos modelos de tamanho semelhante e ainda maior.
- O modelo se destaca na recuperação, classificação com agrupamento sólido.
- Ele supera modelos maiores, como multilíngue-E5-grande (560m) e BGE-M3 (568m).
- O único modelo que supera suas pontuações é o QWEN-EMBEDDING-0.6B, o que é quase o dobro de seu tamanho.
Leia também: 14 técnicas poderosas que definem a evolução da incorporação
Incorporar modelos de incorporação de Gemma vs Openai
Uma comparação importante é entre os modelos de incorporação de incorporação de incorporação e o OpenAI. As incorporações do OpenAI são geralmente mais econômicas para pequenos projetos, mas para aplicações maiores e escaláveis, o incorporação de incorporação tem a vantagem. Outra diferença importante é o tamanho do contexto: as incorporações do OpenAI suportam até 8k tokens, enquanto o incorporador de incorporação atualmente suporta até 2K tokens.
Aplicações de incorporação de mesmo
O verdadeiro poder do incorporação está na ampla variedade de aplicações que ele permite. Ao gerar incorporações de texto de alta qualidade diretamente no dispositivo, ele alimenta uma nova geração de experiências de IA centradas na privacidade e eficientes.
Aqui estão alguns aplicativos -chave:
- Pano: Como discutido anteriormente, o incorporação pode ser usado para criar um pipeline robusto robusto que funcione totalmente offline. Você pode criar um assistente pessoal de IA que possa navegar por seus documentos e fornecer respostas precisas e fundamentadas. Isso é especialmente útil para criar chatbots que podem responder a perguntas com base em uma base específica de conhecimento privado.
- Recuperação de pesquisa e informação semântica: Em vez de apenas procurar palavras -chave, você pode criar funções de pesquisa que entendam o significado por trás da consulta de um usuário. Isso é perfeito para pesquisar através de grandes bibliotecas de documentos, suas anotações pessoais ou a base de conhecimento de uma empresa, garantindo que você encontre as informações mais relevantes com rapidez e precisão.
- Classificação e agrupamento: O incorporação pode ser usada para criar aplicativos no dispositivo para tarefas como classificar textos (por exemplo, análise de sentimentos, detecção de spam) ou agrupá-los em grupos com base em suas semelhanças (por exemplo, organizando documentos, pesquisa de mercado).
- Sistemas semânticos de similaridade e recomendação: A capacidade do modelo de medir a semelhança entre os textos é um componente central dos mecanismos de recomendação. Por exemplo, ele pode recomendar novos artigos ou produtos a um usuário com base no histórico de leitura, mantendo seus dados privados.
- Recuperação de código e verificação de fatos: Os desenvolvedores podem usar o EmbeddingDinggemma para criar ferramentas que recuperam blocos de código relevantes com base em uma consulta de linguagem pure. Ele também pode ser usado em sistemas de verificação de fatos para recuperar documentos que suportam ou refutam uma declaração, aprimorando a confiabilidade das informações.
Conclusão
O Google não apenas lançou um modelo; Eles lançaram um equipment de ferramentas. O INCEDDINGGEMMA se integra a estruturas como Frensformers, llama.cpp e Langchain, facilitando a criação de aplicativos poderosos. O futuro é native. O incorporador de IA permite a IA privacidade, eficiente e rápida que roda diretamente em dispositivos. Ele democratiza o acesso e coloca ferramentas poderosas nas mãos de bilhões.
Anu Madan é especialista em design instrucional, redação de conteúdo e advertising B2B, com um talento para transformar idéias complexas em narrativas impactantes. Com seu foco na IA generativa, ela cria conteúdo perspicaz e inovador que educa, inspira e impulsiona um envolvimento significativo.
Faça login para continuar lendo e desfrutar de conteúdo com curado especialista.