SkyHive é uma plataforma de requalificação ponta a ponta que automatiza a avaliação de competências, identifica necessidades futuras de talentos e preenche lacunas de competências por meio de recomendações de aprendizagem direcionadas e oportunidades de emprego. Trabalhamos com líderes da área, incluindo Accenture e Workday, e fomos reconhecidos como um excelente fornecedor em gestão de capital humano pelo Gartner.
Já construímos um banco de dados de Inteligência do Mercado de Trabalho que armazena:
- Perfis de 800 milhões de trabalhadores (anonimizados) e 40 milhões de empresas
- 1,6 bilhão de descrições de cargos de 150 países
- 3 trilhões de combinações únicas de habilidades necessárias para empregos atuais e futuros
Nosso banco de dados ingere 16 TB de dados todos os dias, desde ofertas de emprego coletadas por nossos rastreadores da net até feeds de dados de streaming pagos. E fizemos muitas análises complexas e aprendizado de máquina para obter insights sobre as tendências globais de trabalho hoje e amanhã.
Graças à nossa tecnologia inovadora, ao bom boca-a-boca e a parceiros como a Accenture, estamos crescendo rapidamente, adicionando de 2 a 4 clientes corporativos todos os dias.
Impulsionado por dados e análises
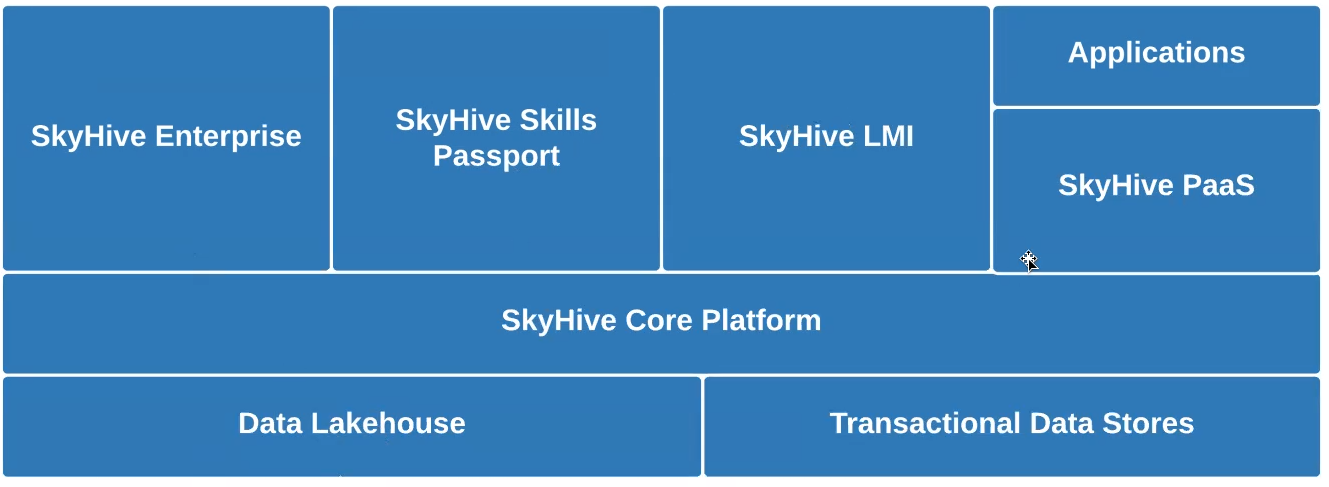
Tal como a Uber, a Airbnb, a Netflix e outras, estamos a revolucionar uma indústria – a indústria world de RH/HCM, neste caso – com serviços baseados em dados que incluem:
- Passaporte de habilidade SkyHive – um serviço baseado na Web que educa os trabalhadores sobre as competências profissionais de que necessitam para desenvolver as suas carreiras e recursos sobre como obtê-las.
- SkyHive Enterprise – um painel pago (abaixo) para executivos e RH analisarem e detalharem dados sobre a) as habilidades profissionais agregadas de seus funcionários, b) quais habilidades as empresas precisam para ter sucesso no futuro; ec) as lacunas de competências.

- Plataforma como serviço through APIs – um serviço pago que permite às empresas obter informações mais profundas, tais como comparações com concorrentes e recomendações de recrutamento para preencher lacunas de competências.
Desafios do MongoDB para consultas analíticas
16 TB de dados de texto brutos de nossos rastreadores da net e outros feeds de dados são despejados diariamente em nosso Lago de dados S3. Esses dados foram processados e carregados em nosso banco de dados analítico e de serviço, MongoDB.

O desempenho das consultas do MongoDB period muito lento para suportar análises complexas envolvendo dados de empregos, currículos, cursos e diferentes regiões geográficas, especialmente quando os padrões de consulta não eram definidos antecipadamente. Isso tornou as consultas e junções multidimensionais lentas e caras, impossibilitando o fornecimento do desempenho interativo que nossos usuários exigiam.
Por exemplo, um grande cliente farmacêutico perguntou se seria possível encontrar todos os cientistas de dados do mundo com experiência em ensaios clínicos e mais de 3 anos de experiência farmacêutica. Teria sido uma operação incrivelmente cara, mas é claro que o cliente buscava resultados imediatos.
Quando o cliente perguntou se poderíamos expandir a pesquisa para países que não falam inglês, tive que explicar que isso estava além dos recursos atuais do produto, pois tivemos problemas na normalização de dados em diferentes idiomas com o MongoDB.
Também havia limitações nos tamanhos de carga útil no MongoDB, bem como outras peculiaridades estranhas codificadas. Por exemplo, não poderíamos questionar a Grã-Bretanha como país.
Resumindo, tivemos desafios significativos com a latência de consulta e com a inserção de nossos dados no MongoDB, e sabíamos que precisávamos mudar para outra coisa.
Pilha de dados em tempo actual com Databricks e Rockset
Precisávamos de uma camada de armazenamento capaz de processar ML em larga escala para terabytes de novos dados por dia. Comparamos Snowflake e Databricks, escolhendo o último devido à compatibilidade do Databrick com mais opções de ferramentas e suporte para formatos de dados abertos. Usando Databricks, implantamos (abaixo) uma arquitetura lakehouse, armazenando e processando nossos dados por meio de três processos progressivos Lago Delta etapas. Dados rastreados e outros dados brutos chegam à nossa camada Bronze e, posteriormente, passam por pipelines Spark ETL e ML que refinam e enriquecem os dados para a camada Silver. Em seguida, criamos agregações de granulação grossa em múltiplas dimensões, como localização geográfica, função de trabalho e tempo, que são armazenadas na camada Gold.

Temos SLAs sobre latência de consulta na casa das centenas de milissegundos, mesmo quando os usuários fazem consultas complexas e multifacetadas. O Spark não foi criado para isso – essas consultas são tratadas como trabalhos de dados que levariam dezenas de segundos. Precisávamos de um mecanismo de análise em tempo actual, que criasse um superíndice de nossos dados para fornecer análises multidimensionais em um piscar de olhos.
Nós escolhemos Conjunto de foguetes para ser nosso novo banco de dados de atendimento voltado ao usuário. Rockset sincroniza continuamente com os dados da camada Gold e cria instantaneamente um índice desses dados. Tomando as agregações de granulação grossa na camada Gold, o Rockset consulta e une várias dimensões e executa as agregações de granularidade mais fina necessárias para atender às consultas do usuário. Isso nos permite servir: 1) pré-definidos Consultar Lambdas envio de feeds de dados regulares aos clientes; 2) pesquisas advert hoc de texto livre, como “Quais são todos os empregos remotos nos Estados Unidos?”
Análise em segundos e iterações mais rápidas
Após vários meses de desenvolvimento e testes, trocamos nosso banco de dados de Inteligência do Mercado de Trabalho do MongoDB para Rockset e Databricks. Com o Databricks, melhoramos nossa capacidade de lidar com grandes conjuntos de dados, bem como de executar com eficiência nossos modelos de ML e outros processamentos não urgentes. Enquanto isso, o Rockset nos permite oferecer suporte a consultas complexas em dados de grande escala e retornar respostas aos usuários em milissegundos com baixo custo computacional.
Por exemplo, nossos clientes podem pesquisar as 20 principais competências em qualquer país do mundo e obter resultados quase em tempo actual. Também podemos suportar um quantity muito maior de consultas de clientes, já que o Rockset sozinho pode lidar com milhões de consultas por dia, independentemente da complexidade da consulta, do número de consultas simultâneas ou de aumentos repentinos em outras partes do sistema (como dados de entrada em rajadas). alimenta).
Agora estamos atingindo facilmente todos os SLAs de nossos clientes, incluindo nossas garantias de tempo de consulta inferior a 300 milissegundos. Podemos fornecer as respostas em tempo actual que nossos clientes precisam e que nossos concorrentes não conseguem igualar. E com o suporte da API SQL para REST do Rockset, é fácil apresentar os resultados da consulta aos aplicativos.
O Rockset também acelera o tempo de desenvolvimento, impulsionando tanto nossas operações internas quanto nossas vendas externas. Anteriormente, levávamos de três a nove meses para construir uma prova de conceito para os clientes. Com recursos do Rockset, como Lambdas de consulta SQL para REST, agora podemos implantar painéis personalizados para o cliente em potencial horas após uma demonstração de vendas.
Chamamos isso de “dia zero do produto”. Não precisamos mais vender para nossos clientes em potencial, apenas pedimos que eles nos experimentem. Eles descobrirão que podem interagir com nossos dados sem atrasos perceptíveis. A entrega em nuvem sem servidor e de baixas operações da Rockset também facilita para nossos desenvolvedores a implantação de novos serviços para novos usuários e clientes em potencial.

Estamos planejando simplificar ainda mais nossa arquitetura de dados (acima) e, ao mesmo tempo, expandir nosso uso do Rockset em algumas outras áreas:
- consultas geoespaciais, para que os usuários possam pesquisar ampliando e diminuindo o zoom de um mapa;
- servindo dados para nossos modelos de ML.
Esses projetos provavelmente ocorreriam no próximo ano. Com Databricks e Rockset, já transformamos e construímos uma bela pilha. Mas ainda há muito mais espaço para crescer.