
Os melhores aplicativos da Genai combinam os dados mais frescos e pertinentes dos clientes com os modelos de idioma de primeira, mas colocar esses dados na janela de contexto do modelo não é fácil. É aí que o novo recurso Graphrag anunciado hoje pelo banco de dados de gráficos na memória, Memgraph entra em jogo.
Memágrafo Desenvolve um banco de dados de gráficos de memória que se destaca em casos de uso em tempo actual que são uma mistura de cargas de trabalho transacionais e analíticas, como detecção de fraude e planejamento da cadeia de suprimentos. Foi lançado como uma oferta de código aberto em 2016 por Dominik Tomicevic e Marcko Budiselić, que descobriram que os bancos de dados de gráficos tradicionais não podiam lidar com as demandas desse tipo específico de aplicação.
Bancos de dados de gráficos tradicionais, como Neo4jsão orientados para o lote e armazenam dados no disco. Isso funciona bem quando você deseja fazer uma ampla gama de perguntas gráficas sobre grandes quantidades de dados lentos, mas não funciona bem quando você precisa de respostas rápidas em conjuntos de dados mais rápidos, mas menores, diz Tomicevic.
“O problema começa se você tiver muitas gravações por segundo (centenas de milhares ou milhões por segundo)”, diz o CEO do Memgraph Bigdatawire. “O NEO4J não pode lidar com esse tipo de gravação por segundo, especialmente respondendo ao mesmo tempo às consultas e análises de leitura.”
A NEO4J oferece algoritmos e análises de gráficos de alto desempenho por meio de sua biblioteca de ciência de dados gráficos (GDS). No entanto, o GDS requer trabalhos essencialmente como um banco de dados separado, que não atende às necessidades em tempo actual.
Em vez de tentar ajustar os casos de uso analítico em um banco de dados de gráficos em lote, Tomicevic e Budiselić decidiram criar um banco de dados de gráfico a partir do zero que atende a esse tipo específico de carga de trabalho. O Memgraph armazena todos os dados na RAM, fornecendo não apenas dados rápidos de dados, mas também a capacidade de executar algoritmos de análise e ciência de dados durante toda a totalidade do gráfico.

Memagraph Cto Marcko Budiselić (à esquerda) e CEO Dominik Tomicevic
Essa abordagem traz trocas, é claro. O armazenamento de dados na RAM são pedidos de magnitude mais caros do que armazená -los no disco. Os clientes não poderão criar gráficos maciços no Memgraph, que é construído em uma arquitetura de expansão (uma arquitetura distribuída introduziria muita latência). Os bancos de dados típicos do MEMGRAPH têm algumas centenas de milhões de nós e bordas, enquanto alguns dos maiores têm bilhões de bilhões de um dígito. Os gráficos em neo4j podem ser muito maiores, medidos no trilhões de nóscom um limite teórico nos quadrilhões.
Mas, para certos tipos de cargas de trabalho de alto valor, o Memgraph fornece a mistura certa de recursos de ingestão e análise em tempo actual que fornecem valor ao cliente. Ele usa a linguagem gráfica de consulta Cypher de código aberto da NEO, o que significa que o Memgraph é uma substituição de queda, aponta Tomicevic.
Graphrag no Memgraph 3.0
Com o lançamento de hoje do Memgraph 3.0, a empresa está levando seu investimento em análise em tempo actual para o mundo da IA generativa. Ele está lançando um par de novos recursos com o Memgraph 3.0 que posicionam o banco de dados para ser mais útil para cargas de trabalho emergentes da Genai, como servir chatbots ou agentes de IA.
O primeiro novo recurso no Memgraph 3.0 é a adição de pesquisa vetorial. Ao armazenar dados gráficos como incorporação de vetor, os usuários poderão servir relacionamentos explícitos (conforme definido pelos nós e bordas gráficos) nas janelas de contexto dos modelos de idiomas para obter um resultado melhor como parte de um pipeline RAG ou Graphrag.
As janelas de contexto do modelo de idioma estão ficando muito grandes. Por exemplo, GoogleO modelo Gemini 2.0, que foi disponibilizado a todos na semana passada, agora pode aceitar 2 milhões de tokens em sua janela de contexto. Isso é muitos dados, equivalentes a cerca de 1,5 milhão de palavras, mas isso, por si só, pode não ser suficiente para garantir a precisão.
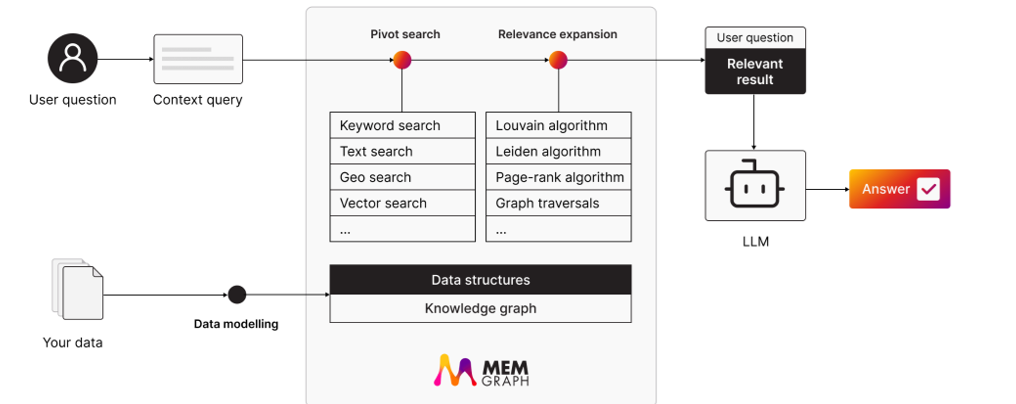
O Memgraph 3.0 suporta graphrag (imagem cortesia de MemAgraph)
“Mesmo se você tivesse isso, isso provavelmente seria um problema para escolher qual é a informação certa”, diz Tomicevic. “Podemos aproveitar alguns dos algoritmos de gráfico tradicionais com a detecção da comunidade para agrupar os dados em grupos que fazem sentido e, em seguida, você pode fazer resumo parcial em cada grupo”.
O Memgraph está fornecendo recursos de vetor básico com a versão 3.0. Se os clientes precisarem de recursos mais avançados, eles podem integrar o Memgraph com bancos de dados de vetores dedicados, como PineconeTomicevic diz.
O suporte do Graphrag no Memgraph também reduzirá a tendência de modelos de idiomas alucinar e fornecer respostas de maior qualidade em geral, diz ele.
“Há muitos problemas apenas na implantação de LLMs e treinamento e pré-treinamento e ajuste fino e outras coisas”, diz o CEO. “Os LLMs são terríveis na contabilidade, por exemplo. Eles também são terríveis em relacionamentos e pensamentos hierárquicos. Se você tem um gráfico e entende que há um problema hierárquico, pode pedir que eles usem o gráfico para quebrar a hierarquia e, em seguida, você pode criar uma resposta geral melhor do que apenas o LLM tradicional lhe daria. ”
Para obter mais informações sobre o apoio de Memgraph ao Graphrag, consulte Memgraph.com/docs/ai-ecosystem/graph-rag.![]()
Gráficos de linguagem pure
O Memgraph 3.0 também traz aprimoramentos ao GraphChat, uma interface de linguagem pure para o Cypher. Com esta versão, os clientes do Memgraph podem fazer uma pergunta gráfica em inglês simples, e o GraphChat o converterá em Cypher para execução no Memgraph. Isso terá o impacto de diminuir a barreira para acessar recursos sofisticados de ciência de dados de gráficos, diz Tomicevic.
“Os gráficos são muito poderosos. Eles podem fazer muitas coisas ”, diz ele. “(Com o GraphChat), eles se tornam mais ao alcance das pessoas que não têm um doutorado, se você quiser. Pode ser os desenvolvedores que estão desenvolvendo esses aplicativos e podem torná -los mais produtivos. ”
Memgraph também está apoiando modelos de Deepseeko desenvolvedor chinês que explodiu na cena da IA há apenas algumas semanas com um modelo de raciocínio comparável àqueles de Openai. A empresa também introduziu melhorias de desempenho e confiabilidade com a versão 3.0, além de atualizações nas bibliotecas Python e no pacote Docker.
Itens relacionados:
O futuro de Genai: como o Graphrag aprimora a precisão do LLM e pode ser melhor a tomada de decisões
O’Reilly e Cloudera anunciam finalistas inaugurais de dados do Strata Information Awards
Bancos de dados de gráficos em todos os lugares até 2020, diz Neo4J Chief