No AWS re:Inventar 2025, Amazon Internet Companies (AWS) anunciou armazenamento sem servidor para Amazon EMR Sem servidorum novo recurso que elimina a necessidade de configurar discos locais para cargas de trabalho do Apache Spark. Isso reduz os custos de processamento de dados em até 20%, ao mesmo tempo que elimina falhas de trabalho devido a restrições de capacidade de disco.
Com armazenamento sem servidor, Amazon EMR sem servidor lida automaticamente com operações de dados intermediárias, como embaralhamento, em seu nome. Você paga apenas pela computação e pela memória, sem custos de armazenamento. Ao dissociar o armazenamento da computação, o Spark pode liberar trabalhadores ociosos imediatamente, reduzindo custos durante todo o ciclo de vida do trabalho. A imagem a seguir mostra o armazenamento sem servidor para o anúncio EMR Serverless da palestra AWS re:Invent 2025:

O desafio: dimensionar o armazenamento em disco native
A execução de cargas de trabalho do Apache Spark requer o dimensionamento do armazenamento em disco native para operações aleatórias, onde o Spark redistribui dados entre executores durante junções, agregações e classificações. Isso exige a análise de históricos de trabalhos para estimar os requisitos de disco, o que leva a dois problemas comuns: o provisionamento excessivo desperdiça dinheiro com capacidade não utilizada e o provisionamento insuficiente causa falhas nos trabalhos quando o espaço em disco se esgota. A maioria dos clientes provisiona excessivamente o armazenamento native para garantir que os trabalhos sejam concluídos com sucesso na produção.
A distorção dos dados agrava ainda mais esta situação. Quando um executor lida com uma partição desproporcionalmente grande, esse executor leva muito mais tempo para ser concluído enquanto outros trabalhadores ficam ociosos. Se você não provisionou disco suficiente para esse executor distorcido, o trabalho falhará completamente, tornando a distorção dos dados uma das principais causas de falhas de trabalho do Spark. No entanto, o problema vai além do planejamento de capacidade. Como os dados embaralhados se acoplam firmemente aos discos locais, os executores do Spark fixam-se nos nós de trabalho mesmo quando os requisitos de computação diminuem entre os estágios do trabalho. Isso evita que o Spark libere trabalhadores e reduza, aumentando os custos de computação ao longo do ciclo de vida do trabalho. Quando um nó de trabalho falha, o Spark deve recalcular os dados embaralhados armazenados nesse nó, causando atrasos e uso ineficiente de recursos.
Como funciona
Armazenamento sem servidor para Amazon EMR O Serverless aborda esses desafios transferindo operações aleatórias de trabalhadores de computação individuais para uma camada de armazenamento elástica separada. Em vez de armazenar dados críticos em discos locais anexados aos executores Spark, o armazenamento sem servidor provisiona e dimensiona automaticamente o armazenamento remoto de alto desempenho à medida que seu trabalho é executado.
A arquitetura oferece vários benefícios importantes. Primeiro, a computação e o armazenamento são dimensionados de forma independente: o Spark pode adquirir e liberar trabalhadores conforme necessário em todos os estágios do trabalho, sem se preocupar em preservar os dados armazenados localmente. Em segundo lugar, os dados aleatórios são distribuídos uniformemente pela camada de armazenamento sem servidor, eliminando gargalos de distorção de dados que ocorrem quando alguns executores lidam com partições aleatórias desproporcionalmente grandes. Terceiro, se um nó de trabalho falhar, seu trabalho continuará processando sem atrasos ou novas execuções porque os dados são armazenados de forma confiável fora dos trabalhadores de computação individuais.
O armazenamento sem servidor é fornecido sem custo adicional e elimina o custo associado ao armazenamento native. Em vez de pagar por capacidade fixa de disco dimensionada para carga potencial máxima de E/S (capacidade que geralmente fica ociosa durante cargas de trabalho mais leves), você pode usar armazenamento sem servidor sem incorrer em custos de armazenamento. Você pode concentrar seu orçamento em recursos de computação que processam diretamente seus dados, e não no gerenciamento e no provisionamento excessivo de armazenamento em disco.
A inovação técnica traz três avanços
O armazenamento sem servidor apresenta três inovações fundamentais que resolvem os gargalos de embaralhamento do Spark: arquitetura de agregação multicamadas, rede desenvolvida para fins específicos e verdadeira dissociação entre armazenamento e computação. O mecanismo de embaralhamento do Apache Spark tem uma restrição central: cada mapeador grava independentemente a saída como arquivos pequenos, e cada redutor deve buscar dados de potencialmente milhares de trabalhadores. Num trabalho em grande escala com 10.000 mapeadores e 1.000 redutores, isso cria 10 milhões de trocas de dados individuais. O armazenamento sem servidor agrega de forma antecipada e inteligente: os mapeadores transmitem dados para uma camada de agregação que consolida os dados embaralhados na memória antes de se comprometerem com o armazenamento. Embora as operações individuais de gravação e busca aleatórias possam mostrar uma latência um pouco maior devido às viagens de ida e volta da rede em comparação com a E/S do disco native, o desempenho geral do trabalho melhora ao transformar milhões de pequenas operações de E/S em um número menor de operações grandes e sequenciais.
O Spark shuffle tradicional cria uma rede mesh onde cada trabalhador mantém conexões com potencialmente centenas de outros trabalhadores, gastando uma CPU significativa no gerenciamento de conexões em vez de no processamento de dados. Construímos uma pilha de rede personalizada onde cada mapeador abre uma única conexão persistente de chamada de procedimento remoto (RPC) para nossa camada agregadora, eliminando a complexidade da malha. Embora as operações de embaralhamento individuais possam mostrar uma latência um pouco maior devido às viagens de ida e volta da rede em comparação com a E/S do disco native, o desempenho geral do trabalho melhora através de uma melhor utilização de recursos e escalabilidade elástica. Os trabalhadores não executam mais um serviço aleatório – eles se concentram inteiramente no processamento de seus dados.
Os trabalhos tradicionais do Amazon EMR Serverless armazenam dados embaralhados em discos locais, acoplando o ciclo de vida dos dados ao ciclo de vida do trabalhador – trabalhadores ociosos não podem encerrar sem perder dados embaralhados. O armazenamento sem servidor os separa totalmente, armazenando dados aleatórios no armazenamento gerenciado pela AWS com identificadores opacos rastreados pelo driver. Os trabalhadores podem encerrar imediatamente após concluir as tarefas sem perda de dados, permitindo o escalonamento elástico. Em consultas em formato de funil, onde os estágios iniciais exigem um paralelismo massivo que se estreita à medida que os dados são agregados, estamos vendo uma redução de até 80% nos custos de computação em benchmarks, liberando trabalhadores ociosos instantaneamente. O diagrama a seguir ilustra a liberação instantânea do trabalhador em consultas em formato de funil.
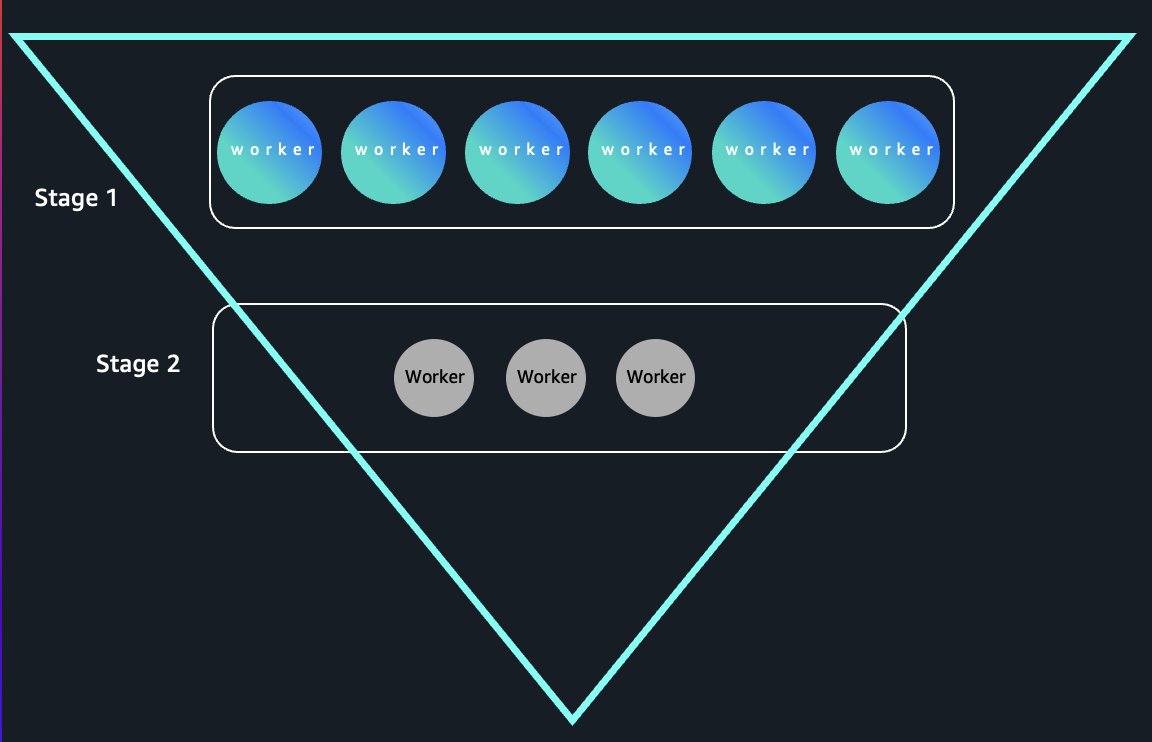
Nossa camada agregadora se integra diretamente com Gerenciamento de identidade e acesso da AWS (EU SOU), Formação do Lago AWSe sistemas de controle de acesso refinados, fornecendo isolamento de dados em nível de trabalho com controles de acesso que correspondem às permissões dos dados de origem.
Começando
O armazenamento sem servidor está disponível em vários Regiões da AWS. Para obter a lista atual de regiões suportadas, consulte o Guia do usuário do Amazon EMR.
Novos aplicativos
O armazenamento sem servidor pode ser habilitado para novos aplicativos a partir da versão 7.12 do Amazon EMR. Siga estas etapas:
- Crie um aplicativo Amazon EMR Serverless com o Amazon EMR 7.12 ou posterior:
- Envie seu trabalho do Spark:
Aplicativos existentes
Você pode habilitar o armazenamento sem servidor para aplicativos existentes no Amazon EMR 7.12 ou posterior atualizando as configurações do seu aplicativo.
Para ativar o armazenamento sem servidor usando Interface de linha de comando da AWS (AWS CLI), insira o seguinte comando:
Para ativar o armazenamento sem servidor usando Estúdio Amazon EMR UI, navegue até seu aplicativo no Amazon EMR Studio, acesse Configuraçãoe adicione a propriedade Spark spark.aws.serverlessStorage.enabled=true na classificação spark-defaults.
Configuração em nível de trabalho
Você também pode habilitar o armazenamento sem servidor para trabalhos específicos, mesmo quando não estiver habilitado no nível do aplicativo:
(Opcional) Desativando armazenamento sem servidor
Se preferir continuar usando discos locais, você pode desabilitar o armazenamento sem servidor omitindo a opção spark.aws.serverlessStorage.enabled configuração ou configurá-lo para false no nível do aplicativo ou do trabalho:
spark.aws.serverlessStorage.enabled=falsePara usar o provisionamento de disco native tradicional, configure o tipo e tamanho de disco apropriado para os trabalhadores do seu aplicativo.
Monitoramento e rastreamento de custos
Você pode monitorar o uso do embaralhamento elástico por meio de métricas padrão da UI do Spark e rastrear custos no nível do aplicativo em Explorador de custos da AWS e Relatórios de uso e custos da AWS. O serviço lida automaticamente com a otimização e o dimensionamento do desempenho, para que você não exact ajustar os parâmetros de configuração.
Quando usar armazenamento sem servidor
O armazenamento sem servidor oferece o maior valor para cargas de trabalho com operações de embaralhamento substanciais — normalmente trabalhos que embaralham mais de 10 GB de dados (e menos de 200 G por trabalho, a limitação no momento desta redação). Estes incluem:
- Processamento de dados em grande escala com agregações e junções pesadas
- Análises pesadas cargas de trabalho
- Algoritmos iterativos que acessam repetidamente os mesmos conjuntos de dados
Trabalhos com tamanhos aleatórios imprevisíveis se beneficiam particularmente bem porque o armazenamento sem servidor aumenta ou diminui automaticamente a capacidade com base na demanda em tempo actual. Para cargas de trabalho com atividade mínima ou duração muito curta (menos de 2 a 3 minutos), os benefícios podem ser limitados. Nestes casos, a sobrecarga do acesso remoto ao armazenamento pode superar as vantagens do dimensionamento elástico.
Segurança e ciclo de vida dos dados
Seus dados são armazenados em armazenamento sem servidor apenas enquanto o trabalho está em execução e são excluídos automaticamente quando o trabalho é concluído. Como os trabalhos em lote sem servidor do Amazon EMR podem ser executados por até 24 horas, seus dados não serão armazenados por mais que esse período máximo. O armazenamento sem servidor criptografa seus dados em trânsito entre o aplicativo Amazon EMR Serverless e a camada de armazenamento sem servidor e em repouso enquanto são armazenados temporariamente, usando chaves de criptografia gerenciadas pela AWS. O serviço usa um modelo de segurança baseado em IAM com isolamento de dados em nível de trabalho, o que significa que um trabalho não pode acessar os dados aleatórios de outro trabalho. O armazenamento sem servidor mantém os mesmos padrões de segurança do Amazon EMR Serverless, com controles de segurança de nível empresarial durante todo o ciclo de vida do processamento.
Conclusão
O armazenamento sem servidor representa uma mudança basic na forma como abordamos a infraestrutura de processamento de dados, eliminando a configuração guide, alinhando os custos ao uso actual e melhorando a confiabilidade para cargas de trabalho com uso intensivo de E/S. Ao transferir as operações aleatórias para um serviço gerenciado, os engenheiros de dados podem se concentrar na construção de análises em vez de no gerenciamento da infraestrutura de armazenamento.
Para saber mais sobre armazenamento sem servidor e começar, visite o Documentação sem servidor do Amazon EMR.