Neste artigo, você aprenderá como empacotar um modelo de aprendizado de máquina treinado por trás de uma API HTTP limpa e bem validada usando FastAPI, desde o treinamento até os testes locais e o fortalecimento básico da produção.
Os tópicos que cobriremos incluem:
- Treinar, salvar e carregar um pipeline scikit-learn para inferência
- Construindo um aplicativo FastAPI com validação de entrada estrita by way of Pydantic
- Expondo, testando e fortalecendo um endpoint de previsão com verificações de integridade
Vamos explorar essas técnicas.

O guia do profissional de aprendizado de máquina para implantação de modelo com FastAPI
Imagem do autor
Se você treinou um modelo de aprendizado de máquina, surge uma pergunta comum: “Como podemos realmente usá-lo?” É aqui que muitos profissionais de aprendizado de máquina ficam presos. Não porque a implantação seja difícil, mas porque muitas vezes é mal explicada. A implantação não consiste em fazer add de um .pkl arquivo e esperando que funcione. Significa simplesmente permitir que outro sistema envie dados para o seu modelo e receba as previsões de volta. A maneira mais fácil de fazer isso é colocar seu modelo atrás de uma API. API rápida torna esse processo simples. Ele conecta aprendizado de máquina e desenvolvimento de back-end de maneira limpa. É rápido, fornece documentação automática de API com IU arrogantevalida os dados de entrada para você e mantém o código fácil de ler e manter. Se você já usa Python, parece pure trabalhar com FastAPI.
Neste artigo, você aprenderá como implantar um modelo de aprendizado de máquina usando FastAPI passo a passo. Em explicit, você aprenderá:
- Como treinar, salvar e carregar um modelo de aprendizado de máquina
- Como construir um aplicativo FastAPI e definir entradas válidas
- Como criar e testar um endpoint de previsão localmente
- Como adicionar recursos básicos de produção, como verificações de integridade e dependências
Vamos começar!
Etapa 1: treinar e salvar o modelo
A primeira etapa é treinar seu modelo de aprendizado de máquina. Estou treinando um modelo para aprender como as diferentes características da casa influenciam o preço closing. Você pode usar qualquer modelo. Crie um arquivo chamado train_model.py:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | importar pandas como PD de aprender.modelo_linear importar Regressão Linear de aprender.gasoduto importar Gasoduto de aprender.pré-processamento importar Escalador padrão importar joblib # Dados de treinamento de amostra dados = PD.Quadro de dados({ “quartos”: (2, 3, 4, 5, 3, 4), “idade”: (20, 15, 10, 5, 12, 7), “distância”: (10, 8, 5, 3, 6, 4), “preço”: (100, 150, 200, 280, 180, 250) }) X = dados((“quartos”, “idade”, “distância”)) sim = dados(“preço”) # Pipeline = pré-processamento + modelo gasoduto = Gasoduto(( (“escalador”, Escalador padrão()), (“modelo”, Regressão Linear()) )) gasoduto.ajustar(X, sim) |
Após o treinamento, você deverá salvar o modelo.
#Salve todo o pipeline joblib.jogar fora(gasoduto, “house_price_model.joblib”) |
Agora, execute a seguinte linha no terminal:
Agora você tem um modelo treinado e um pipeline de pré-processamento armazenados com segurança.
Etapa 2: Criando um aplicativo FastAPI
Isso é mais fácil do que você pensa. Crie um arquivo chamado principal.py:
de fastapi importar API rápida de pydantico importar Modelo Base importar joblib aplicativo = API rápida(título=“API de previsão de preços de casas”) # Carrega o modelo uma vez na inicialização modelo = joblib.carregar(“house_price_model.joblib”) |
Seu modelo agora é:
- Carregado uma vez
- Guardado na memória
- Pronto para veicular previsões
Isso já é melhor do que a maioria das implantações para iniciantes.
Etapa 3: definir qual entrada seu modelo espera
É aqui que muitas implantações falham. Seu modelo não aceita “JSON”. Aceita números em uma estrutura específica. FastAPI usa Pydantic para impor isso de forma limpa.
Você deve estar se perguntando o que é Pydantic: Pidantico é uma biblioteca de validação de dados que FastAPI usa para garantir que a entrada que sua API recebe corresponda exatamente ao que seu modelo espera. Ele verifica automaticamente os tipos de dados, campos obrigatórios e formatos antes que a solicitação chegue ao seu modelo.
aula Entrada da casa(Modelo Base): quartos: interno idade: flutuador distância: flutuador |
Isso faz duas coisas para você:
- Valida os dados recebidos
- Documenta sua API automaticamente
Isso garante que não haja mais “por que meu modelo está travando?” surpresas.
Etapa 4: Criando o endpoint de previsão
Agora você precisa tornar seu modelo utilizável criando um endpoint de previsão.
@aplicativo.publicar(“/prever”) definição prever_preço(dados: Entrada da casa): características = (( dados.quartos, dados.idade, dados.distância ))
previsão = modelo.prever(características)
retornar { “preço_previsto”: redondo(previsão(0), 2) } |
Esse é o seu modelo implantado. Agora você pode enviar uma solicitação POST e receber as previsões de volta.
Etapa 5: executando sua API localmente
Execute este comando em seu terminal:
uvicórnio principal:aplicativo —recarregar |
Abra seu navegador e acesse:
http://127.0.0.1:8000/docs |
Você verá:
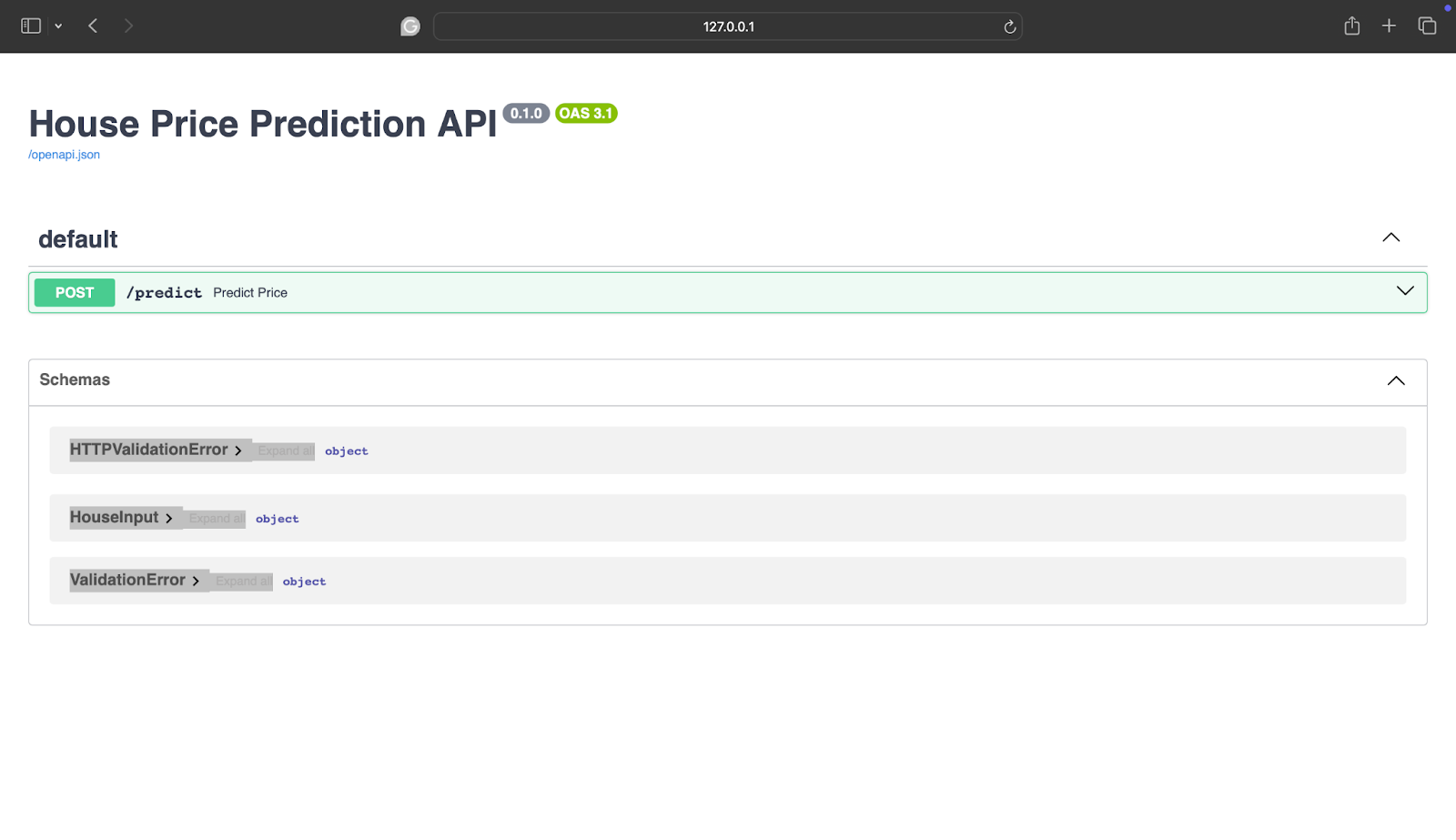
Se você está confuso sobre o que isso significa, basicamente está vendo:
- Documentos interativos da API
- Um formulário para testar seu modelo
- Validação em tempo actual
Etapa 6: teste com entrada actual
Para testar, clique na seta a seguir:
![]()
Depois disso, clique em Experimente.
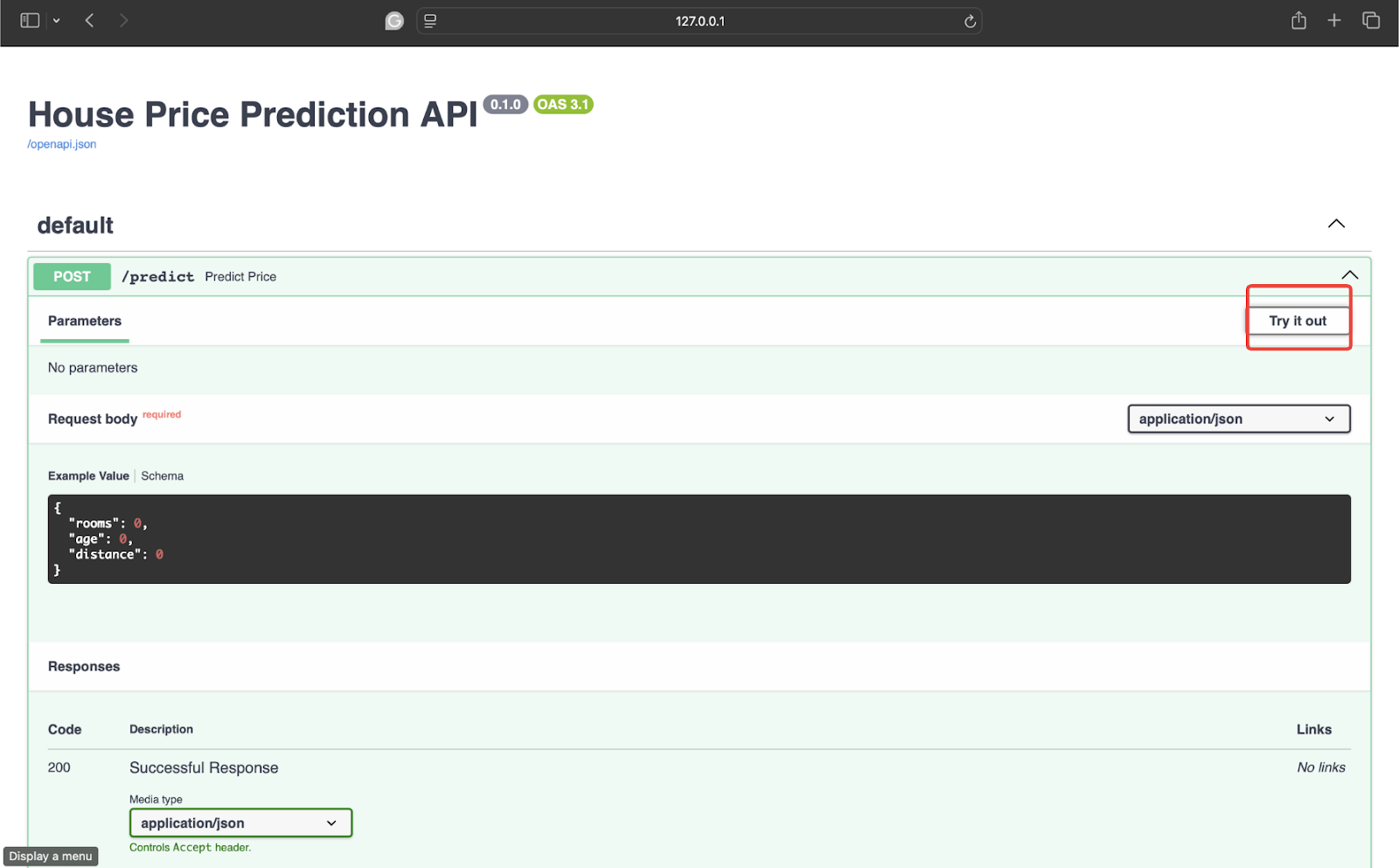
Agora teste com alguns dados. Estou usando os seguintes valores:
{ “quartos”: 4, “idade”: 8, “distância”: 5 } |
Agora clique em Executar para obter a resposta.

A resposta é:
{ “preço_previsto”: 246,67 } |
Seu modelo agora aceita dados reais, retorna previsões e está pronto para integração com aplicativos, websites ou outros serviços.
Etapa 7: adicionar uma verificação de integridade
Você não precisa do Kubernetes no primeiro dia, mas considere:
- Tratamento de erros (acontece entrada incorreta)
- Registrando previsões
- Versionando seus modelos (/v1/predict)
- Ponto closing de verificação de integridade
Por exemplo:
@aplicativo.pegar(“/saúde”) definição saúde(): retornar {“standing”: “OK”} |
Coisas simples como essa são mais importantes do que infraestruturas sofisticadas.
Etapa 8: adicionar um arquivo Requisitos.txt
Essa etapa parece pequena, mas é uma daquelas coisas que silenciosamente te salva horas depois. Seu aplicativo FastAPI pode funcionar perfeitamente em sua máquina, mas os ambientes de implantação não sabem quais bibliotecas você usou, a menos que você os informe. Isso é exatamente o que necessities.txt é para. É uma lista simples de dependências que seu projeto precisa para executar. Crie um arquivo chamado requisitos.txt e adicione:
fastapi uvicórnio scikit–aprender pandas joblib |
Agora, sempre que alguém precisar montar este projeto, basta executar a seguinte linha:
pip instalar –R requisitos.TXT |
Isso garante um bom funcionamento do projeto, sem pacotes perdidos. A estrutura geral do projeto é semelhante a:
projeto/ │ ├── modelo_de_trem.py ├── principal.py ├── house_price_model.joblib ├── requisitos.TXT |
Conclusão
Seu modelo não tem valor até que alguém possa usá-lo. FastAPI não transforma você em um engenheiro de back-end – ele simplesmente take away o atrito entre seu modelo e o mundo actual. E depois de implantar seu primeiro modelo, você para de pensar como “alguém que treina modelos” e começa a pensar como um profissional que fornece soluções. Por favor, não se esqueça de verificar o Documentação FastAPI.