Os oleodutos declarativos de Lakeflow agora estão geralmente disponíveis e o momento não diminuiu desde o estrado. Este put up reúne tudo o que foi aterrissado nas últimas semanas – então você está totalmente envolvido com o que está aqui, o que está por vir e como começar a usá -lo.
Dais 2025 em revisão: oleodutos declarativos do Lakeflow está aqui
Na Knowledge + AI Summit 2025, anunciamos que contribuímos com a nossa principal tecnologia de oleoduto declarativo para o projeto Apache Spark ™ como Spark Pipelines declarativos. Essa contribuição estende o modelo declarativo da Spark de consultas individuais a pipelines completos, permitindo que os desenvolvedores definem o que seus dutos deveriam fazer enquanto as faíscas lidam como fazê -lo. Já comprovado em milhares de cargas de trabalho de produção, agora é um padrão aberto para toda a comunidade Spark.

Também anunciamos a disponibilidade geral de fluxo de lagoSolução unificada dos Databricks para ingestão de dados, transformação e orquestração na plataforma de inteligência de dados. O marco da GA também marcou uma grande evolução para o desenvolvimento de pipeline. DLT agora é oleodutos declarativos do Lakeflowcom os mesmos benefícios centrais e compatibilidade com versões anteriores com os pipelines existentes. Também introduzimos o novo IDE para engenharia de dados (mostrado acima), construído a partir do solo para otimizar o desenvolvimento do pipeline com recursos como emparelhamento de trava de código, visualizações contextuais e autoria assistida por AI.
Finalmente, anunciamos Designer de Lakeflowuma experiência sem código para a criação de pipelines de dados. Torna o ETL acessível a mais usuários – sem comprometer a prontidão ou a governança da produção – gerando oleodutos reais do lago sob o capô. Visualização em breve.
Juntos, esses anúncios representam um novo capítulo em engenharia de dados – less complicated, mais escalável e mais aberto. E nas semanas desde o estrado, mantivemos o momento.
Desempenho mais inteligente, custos mais baixos para pipelines declarativos
Fizemos melhorias significativas de back-end para ajudar os oleodutos declarativos do Lakeflow a funcionarem mais rapidamente e econômicos. Em geral, os pipelines sem servidor agora oferecem melhor desempenho de preços, graças aos aprimoramentos do motor a fóton, enzima, autocaling e recursos avançados como AutoCDC e Expectativas de qualidade de dados.
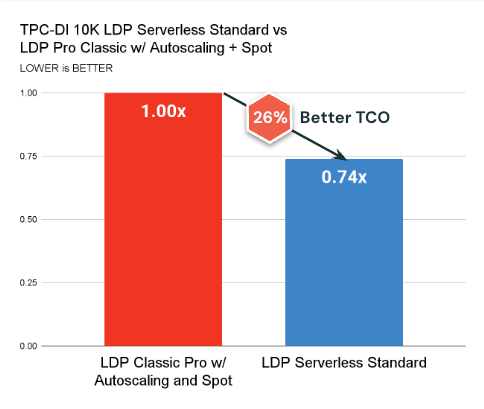
Aqui estão os principais tumores:
- Sem servidor Modo padrão agora está disponível e supera consistentemente a computação clássica em termos de custo (26% melhor TCO em média) e latência.
- Sem servidor Modo de desempenho Desbloqueia resultados ainda mais rápidos e é competitivo para SLAs apertados.
- AutoCDC Agora supera a mesclagem tradicional em muitas cargas de trabalho, ao mesmo tempo em que facilita a implementação de padrões SCD1 e SCD2 sem lógica complexa, especialmente quando combinada com essas otimizações.
Essas mudanças se baseiam em nosso compromisso contínuo de tornar os oleodutos declarativos do Lakeflow a opção mais eficiente para a produção ETL em escala.
O que mais há de novo em oleodutos declarativos
Desde a cúpula Knowledge + AI, entregamos uma série de atualizações que tornam os pipelines mais modulares, prontos para produção e mais fáceis de operar-sem exigir um código adicional de configuração ou cola.
Simplicidade operacional
Gerenciar a saúde da mesa agora é mais fácil e mais econômico:
- Otimização preditiva Agora gerencia a manutenção da tabela – como otimizar e o vácuo – para todos os novos e existentes pipelines de catálogo de unidades. Em vez de executar em um cronograma fixo, a manutenção agora se adapta aos padrões de carga de trabalho e structure de dados para otimizar o custo e o desempenho automaticamente. Isso significa:
- Menos tempo gasto sintonizando ou agendando manutenção manualmente
- Execução mais inteligente que evita o uso desnecessário de computação
- Melhores tamanhos de arquivo e agrupamento para um desempenho mais rápido de consulta
- Vetores de exclusão agora estão ativados por padrão para novas tabelas de streaming e vistas materializadas. Isso reduz reescritas desnecessárias, melhorando o desempenho e reduzindo os custos de computação, evitando reescritas completas de arquivos durante atualizações e exclusão. Se você tem requisitos rígidos de exclusão física (por exemplo, para GDPR), você pode Desativar vetores de exclusão ou Remova permanentemente os dados.
Oleodutos mais modulares e flexíveis
Novos recursos oferecem às equipes maior flexibilidade na forma como estruturam e gerenciam oleodutos, tudo sem nenhum reprocessamento de dados:
- Oleodutos declarativos de Lakeflow agora suporta a atualização de oleodutos existentes para tirar proveito de Publicação de tabelas para vários catálogos e esquemas. Anteriormente, essa flexibilidade estava disponível apenas ao criar um novo pipeline. Agora, você pode migrar um pipeline existente para esse modelo sem precisar reconstruí -lo do zero, permitindo arquiteturas de dados mais modulares ao longo do tempo.
- Você pode agora mover tabelas de streaming e vistas materializadas De um pipeline para outro usando um único comando SQL e uma pequena mudança de código para mover a definição da tabela. Isso facilita a divisão de pipelines grandes, consolida os menores ou adota diferentes cronogramas de atualização nas tabelas sem precisar recriar dados ou lógica. Para reatribuir uma tabela para um pipeline diferente, basta executar:
Depois de executar o comando e mover a definição da tabela da fonte para o pipeline de destino, o pipeline de destino assume as atualizações da tabela.
Novas tabelas de sistema para observabilidade do pipeline
Um novo pipeline Tabela do sistema Agora está em pré -visualização pública, oferecendo uma visão completa e consultável de todos os oleodutos em seu espaço de trabalho. Inclui metadados como Criador, Tags e eventos do ciclo de vida (como deleções ou alterações de configuração) e podem ser unidos com registros de cobrança para atribuição e relatório de custos. Isso é especialmente útil para equipes que gerenciam muitos dutos e que buscam rastrear custos em ambientes ou unidades de negócios.
Uma segunda tabela de sistema para atualizações de pipeline – cobrindo o histórico, o desempenho e as falhas da atualização – está planejado para o remaining deste verão.
Faça prática com o Lakeflow
 Novo no Lakeflow ou procurando aprofundar suas habilidades? Lançamos três cursos de treinamento gratuitos para ajudá-lo a começar:
Novo no Lakeflow ou procurando aprofundar suas habilidades? Lançamos três cursos de treinamento gratuitos para ajudá-lo a começar:
- Ingestão de dados com Lakeflow Join -Aprenda a ingerir dados nos bancos de dados do armazenamento em nuvem ou usando conectores totalmente gerenciados.
- Implantar cargas de trabalho com trabalhos de Lakeflow -Orquestrar cargas de trabalho de produção com observabilidade e automação integradas.
- Crie dutos de dados com oleodutos declarativos do Lakeflow -Vá de ponta a ponta com o desenvolvimento do pipeline, incluindo streaming, qualidade dos dados e publicação.
Todos os três cursos estão disponíveis agora sem nenhum custo em Databricks Academy.