Com o tempo de execução do Amazon EMR 7.10, Amazon emr Introduziu o EMR S3A, uma implementação aprimorada do conector do sistema de arquivos de código aberto S3A. Este conector aprimorado agora é definido automaticamente como o conector do sistema de arquivos S3 padrão para as opções de implantação da Amazon EMR, incluindo Amazon EMR no EC2Assim, Amazon EMR Sem servidorAssim, Amazon emr na Amazon Ekse Amazon Emr em postos avançados da AWSMantendo a compatibilidade completa da API com o Apache Spark de código aberto.
No tempo de execução do Amazon EMR 7.10 para o Apache Spark, o conector EMR S3A exibe desempenho comparável aos EMRFs para leitura de cargas de trabalho, conforme demonstrado pelo benchmark de consulta TPC-DS. Os ganhos de desempenho mais significativos do conector são evidentes nas operações de gravação, com uma melhoria de 7% nas substituições de partição estática e uma melhoria de 215% para substituição de partição dinâmica quando comparada aos EMRFs. Nesta postagem, mostramos as vantagens aprimoradas de leitura e desempenho do uso do Amazon EMR 7.10.0 Runtime para o Apache Spark com o EMR S3A em comparação com o EMRFS e o conector do sistema de arquivos de código aberto S3A.
Leia a comparação de desempenho da carga de trabalho
Para avaliar o desempenho de leitura, usamos um ambiente de teste com base na versão de execução do Amazon EMR 7.10.0 Working Spark 3.5.5 e Hadoop 3.4.1. Nossa infraestrutura de teste apresentou um Nuvem de computação elástica da Amazon (Amazon EC2) Cluster composto por nove instâncias R5D.4XLARGE. O nó primário possui 16 VCPU e 128 GB de memória, e os oito nós principais têm um complete de 128 VCPU e 1024 GB de memória.
A avaliação de desempenho foi realizada usando uma metodologia abrangente de teste projetada para fornecer resultados precisos e significativos. Para os dados de origem, escolhemos o fator de escala de 3 TB, que contém 17,7 bilhões de registros, aproximadamente 924 GB de dados compactados particionados no formato de arquivo parquet. As instruções de configuração e detalhes técnicos podem ser encontrados no Repositório do GitHub. Utilizamos o catálogo de dados na memória da Spark para armazenar metadados para bancos de dados e tabelas TPC-DS.
Para produzir uma comparação justa e precisa entre as implementações EMR S3A vs. EMRFs e de código aberto S3A, implementamos uma abordagem de teste trifásico:
- Fase 1: desempenho da linha de base:
- Estabeleceu uma linha de base usando a configuração padrão do Amazon EMR com o conector S3A da EMR
- Criou um ponto de referência para comparações subsequentes
- Fase 2: Análise EMRFS:
- Manteve o sistema de arquivos padrão como EMRFS
- Preservou outras definições de configuração
- Fase 3: Teste de código aberto S3A:
- Modificado apenas o
hadoop-aws.jarArquivo substituindo -o pelo código aberto Hadoop S3A 3.4.1 versão - Mantidos configurações idênticas em outros componentes
- Modificado apenas o
Este ambiente de teste controlado foi essential para nossa avaliação pelos seguintes motivos:
- Poderíamos isolar o impacto do desempenho especificamente para a implementação do conector S3A
- Removeu variáveis em potencial que poderiam distorcer os resultados
- Ele forneceu medições precisas de melhorias de desempenho entre a implementação S3A da Amazon e a alternativa de código aberto
Execução e resultados de teste
Durante o processo de teste, mantivemos a consistência nas condições e configurações de teste, garantindo que quaisquer diferenças de desempenho observadas possam ser atribuídas diretamente às variações de implementação do conector S3A. Um complete de 104 consultas SparkSQL foram executadas em 10 iterações sequencialmente, e uma média do tempo de execução de cada consulta nessas 10 iterações foi usada para comparação. A média do tempo de execução das 10 iterações no Amazon EMR 7.10 Runtime para o Apache Spark com EMR S3A foi de 1116,87 segundos, que é 1,08 vezes mais rápido que o código aberto S3A e comparável aos EMRFs. A figura a seguir ilustra o tempo de execução complete em segundos.

A tabela a seguir resume as métricas.
| Métrica | OSS S3A | EMRFS | EMR S3A |
| Tempo de execução média em segundos | 1208.26 | 1129.64 | 1116.87 |
| Média geométrica em consultas em segundos | 7.63 | 7.09 | 6.99 |
| Custo complete * | $ 6,53 | $ 6,40 | $ 6,15 |
*As estimativas de custo detalhadas são discutidas mais adiante nesta postagem.
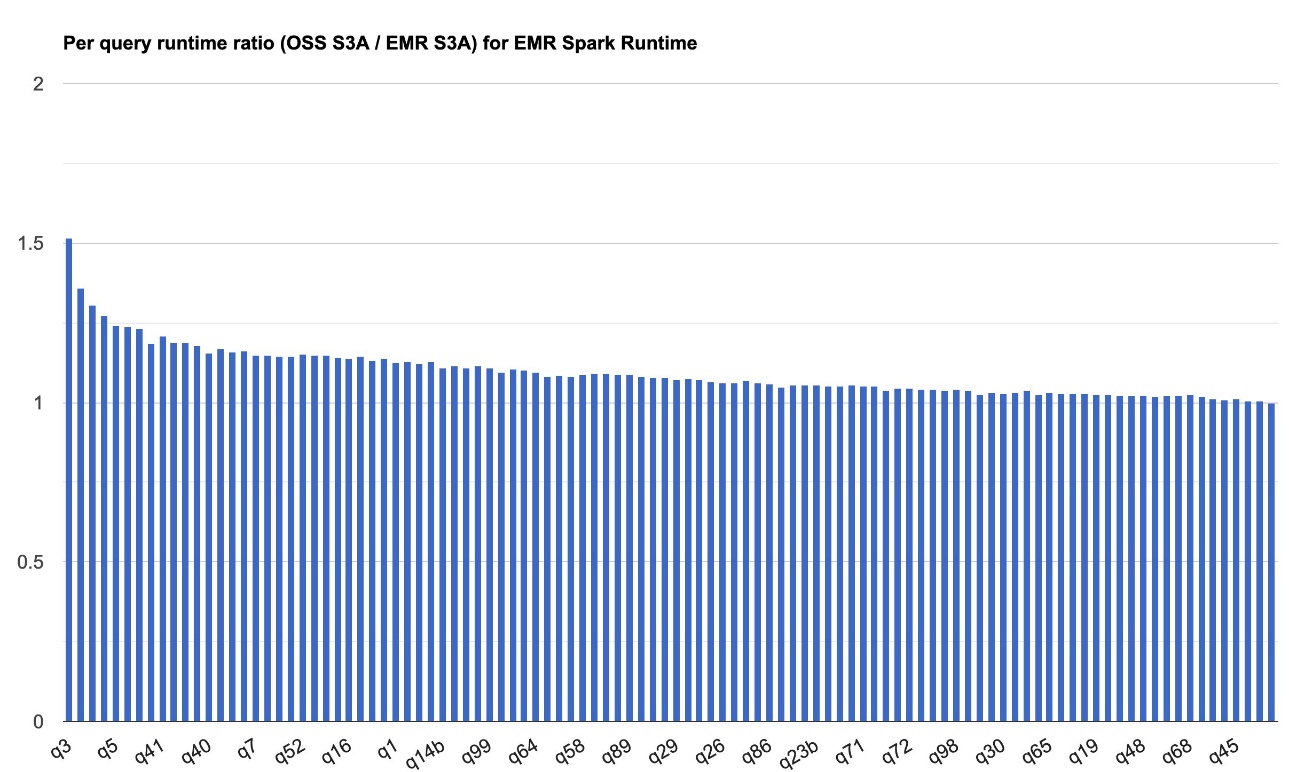
O gráfico a seguir demonstra a melhoria do desempenho por quadro do EMR S3A em relação ao código aberto S3A no Amazon EMR 7.10 Runtime para o Apache Spark. A extensão da aceleração varia de uma consulta para outra, com o mais rápido até 1,51 vezes mais rápido para o terceiro trimestre, com o Amazon EMR S3A superando o código aberto S3A. O eixo horizontal organiza as consultas de benchmark TPC-DS 3TB em ordem decrescente com base na melhoria do desempenho observada na Amazon EMR, e o eixo vertical mostra a magnitude dessa aceleração como uma proporção.
Leia a comparação de custos
Nossa referência em produções de tempo de execução complete e médias geométricas para medir o desempenho do tempo de execução do Spark. A métrica de custo pode nos fornecer informações adicionais. As estimativas de custo são calculadas usando as seguintes fórmulas. Eles levam em consideração o Amazon EC2, Amazon Elastic Block Retailer (Amazon EBS) e os custos da Amazon EMR, mas não incluem Amazon Easy Storage Service (Amazon S3) Obtenha e coloque custos.
- Custo do Amazon EC2 (inclua custo SSD) = número de instâncias * r5d.4xlarge Taxa horária * tempo de execução do trabalho em horas
- r5d.4xlarge Taxa horária = $ 1,152 por hora
- ROOT Amazon EBS Custo = Número de instâncias * Amazon EBS por GB-Hourly Taxa * Tamanho do quantity EBS raiz * Tempo de execução do trabalho em horas
- Amazon emr custo = número de instâncias * r5d.4xlarge Amazon EMR Custo * Time de execução em horas
- r5d.4xlarge Amazon emr custo = $ 0,27 por hora
- Custo complete = Amazon EC2 Custo + raiz Amazon EBS Custo + Amazon EMR Custo
A tabela a seguir resume esses custos.
| Métrica | EMRFS | EMR S3A | OSS S3A |
| Tempo de execução em horas | 0,5 | 0,48 | 0,51 |
| Número de instâncias do EC2 | 9 | 9 | 9 |
| Amazon EBS Tamanho | 0 GB | 0 GB | 0 GB |
| Custo da Amazon EC2 | US $ 5,18 | $ 4,98 | US $ 5,29 |
| Amazon EBS Custo | $ 0,00 | $ 0,00 | $ 0,00 |
| Custo da Amazon EMR | $ 1,22 | $ 1,17 | $ 1,24 |
| Custo complete | $ 6,40 | $ 6,15 | $ 6,53 |
| Economia de custos | Linha de base | O EMR S3A é 1,04 vezes melhor que o EMRFS | EMR S3A é 1,06 vezes melhor que o OSS S3A |
Escreva comparação de desempenho da carga de trabalho
Realizamos testes de referência para avaliar o desempenho de gravação do tempo de execução do Amazon EMR 7.10 para o Apache Spark.
Substituição estática de tabela/partição
Avaliamos a tabela estática/partição substituem o desempenho de gravação do sistema de arquivos diferente, executando o seguinte INSERT OVERWRITE Spark SQL Question. O SELECT * FROM vary(...) Cláusula gerou dados no momento da execução. Isso produziu aproximadamente 15 GB de dados em exatamente 100 arquivos parquet no Amazon S3.
O ambiente de teste foi configurado da seguinte maneira:
- Cluster EMR com EMR-7.10.0 Rótulo de liberação
- Instância única de M5D.2xlarge (grupo primário)
- Instâncias de oito M5d.2xlarge (grupo central)
- S3 Bucket na mesma região da AWS que o cluster EMR
- O
trial_idA propriedade usou um gerador UUID para evitar conflitos entre as execuções de teste
Resultados
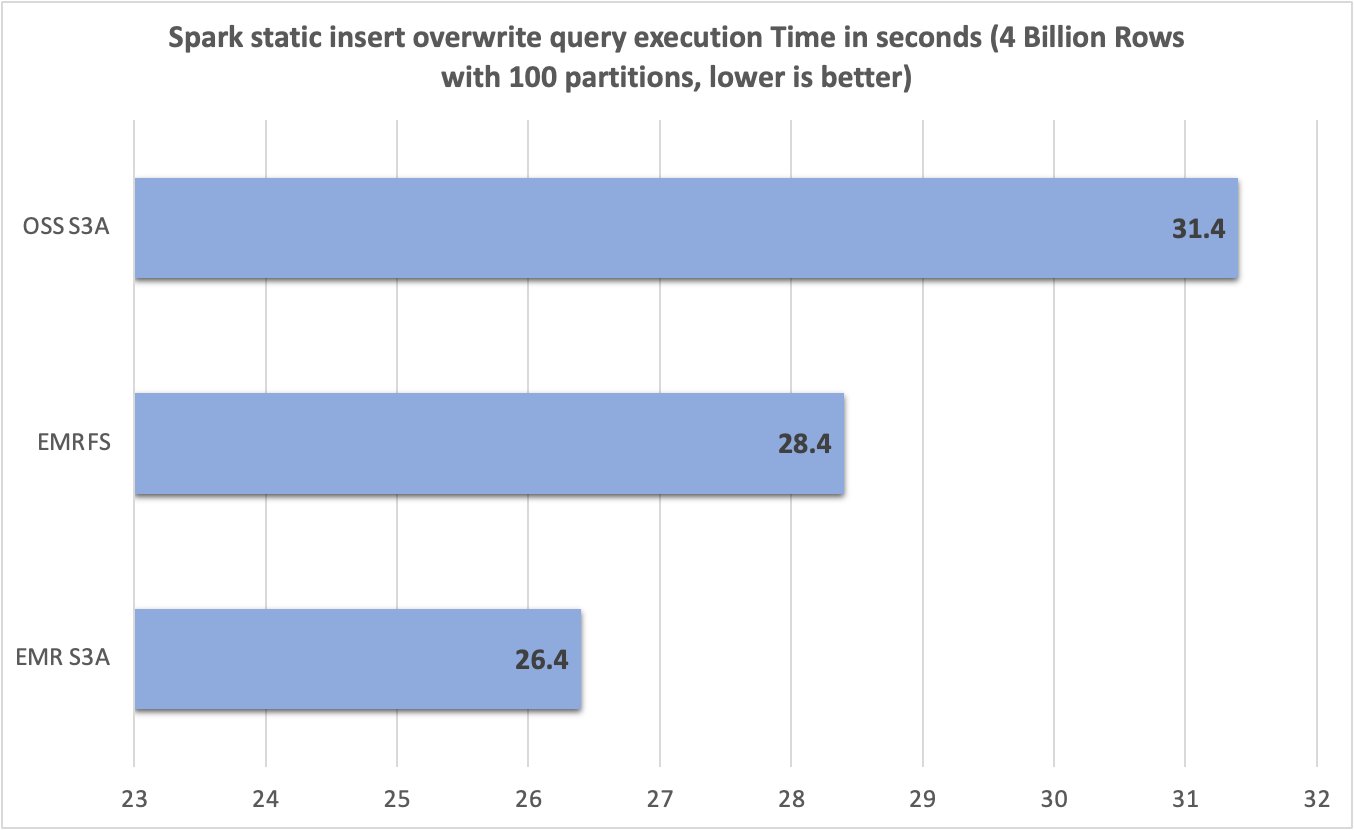
Depois de executar 10 ensaios para cada sistema de arquivos, capturamos e resumimos a consulta RunTimes no gráfico a seguir. Enquanto o EMR S3A teve uma média de apenas 26,4 segundos, os EMRFs e o código aberto S3A tiveram uma média de 28,4 segundos e 31,4 segundos – 1,07 vezes e 1,19 vezes a melhoria, respectivamente.
Substituição de partição dinâmica
Também avaliamos o desempenho de gravação executando o seguinte INSERT OVERWRITE Dynamic Partition Spark SQL Question, que se junta a TPC-DS 3TB Parquet Information da tabela web_sales e date_dim As tabelas, que inserem aproximadamente 2.100 partições, onde cada partição contém um arquivo parquet com um tamanho combinado de aproximadamente 31,2 GB na Amazon S3.
O ambiente de teste foi configurado da seguinte maneira:
- Cluster EMR com EMR-7.10.0 Rótulo de liberação
- Única instância R5D.4xlarge (grupo mestre)
- Cinco instâncias r5d.4xlarge (grupo central)
- Aproximadamente 2.100 partições com um arquivo parquet cada
- Tamanho combinado de aproximadamente 31,2 GB na Amazon S3
Resultados
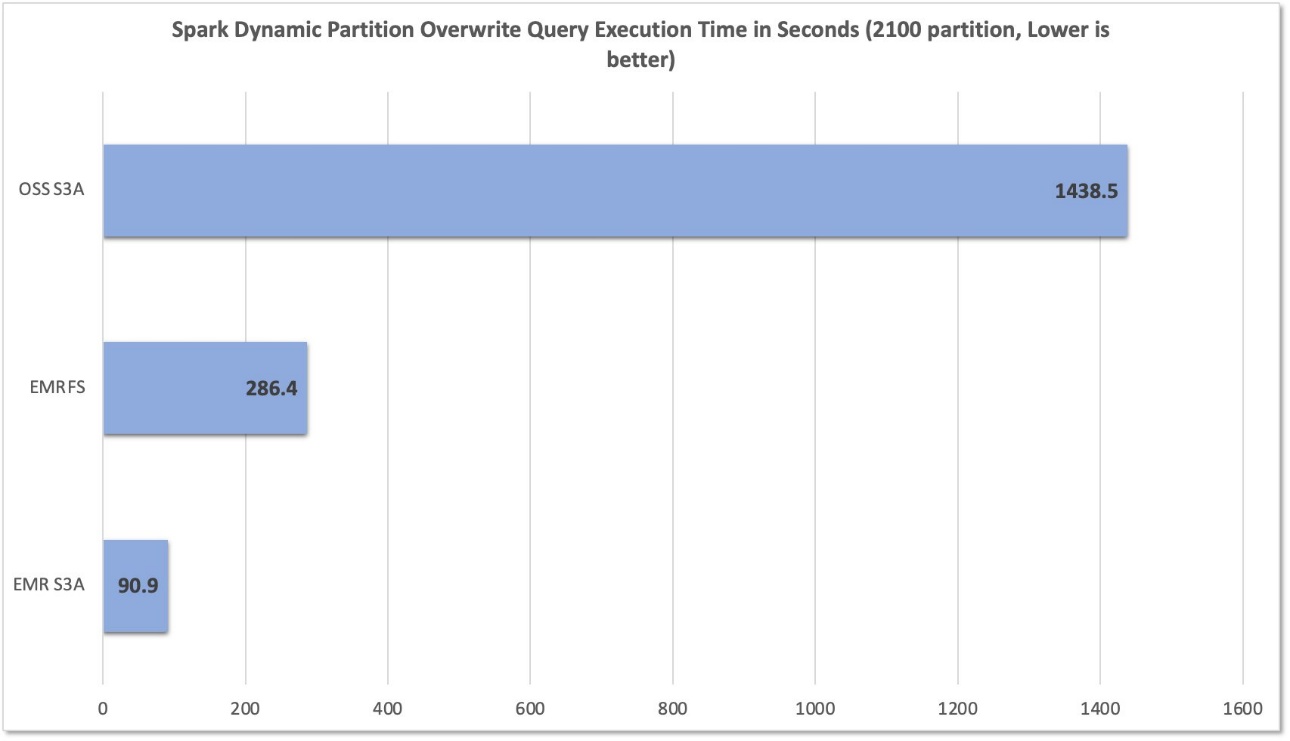
Depois de executar 10 ensaios para cada sistema de arquivos, capturamos e resumimos a consulta RunTimes no gráfico a seguir. Enquanto o EMR S3A teve uma média de apenas 90,9 segundos, os EMRFs e o código aberto S3A tiveram uma média de 286,4 segundos e 1.438,5 segundos – uma melhoria de 3,15 vezes e 15,82 vezes, respectivamente.
Resumo
A Amazon EMR aprimora consistentemente seu Apache Spark Runtime e o S3A Connector, fornecendo melhorias contínuas de desempenho que ajudam os clientes de huge information a executar cargas de trabalho de análise de análise de maneira mais econômica. Além dos ganhos de desempenho, a mudança estratégica para o S3A introduz vantagens críticas, incluindo padronização aprimorada, portabilidade cruzada aprimorada e suporte robusto orientado à comunidade-tudo ao manter ou superar os benchmarks de desempenho estabelecidos pela implementação anterior do EMRFS.
Recomendamos que você permaneça atualizado com o último lançamento do Amazon EMR para aproveitar os mais recentes benefícios de desempenho e recursos. Inscreva -se no AWS Large Information Weblog’s RSS Feed Para saber mais sobre o tempo de execução do Amazon EMR para o Apache Spark, as melhores práticas de configuração e os conselhos de ajuste.