O discurso sobre o nível do código gerado pela IA deve ser revisado geralmente parece muito binário. O vibe codifica (ou seja, deixando a IA gerar código sem olhar para o código) bom ou ruim? É claro que a resposta não é, porque “depende”.
Então, do que depende?
Quando estou usando a IA para codificar, encontro -me constantemente fazendo poucas avaliações de risco sobre confiar na IA, quanto confiar nele e quanto trabalho eu preciso colocar na verificação dos resultados. E quanto mais experiência eu tive o uso da IA, mais aprimoradas e intuitivas essas avaliações se tornam.
A avaliação de risco é tipicamente uma combinação de três fatores:
- Probabilidade
- Impacto
- Detectabilidade
Refletir sobre essas três dimensões me ajuda a decidir se devo buscar ou não a IA, se devo revisar o código ou não, e em que nível de detalhe faço essa revisão. Isso também me ajuda a pensar em mitigações que posso colocar no lugar quando quero aproveitar a velocidade da IA, mas reduzir o risco de fazer a coisa errada.
1. Probabilidade: qual a probabilidade de a IA errar?
A seguir, são apresentados alguns dos fatores que ajudam a determinar a dimensão de probabilidade.
Conheça sua ferramenta
O assistente de codificação de IA é uma função do modelo usado, a orquestração imediata que está acontecendo na ferramenta e o nível de integração que o assistente possui com a base de código e o ambiente de desenvolvimento. Como desenvolvedores, não temos todas as informações sobre o que está acontecendo sob o capô, especialmente quando estamos usando uma ferramenta proprietária. Portanto, a avaliação da qualidade da ferramenta é uma combinação de conhecer seus recursos proclamados e nossa própria experiência anterior com ela.
O caso de uso é amigável?
A pilha de tecnologia prevalece nos dados de treinamento? Qual é a complexidade da solução que você deseja que a IA crie? Qual é o tamanho do problema que a IA deve resolver?
Você também pode considerar mais geralmente se está trabalhando em um caso de uso que precisa de um alto nível de “correção” ou não. Por exemplo, construindo uma tela exatamente com base em um design ou na elaboração de uma tela de protótipo aproximado.
Esteja ciente do contexto disponível
A probabilidade não é apenas sobre o modelo e a ferramenta, também é sobre o disponível contexto. O contexto é o aviso que você fornece, além de todas as outras informações às quais o agente tem acesso através de chamadas de ferramentas and many others.
O assistente de IA tem o suficiente Acesso à sua base de código para tomar uma boa decisão? Está vendo os arquivos, a estrutura, a lógica do domínio? Caso contrário, an opportunity de gerar algo inútil aumenta.
Quão eficaz é a sua ferramenta Estratégia de pesquisa de código? Algumas ferramentas indexam a base de código inteira, algumas fazem em tempo actual
grep-Como pesquisas sobre os arquivos, alguns constroem um gráfico com a ajuda da AST (Sintaxe Summary Tree). Pode ajudar a saber qual estratégia sua ferramenta de escolha usa, embora, em última análise, apenas experimente com a ferramenta informe o quão bem essa estratégia realmente funciona.É o CodeBase Ai amigávelou seja, está estruturado de uma maneira que facilita a vida da IA? É modular, com limites e interfaces claros? Ou é uma grande bola de lama que enche a janela de contexto rapidamente?
É o existente CodeBase dando um bom exemplo? Ou é uma bagunça de hacks e anti-padrões? Se o último, an opportunity de a IA gerar mais do mesmo aumenta se você não disser explicitamente quais são os bons exemplos.
2. Impacto: Se a AI errar e você não perceber, quais são as consequências?
Esta consideração é principalmente sobre o Caso de uso. Você está trabalhando em um pico ou código de produção? Você está de acordo com o serviço em que está trabalhando? É crítico de negócios ou apenas ferramentas internas?
Algumas boas verificações de sanidade:
- Você enviaria isso se estivesse de plantão esta noite?
- Esse código tem um raio de alto impacto, por exemplo, é usado por muitos outros componentes ou consumidores?
3. Detectabilidade: Você notará quando a AI errar?
Isso é sobre Loops de suggestions. Você tem bons testes? Você está usando um idioma digitado? Sua pilha torna os fracassos óbvios? Você confia no rastreamento de alterações da ferramenta?
Também se resume à sua própria familiaridade com a base de código. Se você conhece bem a pilha de tecnologia e o caso de uso, é mais provável que você identifique algo suspeito.
Essa dimensão se inclina muito sobre as habilidades tradicionais de engenharia: cobertura de teste, conhecimento do sistema, práticas de revisão de código. E isso influencia o quão confiante você pode estar mesmo quando a IA faz a mudança para você.
Uma combinação de habilidades tradicionais e novas
Você já deve ter notado que muitas dessas questões de avaliação exigem habilidades de engenharia “tradicionais”, outras pessoas

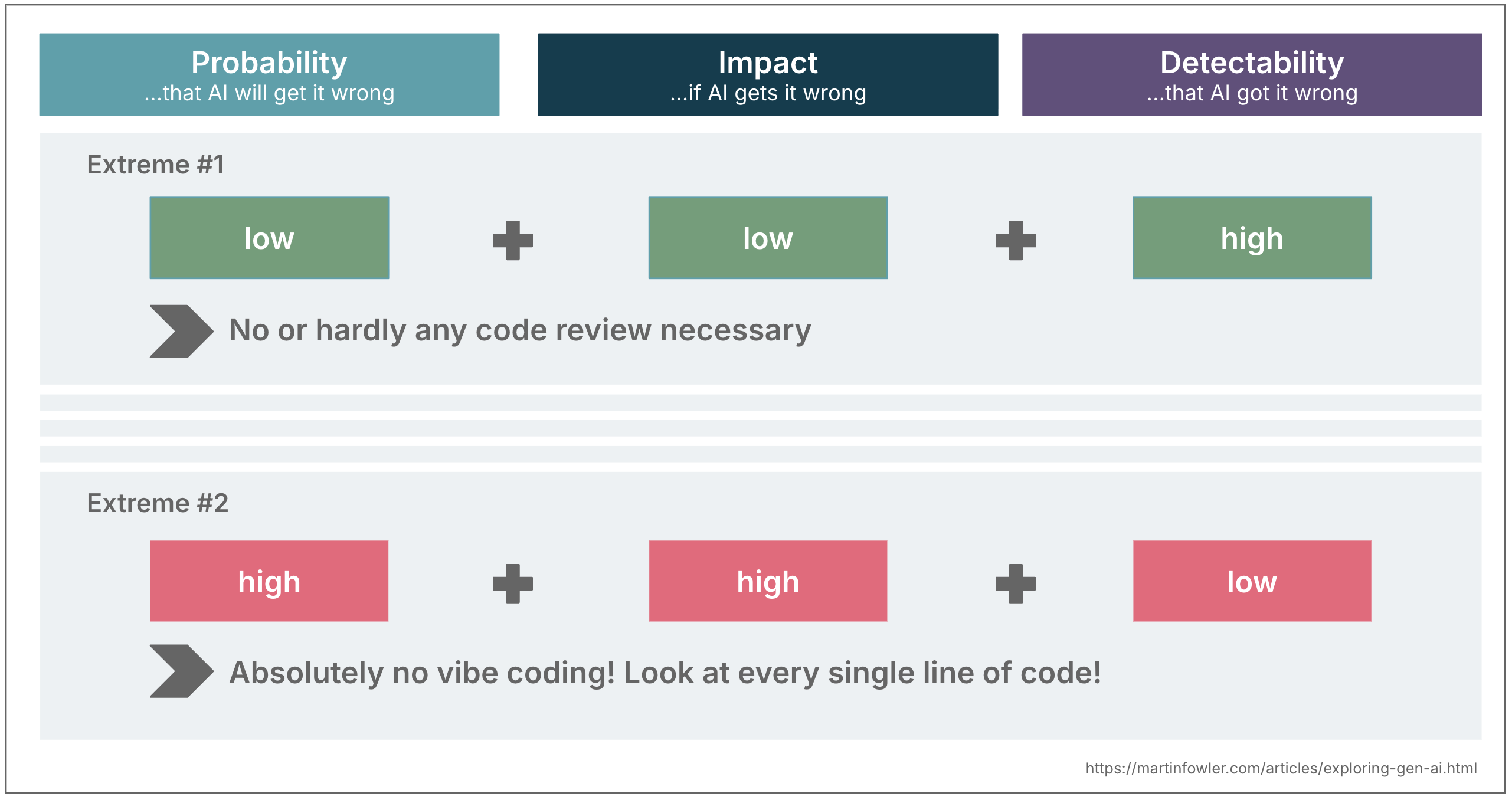
Combinando os três: uma escala deslizante de esforço de revisão
Quando você combina essas três dimensões, elas podem orientar seu nível de supervisão. Vamos tomar os extremos como exemplo para ilustrar essa ideia:
- Baixa probabilidade + baixo impacto + alta detectabilidade A codificação da vibração está bem! Enquanto as coisas funcionarem e eu atingir meu objetivo, não reviso o código.
- Alta probabilidade + alto impacto + baixa detectabilidade O alto nível de revisão é aconselhável. Suponha que a IA possa estar errada e cubra para isso.
A maioria das situações pousa em algum lugar, é claro.
Exemplo: Engenharia Reversa Legada
Recentemente, trabalhamos em uma migração herdada para um cliente em que a primeira etapa foi criar uma descrição detalhada da funcionalidade existente com a ajuda da IA.
Probabilidade de obter descrições erradas period médio:
Ferramenta: O modelo que tínhamos que usar muitas vezes não seguiu bem as instruções
Contexto disponível: Não tivemos acesso a todo o código, o código de again -end não estava disponível.
Mitigações: Executamos instruções várias vezes para identificar a variação nos resultados e aumentamos nosso nível de confiança analisando o binário de again -end descompilado.
Impacto de obter descrições erradas period médio
Caso de uso comercial: Por um lado, o sistema foi usado por milhares de parceiros de negócios externos desta organização; portanto, errar a reconstrução representava um risco comercial para reputação e receita.
Complexidade: Por outro lado, a complexidade do aplicativo period relativamente baixa, por isso esperávamos que fosse bastante fácil corrigir erros.
Mitigações planejadas: Um lançamento escalonado do novo aplicativo.
Detectabilidade de obter as descrições erradas period médio
Rede de segurança: Não havia nenhuma suíte de teste existente que pudesse ser cruzada
Disponibilidade das PMEs: Planejamos trazer PMEs para revisão e criar testes de comparação de paridade de recursos.
Sem uma avaliação estruturada como essa, teria sido fácil sub-revisão ou reivindicar demais. Em vez disso, calibramos nossa abordagem e planejamos mitigações.
Pensamento fechado
Esse tipo de avaliação de micro risco se torna uma segunda natureza. Quanto mais você usa a IA, mais você cria intuição para essas perguntas. Você começa a sentir quais mudanças podem ser confiáveis e quais precisam de uma inspeção mais detalhada.
O objetivo não é desacelerar -se com listas de verificação, mas aumentar os hábitos intuitivos que ajudam a navegar na linha entre alavancar as capacidades da IA e reduzir o risco de suas desvantagens.