Introdução
O problema de empacotamento de bin é um desafio clássico de otimização que tem implicações de longo alcance para organizações empresariais em todos os setores. Em sua essência, o problema se concentra em encontrar a maneira mais eficiente de empacotar um conjunto de objetos em um número finito de contêineres ou “bins”, com o objetivo de minimizar o desperdício de espaço.
Esse desafio é generalizado em aplicações do mundo actual, desde a otimização de remessas e logística até a alocação eficiente de recursos em information facilities e ambientes de computação em nuvem. Com organizações frequentemente lidando com grandes números de itens e contêineres, encontrar soluções de embalagem ideais pode levar a economias significativas de custos e eficiências operacionais.
Para um fabricante líder de equipamentos industriais de US$ 10 bilhões, a embalagem de bin é parte integrante de sua cadeia de suprimentos. É comum que essa empresa envie contêineres para fornecedores para encher com peças compradas que são então usadas no processo de fabricação de equipamentos pesados e veículos. Com a crescente complexidade das cadeias de suprimentos e metas de produção variáveis, a equipe de engenharia de embalagens precisava garantir que as linhas de montagem tivessem o número certo de peças disponíveis, ao mesmo tempo em que usavam o espaço de forma eficiente.
Por exemplo, uma linha de montagem precisa de parafusos de aço suficientes à mão para que a produção nunca diminua, mas é um desperdício de espaço no chão de fábrica ter um contêiner de transporte cheio deles quando apenas algumas dezenas são necessárias por dia. O primeiro passo para resolver esse problema é o empacotamento em bin, ou modelagem de como milhares de peças se encaixam em todos os contêineres possíveis, para que os engenheiros possam automatizar o processo de seleção de contêineres para melhorar a produtividade.
| Desafio ❗Espaço desperdiçado em recipientes de embalagem ❗Carregamento excessivo de caminhões e pegada de carbono | Objetivo ✅ Reduce o espaço vazio no recipiente de embalagem ✅ Maximizar a capacidade de carga do caminhão para reduzir a pegada de carbono |
|---|---|
 |  |
Desafios técnicos
Embora o problema de empacotamento de lixo tenha sido amplamente estudado em ambientes acadêmicos, simulá-lo e resolvê-lo de forma eficiente em conjuntos de dados complexos do mundo actual e em escala continua sendo um desafio para muitas organizações.
Em certo sentido, esse problema é simples o suficiente para qualquer um entender: colocar coisas em uma caixa até que esteja cheia. Mas, como acontece com a maioria dos problemas de huge information, surgem desafios por causa da grande escala dos cálculos a serem realizados. Para a simulação de empacotamento de bin deste cliente da Databricks, podemos usar um modelo psychological simples para a tarefa de otimização. Usando pseudocódigo:
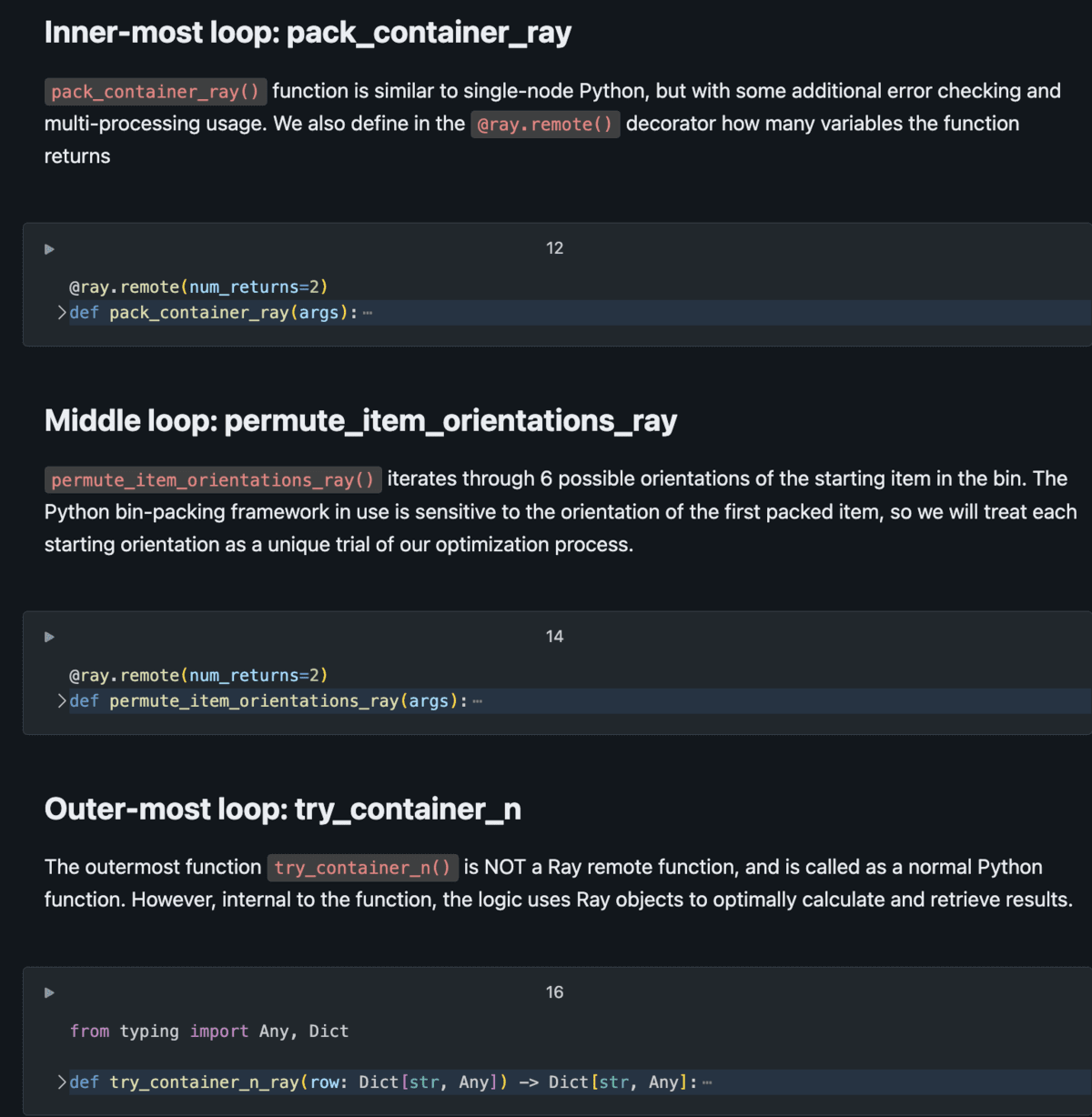
For (i in objects): The method wants to run for each merchandise in stock (~1,000’s)
↳ For (c in containers): Strive the match for each sort of container (~10’s)
↳ For (o in orientations): The beginning orientations of the first merchandise should every be modeled (==6)
↳ Pack_container Lastly, attempt filling a container with objects with a beginning orientationE se executássemos esse processo de loop sequencialmente usando Python de nó único? Se tivermos milhões de iterações (por exemplo, 20.000 itens x 20 contêineres x 6 orientações iniciais = 2,4 milhões de combinações), isso poderia levar centenas de horas para ser computado (por exemplo, 2,4 milhões de combinações x 1 segundo cada / 3.600 segundos por hora = ~660 horas = 27 dias). Esperar quase um mês por esses resultados, que são eles próprios uma entrada para uma etapa de modelagem posterior, é insustentável: precisamos criar uma maneira mais eficiente de computar em vez de um processo serial/sequencial.
Computação científica com Ray
Como uma plataforma de computação, a Databricks sempre forneceu suporte para esses casos de uso de computação científica, mas escalá-los representa um desafio: a maioria das bibliotecas de otimização e simulação são escritas assumindo um ambiente de processamento de nó único, e escalá-las com o Spark requer experiência com ferramentas como Pandas UDFs.
Com Ray’s disponibilidade geral no Databricks no início de 2024, os clientes terão uma nova ferramenta em sua caixa de ferramentas de computação científica para dimensionar problemas complexos de otimização. Ao mesmo tempo em que oferece suporte a recursos avançados de IA, como aprendizado por reforço e ML distribuído, este weblog se concentra em Núcleo de Raios para aprimorar fluxos de trabalho Python personalizados que exigem aninhamento, orquestração complexa e comunicação entre tarefas.
Modelando um problema de empacotamento de bin
Para usar efetivamente o Ray para escalar a computação científica, o problema deve ser logicamente paralelizável. Ou seja, se você puder modelar um problema como uma série de simulações ou testes simultâneos para executar, o Ray pode ajudar a escalá-lo. O empacotamento de bin é uma ótima opção para isso, pois é possível testar itens diferentes em contêineres diferentes em orientações diferentes, tudo ao mesmo tempo. Com o Ray, esse problema de empacotamento de bin pode ser modelado como um conjunto de funções remotas aninhadas, permitindo que milhares de testes simultâneos sejam executados simultaneamente, com o grau de paralelismo limitado pelo número de núcleos em um cluster.
O diagrama abaixo demonstra a configuração básica deste problema de modelagem.

O script Python consiste em tarefas aninhadas, onde tarefas externas chamam as tarefas internas várias vezes por iteração. Usando tarefas remotas (em vez de funções Python normais), temos a capacidade de distribuir massivamente essas tarefas pelo cluster com o Ray Core gerenciando o gráfico de execução e retornando resultados de forma eficiente. Veja o Databricks Answer Accelerator computação-científica-raio-sobre-faísca para detalhes completos de implementação.
Desempenho e Resultados
Com as técnicas descritas neste weblog e demonstradas no repositório Github associadoeste cliente conseguiu:
- Reduza o tempo de seleção de contêineres: A adoção do algoritmo de empacotamento de contêineres 3D representa um avanço significativo, oferecendo uma solução que não é apenas mais precisa, mas também consideravelmente mais rápida, reduzindo o tempo necessário para a seleção de contêineres em um fator de 40x em comparação aos processos legados.
- Escale o processo linearmente: com Ray, o tempo para terminar o processo de modelagem pode ser escalado linearmente com o número de núcleos em nosso cluster. Tomando o exemplo com 2,4 milhões de combinações do topo (que levariam 660 horas para serem concluídas em um único thread): se quisermos que o processo seja executado durante a noite em 12 horas, precisamos de: 2,4M / (12hr x 3600seg) = 56 núcleos; para concluir em 3 horas, precisaríamos de 220 núcleos. No Databricks, isso é facilmente controlado por meio de uma configuração de cluster.
- Reduza significativamente a complexidade do código: Ray simplifica a complexidade do código, oferecendo uma alternativa mais intuitiva à tarefa de otimização authentic construída com as bibliotecas de multiprocessamento e threading do Python. A implementação anterior exigia conhecimento intrincado dessas bibliotecas devido às estruturas lógicas aninhadas. Em contraste, a abordagem de Ray simplifica a base de código, tornando-a mais acessível aos membros da equipe de dados. O código resultante não é apenas mais fácil de compreender, mas também se alinha mais de perto com as práticas idiomáticas do Python, aprimorando a manutenibilidade e a eficiência geral.
Extensibilidade para Computação Científica
A combinação de automação, processamento em lote e seleção otimizada de contêineres levou a melhorias mensuráveis para este fabricante industrial, incluindo uma redução significativa nos custos de envio e embalagem e um aumento drástico na eficiência do processo. Com o problema de embalagem de bin resolvido, os membros da equipe de dados estão migrando para outros domínios da computação científica para seus negócios, incluindo desafios focados em otimização e programação linear. Os recursos fornecidos pela plataforma Databricks Lakehouse oferecem uma oportunidade não apenas de modelar novos problemas de negócios pela primeira vez, mas também de melhorar drasticamente as técnicas de computação científica legadas que estão em uso há anos.
Em conjunto com o Spark, o padrão de fato para tarefas paralelas de dados, o Ray pode ajudar a tornar qualquer problema “lógico-paralelo” mais eficiente. Processos de modelagem que são puramente dependentes da quantidade de computação disponível são uma ferramenta poderosa para empresas criarem negócios orientados a dados.
Veja o Acelerador de Soluções Databricks computação-científica-raio-sobre-faísca.