Toda semana, novos modelos são lançados, juntamente com dezenas de benchmarks. Mas o que isso significa para um profissional decidindo qual modelo usar? Como eles devem abordar a avaliação da qualidade de um modelo recém -lançado? E como os recursos comparados como o raciocínio se traduzem em valor do mundo actual?
Neste put up, avaliaremos o recém -lançado NVIDIA LLAMA NEMOTRON SUPER 49B 1.5 modelo. Nós usamos Syftrnossa generativa estrutura de exploração e avaliação de fluxo de trabalho de IA, para fundamentar a análise em um problema de negócios actual e explorar as compensações de uma análise multi-objetiva.
Depois de examinar mais de mil fluxos de trabalho, oferecemos orientações acionáveis sobre os casos de uso em que o modelo brilha.
O número de parâmetros contam, mas não são tudo
Não deve surpreender que a contagem de parâmetros gera grande parte do custo de servir LLMs. Os pesos precisam ser carregados na memória e matrizes de valor-chave (KV) em cache. Os modelos maiores geralmente têm um desempenho melhor – os modelos de fronteira são quase sempre enormes. Os avanços da GPU foram fundamentais para a ascensão da IA, permitindo esses modelos cada vez mais grandes.
Mas a escala sozinha não garante desempenho.
As gerações mais recentes de modelos geralmente superam seus antecessores maiores, mesmo na mesma contagem de parâmetros. O Nemotron Modelos da NVIDIA são um bom exemplo. Os modelos se baseiam nos modelos abertos existentes, na poda parâmetros desnecessários e destilando novos recursos.
Isso significa que um modelo de Nemotron menor pode superar seu maior antecessor em várias dimensões: inferência mais rápida, menor uso da memória e raciocínio mais forte.
Queríamos quantificar essas compensações – especialmente contra alguns dos maiores modelos da geração atual.
Quão mais preciso? Quão mais eficiente? Então, nós os carregamos em nosso cluster e começamos a trabalhar.
Como avaliamos a precisão e o custo
Etapa 1: Identifique o problema
Com os modelos em mãos, precisávamos de um desafio no mundo actual. Um que testa o raciocínio, a compreensão e o desempenho dentro de um fluxo de IA agêntico.
Think about um analista financeiro júnior tentando aumentar uma empresa. Eles devem ser capazes de responder a perguntas como: “A Boeing tem um perfil de margem bruta de melhoria a partir do EF2022?”
Mas eles também precisam explicar a relevância dessa métrica: “Se a margem bruta não for uma métrica útil, explique o porquê”.
Para testar nossos modelos, atribuiremos a tarefa de sintetizar dados entregues através de um fluxo de IA agêntico e, em seguida, medirá sua capacidade de fornecer uma resposta precisa eficiente.
Para responder aos dois tipos de perguntas corretamente, os modelos precisam:
- Puxe dados de vários documentos financeiros (como relatórios anuais e trimestrais)
- Examine e interprete números ao longo dos períodos
- Sintetize uma explicação fundamentada no contexto
A referência do FinanceBench foi projetada para exatamente esse tipo de tarefa. Ele combina registros com perguntas e respostas validadas por especialistas, tornando-o um forte proxy para fluxos de trabalho corporativos reais. Esse é o teste que usamos.
Etapa 2: modelos para fluxos de trabalho
Para testar em um contexto como esse, você precisa construir e entender o fluxo de trabalho completo – não apenas o immediate – para que você possa alimentar o contexto certo no modelo.
E você tem que fazer isso toda vez Você avalia um novo par de fluxo de trabalho modelo.
Com Syftrsomos capazes de executar centenas de fluxos de trabalho em diferentes modelos, surgem rapidamente trocas. O resultado é um conjunto de fluxos de pareto-ideais como o mostrado abaixo.

No canto inferior esquerdo, você verá pipelines simples usando outro modelo como o LLM de sintetização. Estes são baratos de correr, mas sua precisão é ruim.
No canto superior direito, são os mais precisos – mas mais caros, pois eles normalmente dependem de estratégias agênticas que quebram a questão, fazem várias chamadas de LLM e analisam cada pedaço de forma independente. É por isso que o raciocínio requer computação e otimizações eficientes para manter os custos de inferência sob controle.
O Nemotron aparece fortemente aqui, mantendo -o na fronteira de Pareto restante.
Etapa 3: Dive Deep
Para entender melhor o desempenho do modelo, agrupamos os fluxos de trabalho pelo LLM usados em cada etapa e plotamos a fronteira de Pareto para cada um.
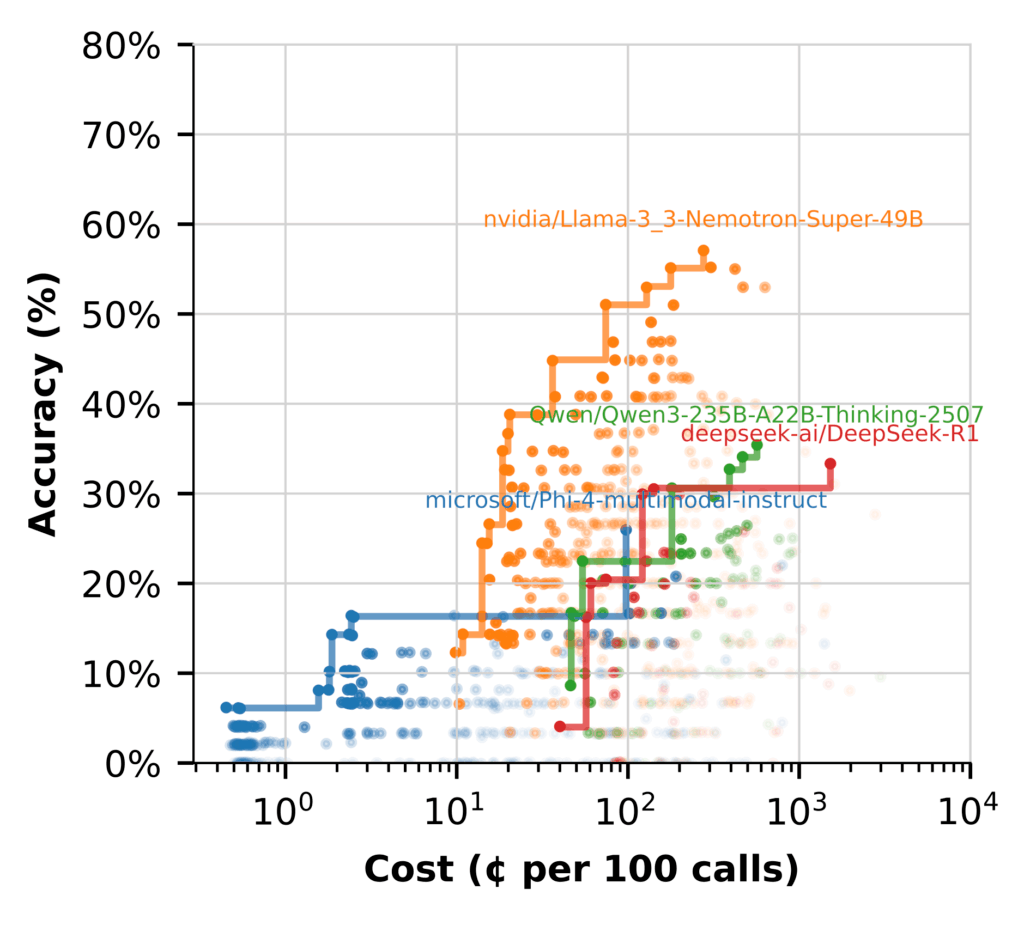
A lacuna de desempenho é clara. A maioria dos modelos luta para chegar a qualquer lugar perto do desempenho de Nemotron. Alguns têm problemas para gerar respostas razoáveis sem engenharia de contexto pesado. Mesmo assim, permanece menos preciso e mais caro que os modelos maiores.
Mas quando mudamos para usar o LLM para (hipotéticos documentos de documentos) Hyde, a história muda. (Os fluxos marcados N/A não incluem hyde.)
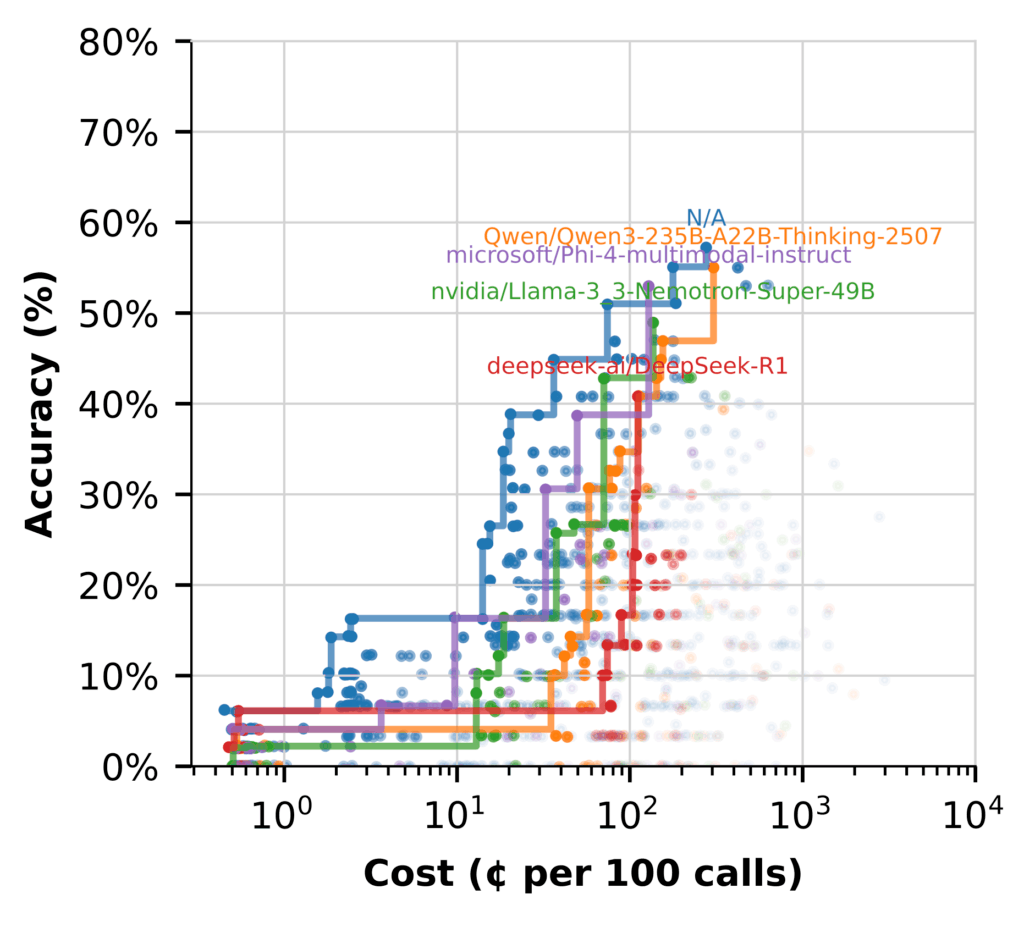
Aqui, vários modelos têm um bom desempenho, com acessibilidade enquanto oferecem fluxos de alta precisão.
Takeaways -chave:
- Nemotron brilha em síntese, produzindo respostas de alta efidelidade sem custo adicional
- Usando outros modelos que se destacam em Hyde libera Nemotron para se concentrar no raciocínio de alto valor
- Os fluxos híbridos são a configuração mais eficiente, usando cada modelo onde ele executa melhor
Otimizando para valor, não apenas tamanho
Ao avaliar novos modelos, o sucesso não é apenas sobre precisão. Trata -se de encontrar o equilíbrio certo de qualidade, custo e ajuste para o seu fluxo de trabalho. Medir a latência, eficiência e impacto geral ajudam a garantir que você está obtendo valor actual
Os modelos de Nvidia Nemotron são construídos com isso em mente. Eles são projetados não apenas para energia, mas também para desempenho prático que ajuda as equipes a impulsionar o impacto sem custos descontrolados.
Mix isso com um processo de avaliação estruturado e guiado por SYFTR e você terá uma maneira repetível de ficar à frente da rotatividade do modelo, mantendo a computação e o orçamento sob controle.
Para explorar ainda mais, confira o Github repositório.