
(Phuttharak/Shutterstock)
Uma startup chamada PuppyGraph está virando a cabeça no mundo do massive information com um novo conceito: casar a eficiência de armazenamento de dados da Information Lakehouse com os recursos analíticos de um banco de dados de gráfico. O resultado é um mecanismo de consulta OLAP, orientado a coluna, distribuído, que corre em cima de mesas de iceberg ou parquet em um armazenamento de objetos e pode escalar horizontalmente na faixa de petabytes.
PuppyGraph foi cofundado em 2023 pelo engenheiro de software program Weimo Liu, que cortou os dentes em bancos de dados de gráficos distribuídos durante os primeiros dias de Tigergraph antes de ingressar Google. Liu, que é CEO da empresa, entende os benefícios que a abordagem do gráfico possui, mas ficou frustrada com baixas taxas de adoção.
“Muitos usuários mostraram forte interesse no gráfico, mas a maioria deles finalmente termina em nada”, diz Liu. “Nunca está em produção. E as pessoas se cansaram depois de passarem muito tempo, e acho que deve haver algo errado. ”
Os bancos de dados de gráficos são conhecidos em manter uma grande vantagem de desempenho em relação aos bancos de dados relacionais quando se trata de executar certos tipos de consultas nos dados conectados. Um banco de dados de gráficos pode executar com eficiência uma travessia multi-hop para descobrir que uma determinada transação está conectada a um fraudador, por exemplo, enquanto a mesma carga de trabalho exigiria uma junção maciça de SQL que traria um banco de dados relacional aos joelhos.
Mas os bancos de dados de gráficos têm uma limitação basic em seu design: os dados devem ser atendidos no banco de dados antes que o mecanismo gráfico possa fazer suas coisas. Há um tempo de inatividade associado à extração dos dados de sua fonte, transformando -os no formato do banco de dados de gráficos e, em seguida, carregá -los no banco de dados do gráfico. Este tem sido a cura de bancos de dados de gráficos de Achille usados para análises (embora não seja tão limitante para cargas de trabalho OTLP).
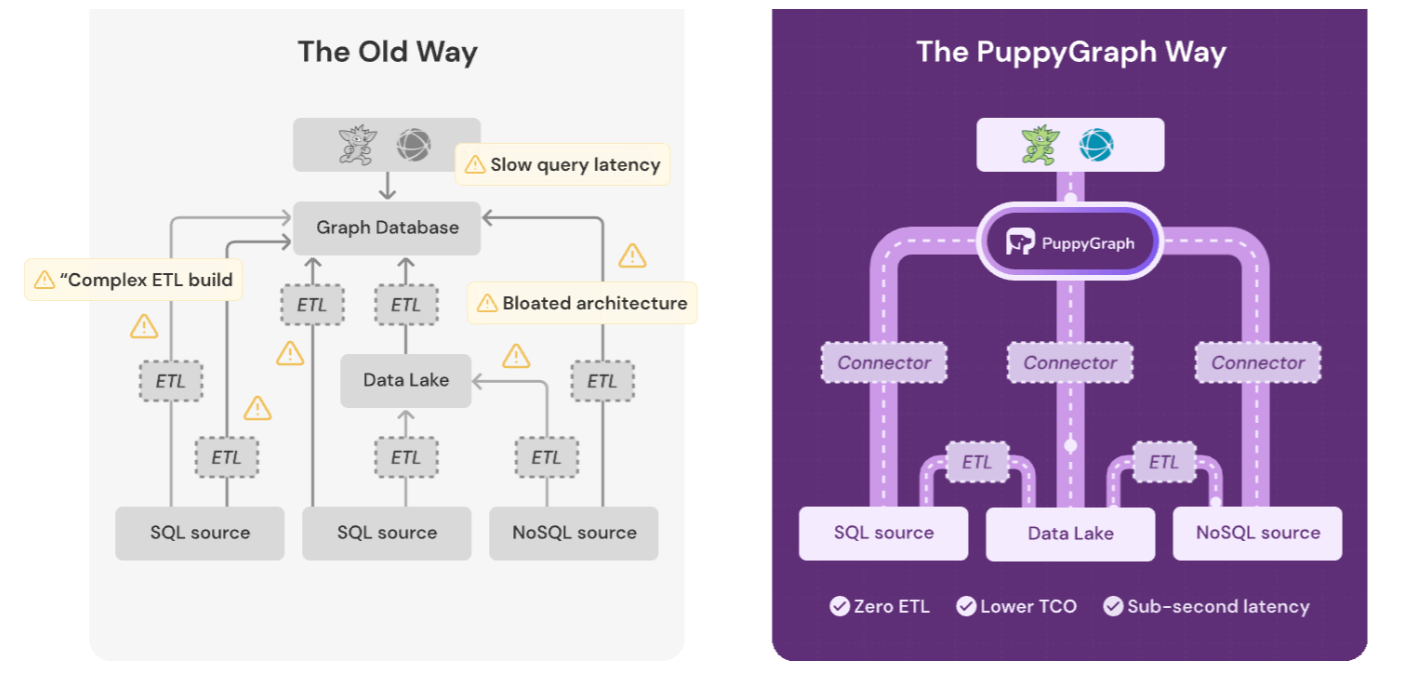
PuppyGraph é um mecanismo de consulta de gráficos orientado a coluna para casas de dados (imagem cortesia de filhotes)
“Acho que um grande bloqueador para a adoção do banco de dados de gráficos não é um gráfico – é sobre o banco de dados”, diz Liu. “Carregando os dados de outro lugar para gráficos de dados. Esse é um grande problema. ”
Enquanto estava no Google, Liu ficou impressionado com a equipe de mecanismo de consulta F1. Um elemento -chave da F1 é um modelo de dados que suporta colunas de tabela com tipos de dados estruturados. Segundo Liu, isso funciona como uma estrutura de dados common que permite que vários formatos de dados sejam definidos como uma tabela alterada para consultas SQL.
“Este é um design muito inspirador”, diz Liu diz Bigdatawire. “Acho que se um gráfico puder (usar) o design, ele se beneficiará muito mais.”
Com o PuppyGraph, Liu e seus co-fundadores esperam eliminar essa limitação no design do banco de dados de gráficos. Ao separar as camadas de computação e armazenamento e construir um mecanismo de consulta de gráficos vetorizado e orientado a colunas, o PuppyGraph diz que pode entregar o desempenho do gráfico OLAP rápido em dados maciços no armazenamento de objetos, eliminando assim o tempo de inatividade associado ao carregamento de dados em bancos de dados gráficos.
Assim como Trino e Presto separaram o armazenamento do mecanismo de consulta SQL e ajudaram a impulsionar o crescimento da arquitetura de Lakehouse, o filhote espera separar o armazenamento do mecanismo de consulta gráfico e aproveitar os dados Lakehouses preenchidos com dados armazenados em formatos de tabela aberta , como Apache Iceberg.
O PuppyGraph executa consultas gráficas em dados armazenados em Lakehouses (imagem cortesia de filhotes)
“Se você já possui dados em outro lugar, como um arquivo parquet, ou no PostgreSQL, MySQL ou Iceberg, podemos apenas consultar diretamente o TOP TIM para executar uma consulta de gráfico. Então o custo a bordo será quase zero ”, diz Liu. “E, ao mesmo tempo, resolve o problema de escalabilidade, porque os lagos de dados como Iceberg e Delta Lake quase não têm nenhuma limitação no tamanho dos dados. Assim, podemos aproveitar seu armazenamento e depois responder à consulta, que foi escrita em linguagem de consulta gráfica. ”
Atualmente, o PuppyGraph suporta Cypher e Gremlin, os dois idiomas mais populares de consulta de gráficos. A empresa empresta o design do mecanismo de consulta do Google F1, que permite ao mecanismo de consulta mapear certos atributos dos dados de origem em uma camada de gráfico lógico composta por nós e bordas, os principais elementos do modelo de dados gráficos. Essa abordagem baseada em coluna permite que o PupyGraph execute com eficiência consultas gráficas sem ter que processar todos os dados em cada registro, diz Liu.
“Cada nó ou cada borda pode ter centenas de atributos, mas durante uma consulta, apenas talvez cinco ou seis serão acessados”, diz ele. “Se pudermos aproveitar o armazenamento baseado em coluna, não precisamos acessar todos os outros atributos. Precisamos apenas colocar os dados necessários na memória e eles podem lidar com mais arestas e nós ao mesmo tempo, o que também é um grande benefício para a análise de gráficos escaláveis. ”
Além da camada de gráfico lógico que executa no topo dos modelos de dados colunares, o PuppyGraph também aproveita o cache e a indexação para fazer com que suas consultas funcionem rápido, diz Liu. A empresa também adotou a técnica de processamento SIMD para fornecer mais paralelismo. Todo o produto de filhotes é executado em um recipiente do Docker no topo do Kubernetes, que lida com a programação de recursos e fornece elasticidade.
Depois que ele construiu o primeiro protótipo de filhotes, Liu entrou em contato com alguns dos fundadores da Tabular, o equipamento comercial atrás do formato da tabela de iceberg (desde que adquirido por Databricks). Os fundadores do iceberg ficaram impressionados que uma consulta de três hop no Azure foi mais rápida que dedicou bancos de dados de gráficos, diz Liu. “Eles percebem, oh, existe um potencial para outros modelos de dados”, diz ele.![]()
O PuppyGraph é uma empresa jovem (ousamos dizer que ainda é um “filhote?”), Mas já tem clientes pagantes, incluindo uma empresa envolvida em criptomoeda. A empresa, que atraiu US $ 5 milhões em financiamento de sementes, está visando casos de uso analítico de gráficos e gráficos OLAP, como detecção de fraude e conformidade regulatória com suas ofertas de nuvem BYOC. Uma versão totalmente gerenciada do PuppyGraph está em andamento.
Embora as cargas de trabalho do OLAP Graph sejam uma boa opção para o PuppyGraph, a empresa não planeja perseguir oportunidades de gráficos OLTP, diz Liu. Essas cargas de trabalho com gráficos orientadas para transações não sofrem com as mesmas desvantagens de carregamento de dados e latência que as cargas de trabalho do OLAP Graph, diz ele.
Mas, quando se trata de análises de gráficos e cargas de trabalho em gráficos de ciência de dados, o pessoal do PuppyGraph está convencido de que um mecanismo de consulta de gráfico distribuído que executa de maneira vetorizada no topo de um lago de dados cheia de mesas de iceberg pode ser o ingresso para as riquezas gráficas.
“Os usuários desejam analisar seus dados como gráfico, e o que precisam é um gráfico, não um banco de dados de gráfico”, diz ele. “Queremos trazer gráficos para seus dados. Então é assim que projetamos nosso sistema. ”
Itens relacionados:
Por que jovens desenvolvedores não recebem gráficos de conhecimento