O chamado para despertar que todos sentimos
Em 20 de outubro de 2025, organizações de todos os setores, do setor bancário ao streaming, da logística à saúde, experimentaram uma degradação generalizada dos serviços quando a região US-EAST-1 da AWS sofreu uma interrupção significativa. Como o Análise Mil Olhos revelado, a interrupção resultou de falhas nas redes internas da AWS e nos sistemas de resolução de DNS que se espalharam pelos serviços dependentes em todo o mundo.
A causa raiz, uma condição de corrida latente no sistema de gerenciamento de DNS do DynamoDB, desencadeou falhas em cascata em todos os serviços de nuvem interconectados. Mas aqui está o que separou as equipes que poderiam responder de forma eficaz daquelas que estavam voando às cegas: visibilidade acionável e multicamadas.
Quando a interrupção começou às 6h49 UTC, um monitoramento sofisticado revelou imediatamente 292 interfaces afetadas em toda a rede da Amazon, apontando Ashburn, Virgínia, como o epicentro. Mais importante ainda, à medida que as condições evoluíram, desde a perda inicial de pacotes até os tempos limite da camada de aplicação e erros HTTP 503, a visibilidade abrangente distinguiu entre problemas de rede e problemas de aplicação. Embora as métricas de superfície mostrassem a eliminação da perda de pacotes às 7h55 UTC, a visibilidade mais profunda revelou uma história diferente: os sistemas de borda estavam vivos, mas sobrecarregados. Os agentes ThousandEyes em 40 pontos de vista mostraram 480 servidores Slack afetados com tempos limite e códigos 5XX, mas a perda de pacotes e a latência permaneceram normais, provando que se tratava de um problema de aplicativo, não de rede.

Figura 1. Mudança na natureza dos sintomas que afetam app.slack.com durante a interrupção da AWS
Os dados do endpoint revelaram pontuações de experiência do app.slack.com de apenas 45% com redirecionamentos de 13 segundos, enquanto a qualidade da rede native permaneceu perfeita em 100%. Sem esse perception multicamadas, as equipes perderiam um tempo precioso em incidentes investigando a camada errada da pilha.
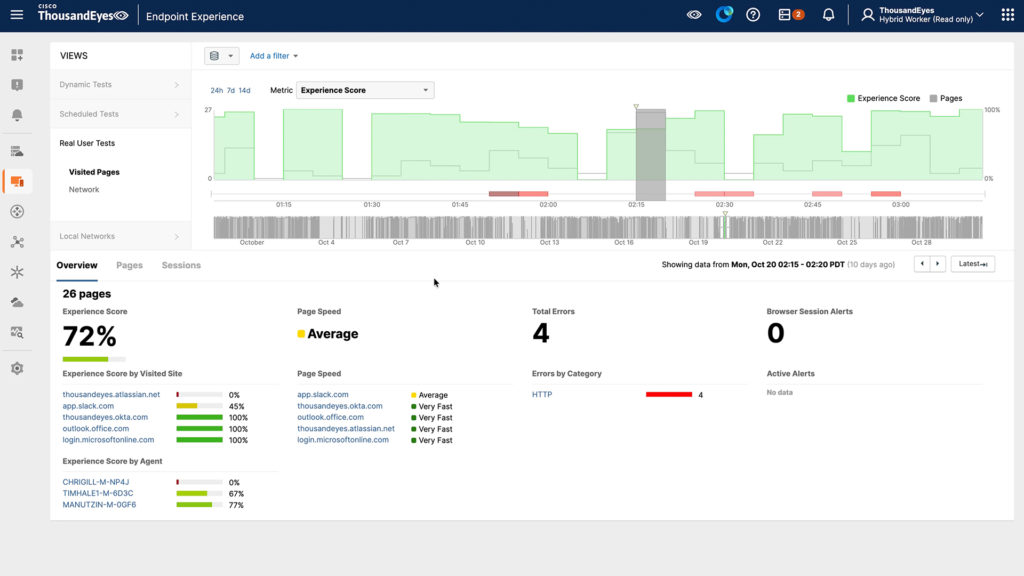
Figura 2. app.slack.com observado para um usuário ultimate
A fase de recuperação destacou por que a visibilidade abrangente é importante além da detecção inicial. Mesmo depois que a AWS restaurou a funcionalidade do DNS por volta das 9h05 UTC, a interrupção continuou por horas, à medida que falhas em cascata se espalhavam pelos sistemas dependentes, o EC2 não conseguia manter o estado, fazendo com que novos lançamentos de servidores falhassem por 11 horas adicionais, enquanto serviços como o Redshift esperavam para se recuperar e limpar backlogs massivos.
A compreensão desse padrão em cascata evitou que as equipes tentassem repetidamente as mesmas correções, reconhecendo, em vez disso, que estavam em uma fase de recuperação em que cada sistema dependente precisava de tempo para se estabilizar. Essa interrupção demonstrou três lições críticas: pontos únicos de falha ficam ocultos até mesmo nas arquiteturas mais redundantes (DNS, BGP), problemas iniciais criam impactos de cauda longa que persistem após a primeira correção e, o mais importante, a visibilidade multicamadas é inegociável.
Nas salas de guerra de hoje, a questão não é se você tem monitoramento, mas se sua visibilidade é abrangente o suficiente para responder rapidamente onde o problema está ocorrendo (rede, aplicativo ou endpoint), qual é o escopo do impacto, por que está acontecendo (causa raiz versus sintomas) e se as condições estão melhorando ou degradando. O monitoramento no nível da superfície indica que algo está errado. Somente uma visibilidade profunda e acionável lhe dirá o que fazer a respeito.
O evento foi um lembrete claro de como os ecossistemas digitais modernos se tornaram interconectados e interdependentes. Os aplicativos hoje são alimentados por uma densa rede de microsserviços, APIs, bancos de dados e planos de controle, muitos dos quais executados na mesma infraestrutura de nuvem. O que parece ser uma única interrupção de serviço muitas vezes mascara uma falha muito mais complexa de componentes interdependentes, revelando como as dependências invisíveis podem rapidamente transformar interrupções locais em impacto international.
Vendo o que importa: a garantia como a nova estrutura de confiança
Na Cisco, vemos a Assurance como o tecido conjuntivo da resiliência digital, trabalhando em conjunto com a Observabilidade e a Segurança para fornecer às organizações a visão, o contexto e a confiança para operar na velocidade da máquina. A garantia transforma dados em compreensão, unindo o que é observado com o que é confiável em todos os domínios, próprios ou não. Essa “estrutura de confiança” conecta redes, nuvens e aplicativos em uma imagem coerente de saúde, desempenho e interdependência.
A visibilidade por si só não é mais suficiente. As arquiteturas distribuídas atuais geram uma enorme quantidade de telemetria, dados de rede, logs, rastreamentos e eventos, mas sem correlação e contexto, esses dados adicionam ruído em vez de clareza. A garantia é o que traduz a complexidade em confiança, conectando cada sinal através das camadas em uma única verdade operacional.
Durante incidentes como o de 20 de outubroo interrupção, plataformas como Cisco ThousandEyes desempenham um papel elementary, fornecendo visibilidade externa em tempo actual sobre como os serviços em nuvem estão se comportando e como os usuários são afetados. Em vez de esperar por atualizações de standing ou reunir registros, as organizações podem observar diretamente onde ocorrem as falhas e qual é o seu impacto no mundo actual.
Os principais recursos que permitem isso incluem:
- Monitoramento de ponto de vista international: O Cisco ThousandEyes detecta problemas de desempenho e acessibilidade de fora para dentro, revelando se a degradação provém da sua rede, do seu provedor ou de algum ponto intermediário.
- Visualização do caminho da rede: Ele identifica onde os pacotes caem, onde há picos de latência e se as anomalias de roteamento se originam em trânsito ou dentro dos limites do provedor de nuvem.
- Sintéticos da camada de aplicação: Ao testar APIs, aplicativos SaaS e endpoints DNS, as equipes podem quantificar o impacto do usuário mesmo quando os sistemas principais parecem “ativos”.
- Dependência da nuvem e mapeamento de topologia: O Cisco ThousandEyes expõe as relações de serviço ocultas que muitas vezes passam despercebidas até falharem.
- Repetição histórica e análise forense: Após o evento, as equipes podem analisar exatamente quando, onde e como a degradação ocorreu, transformando o caos em insights acionáveis para melhorias de arquitetura e processos.
Quando integrado em redes, observabilidade e operações de IA, o Assurance se torna uma camada de orquestração. Ele permite que as equipes modelem interdependências, validem automações e coordenem a correção em vários domínios, desde o information heart até a borda da nuvem.
Juntos, esses recursos transformam visibilidade em confiança, ajudando as organizações a isolar as causas raízes, comunicar-se com clareza e restaurar o serviço com mais rapidez.
Como se preparar para a próxima interrupção “inevitável”
Se os últimos anos mostraram alguma coisa, é que as interrupções em larga escala na nuvem não são raras; eles são uma certeza operacional. A diferença entre o caos e o controlo reside na preparação e em ter a visibilidade e a base de gestão adequadas antes da crise ocorrer.
Aqui estão várias etapas práticas que toda empresa pode realizar agora:
- Mapeie todas as dependências, especialmente as ocultas.
Catalogue não apenas seus serviços de nuvem diretos, mas também os sistemas de plano de controle (DNS, IAM, registros de contêineres, APIs de monitoramento) dos quais eles dependem. Isso ajuda a expor “destinos compartilhados” em cargas de trabalho que parecem independentes. - Teste sua lógica de failover sob estresse.
Exercícios de simulação de mesa e ao vivo geralmente revelam que os failovers não se comportam de maneira tão limpa quanto pretendido. Valide a sincronização, a persistência de sessão e a propagação de DNS em condições controladas antes que ocorram crises reais. - Instrumento de fora para dentro.
A telemetria interna e os painéis do provedor contam apenas parte da história. O monitoramento externo em escala de Web garante que você saiba como seus serviços aparecem para usuários reais em regiões geográficas e ISPs. - Projete para uma degradação graciosa, não para a perfeição.
A verdadeira resiliência consiste em manter o serviço parcial em vez de desaparecer. Crie aplicativos que possam eliminar temporariamente recursos não críticos e, ao mesmo tempo, preservar as transações principais. - Integre a garantia nas respostas a incidentes.
Torne as plataformas de visibilidade externa parte do seu handbook, desde o primeiro alerta até a validação ultimate da recuperação. Isso elimina suposições e acelera a comunicação executiva durante crises. - Revisite suas premissas de governança e investimento.
Use incidentes como este para quantificar sua exposição: quantas cargas de trabalho dependem de uma única região fornecedora? Qual é o impacto potencial na receita de uma interrupção? Em seguida, use essas descobertas para informar os gastos com garantia, observabilidade e redundância.
O objetivo não é eliminar a complexidade; é para simplificar. As plataformas de garantia ajudam as equipes a validar continuamente arquiteturas, monitorar dependências dinâmicas e tomar decisões confiáveis e baseadas em dados em meio à incerteza.
Resiliência na velocidade da máquina
A interrupção da AWS ressaltou que nosso mundo digital agora opera na velocidade das máquinas, mas a confiança deve acompanhar o ritmo. Sem a capacidade de validar o que realmente está acontecendo nas nuvens e nas redes, a automação pode agir cegamente, piorando o impacto de um evento já frágil.
É por isso que a abordagem da Cisco à garantia como uma estrutura de confiança combina a velocidade da máquina com a confiança da máquina, capacitando as organizações a detectar, decidir e agir com confiança. Ao tornar a complexidade observável e acionável, o Assurance permite que as equipes automatizem com segurança, recuperem de forma inteligente e se adaptem continuamente.
As interrupções continuarão a acontecer. Mas com os recursos certos de visibilidade, inteligência e garantia implementados, suas consequências não precisam definir seu negócio.
Vamos construir operações digitais que não sejam apenas rápidas, mas também confiáveis, transparentes e prontas para o que vier a seguir.