O Openai não lançou um modelo de idioma de peso aberto desde o GPT-2 em 2019. Seis anos depois, eles surpreenderam a todos com dois: GPT-OSS-120B e o menor GPT-OSS-20B.
Naturalmente, queríamos saber – como eles realmente se apresentam?
Para descobrir, executamos os dois modelos através da nossa estrutura de otimização de fluxo de trabalho de código aberto, Syftr. Ele avalia modelos em diferentes configurações – rápido versus barato, alta versus baixa precisão – e inclui suporte para o novo do OpenAi “Esforço de pensamento” contexto.
Em teoria, mais pensamentos devem significar melhores respostas. Na prática? Nem sempre.
Também usamos o SYFTR para explorar perguntas como “O LLM-AS-A-JUDGE realmente está funcionando?” e “Quais fluxos de trabalho têm um bom desempenho em muitos conjuntos de dados? ”.
Nossos primeiros resultados com o GPT-OSS podem surpreendê-lo: O melhor desempenho não period o maior modelo ou o pensador mais profundo.
Em vez disso, o modelo 20B com esforço de pensamento baixo aterrissou consistentemente no Pareto Frontier, Mesmo rivalizando com a configuração do meio 120B em benchmarks como Financebench, Hotpotqa e Multihoprag. Enquanto isso, o alto esforço de pensamento raramente importava.
Como configuramos nossos experimentos
Nós não apenas colocamos o GPT-Oss contra si mesmo. Em vez disso, queríamos ver como isso se acumulou contra outros modelos fortes de peso aberto. Então nós comparamos GPT-OSS-20B e GPT-OSS-120B com:
- QWEN3-235B-A22B
- GLM-4.5-AIR
- Nemotron-Tremendous-49b
- QWEN3-30B-A3B
- gemma3-27b-it
- PHI-4-MULTIMODAL-INSTRUTA
Para testar o novo recurso de “esforço de pensamento” do OpenAI, executamos cada modelo GPT-OSS em três modos: esforço de pensamento baixo, médio e alto. Isso nos deu seis configurações no whole:
- GPT-OSS-120B-Low / -Medium / -Excessive
- GPT-OSS-20B-LOW / -MEDIUM / -HIGH
Para avaliação, lançamos uma ampla rede: cinco modos de pano e agente, 16 modelos de incorporação e uma variedade de opções de configuração de fluxo. Para julgar as respostas dos modelos, usamos o GPT-4O-Mini e comparamos as respostas contra a verdade conhecida.
Finalmente, testamos em quatro conjuntos de dados:
- Financebench (raciocínio financeiro)
- Hotpotqa (QA multi-hop)
- Multihoprag (raciocínio de recuperação de recuperação)
- Phantomwiki (pares de perguntas e respostas sintéticas)
Otimizamos os fluxos de trabalho duas vezes: uma vez para a precisão + latência e uma vez por precisão + custo-capturando as compensações que mais importam nas implantações do mundo actual.
Otimizando para latência, custo e precisão
Quando otimizamos os modelos GPT-ROSS, analisamos duas compensações: Precisão vs. latência e Precisão vs. custo. Os resultados foram mais surpreendentes do que esperávamos:
- GPT-OSS 20B (baixo esforço de pensamento):
Rápido, barato e consistentemente preciso. Esta configuração apareceu na fronteira de Pareto repetidamente, tornando -a a melhor escolha padrão Para a maioria das tarefas não científicas. Na prática, isso significa respostas mais rápidas e contas mais baixas em comparação com os esforços de pensamento mais altos. - GPT-ASS 120B (esforço de pensamento médio):
Mais adequado para tarefas que exigem raciocínio mais profundo, como benchmarks financeiros. Use isso quando a precisão em problemas complexos importa mais do que o custo. - GPT-ASS 120B (esforço de pensamento alto):
Caro e geralmente desnecessário. Mantenha -o no bolso traseiro para casos de borda, onde outros modelos ficam aquém. Para nossos benchmarks, não agregou valor.

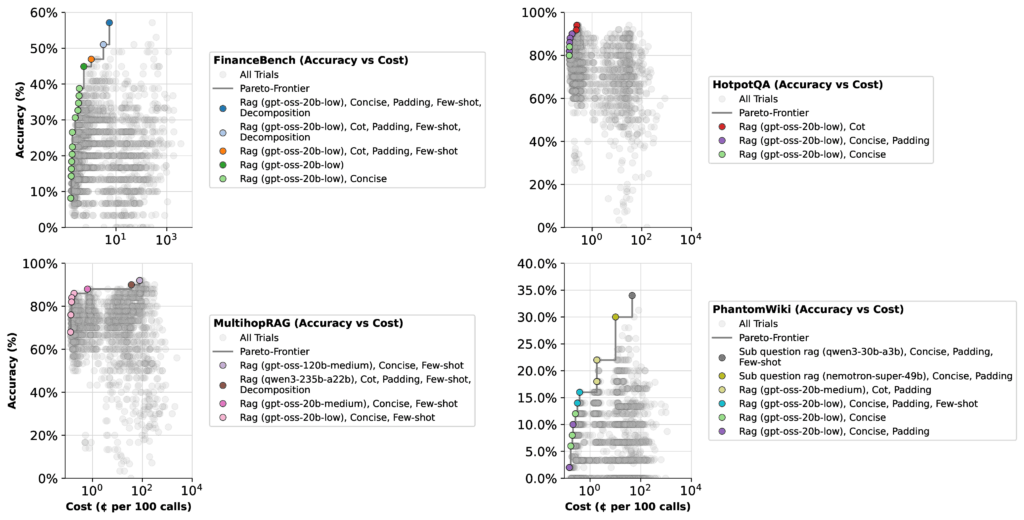
Lendo os resultados com mais cuidado
À primeira vista, os resultados parecem diretos. Mas há uma nuance importante: a pontuação de precisão de um LLM depende não apenas do próprio modelo, mas de como o otimizador o pesa contra outros modelos no combine. Para ilustrar, vejamos o Financebench.
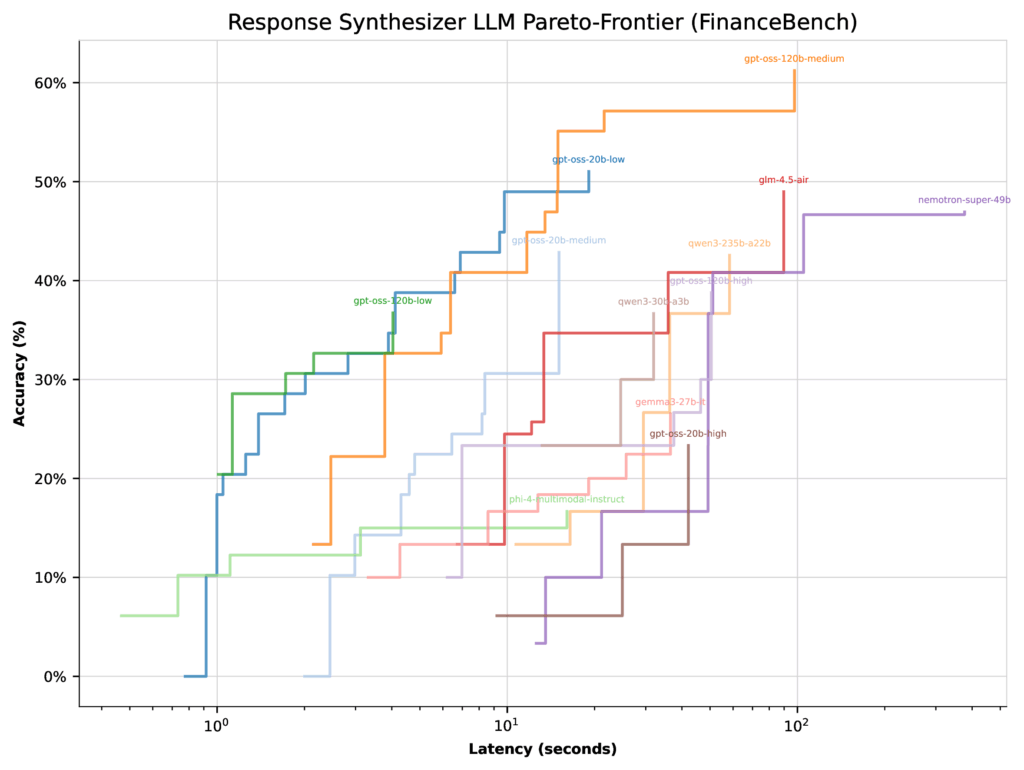
Ao otimizar a latência, todos os modelos GPT-OSS (exceto um esforço de pensamento alto) pousaram com pareto-frontais semelhantes. Nesse caso, o otimizador tinha poucas razões para se concentrar na configuração de baixo pensamento de 20b – sua precisão superior foi de apenas 51%.
Ao otimizar para custoa imagem muda drasticamente. A mesma configuração de pensamento baixo de 20b salta para 57% de precisão, enquanto a configuração do meio de 120B realmente cai 22%. Por que? Como o modelo 20B é muito mais barato, o otimizador muda mais peso em direção a ele.
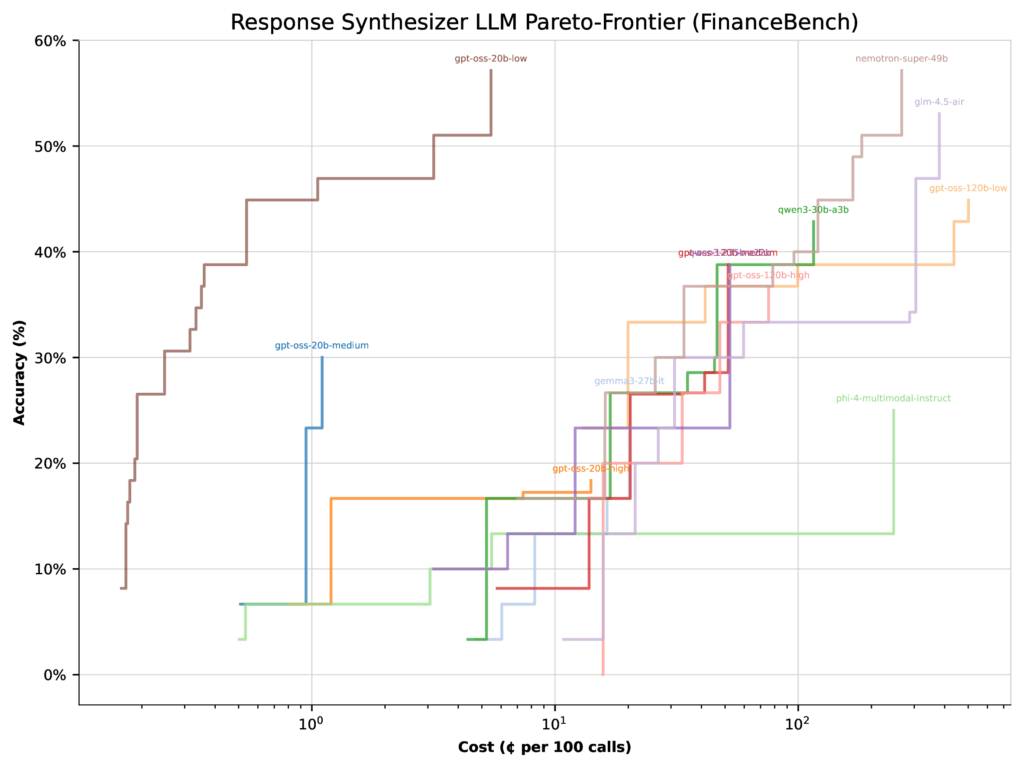
O take -away: O desempenho depende do contexto. Os otimizadores favorecerão modelos diferentes, dependendo de você estar priorizando a velocidade, o custo ou a precisão. E, dado o enorme espaço de pesquisa de possíveis configurações, pode haver configurações ainda melhores além das que testamos.
Encontrar fluxos de trabalho agênticos que funcionam bem em sua configuração
Os novos modelos GPT-OSS tiveram um desempenho fortemente em nossos testes-especialmente os 20B com baixo esforço de pensamento, que muitas vezes ultrapassavam os concorrentes mais caros. A lição maior? Mais modelo e mais esforço nem sempre significa mais precisão. Às vezes, pagar mais apenas te dá menos.
É exatamente por isso que construímos o SYFTR e o tornamos de código aberto. Todo caso de uso é diferente e o melhor fluxo de trabalho para você depende das trocas de quem você mais se importa. Quer custos mais baixos? Respostas mais rápidas? Precisão máxima?
Execute seus próprios experimentos E encontre o ponto excellent de Pareto que equilibra essas prioridades para sua configuração.