Desbloqueie o raciocínio mais rápido e eficiente, com o areio de Phi-4-Mini-Flash-otimizado para aplicativos de borda, móveis e em tempo actual.
A arquitetura de última geração redefine a velocidade dos modelos de raciocínio
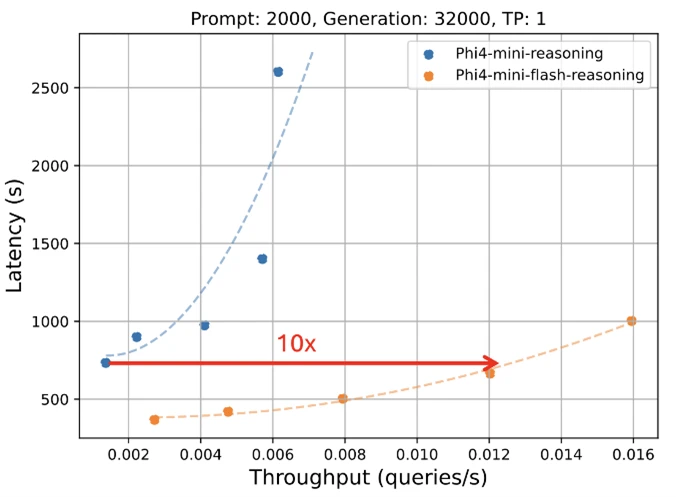
A Microsoft está animada para revelar uma nova edição para a família Mannequin Phi: Phi-4-mini-flash-rastreio. Projetado para cenários em que computação, memória e latência são fortemente restringidas, esse novo modelo é projetado para trazer recursos avançados de raciocínio para os dispositivos de ponta, aplicativos móveis e outros ambientes restritos a recursos. Esse novo modelo segue o PHI-4-mini, mas é construído em uma nova arquitetura híbrida, que atinge até 10 vezes maior taxa de transferência e uma redução média de 2 a 3 vezes na latência, permitindo uma inferência significativamente mais rápida sem sacrificar o desempenho do raciocínio. Pronto para alimentar soluções do mundo actual que exigem eficiência e flexibilidade, o areio de Phi-4-Mini-Flash está disponível em Azure AI FoundryAssim, Nvidia API Cataloge Abraçando o rosto hoje.
Eficiência sem compromisso
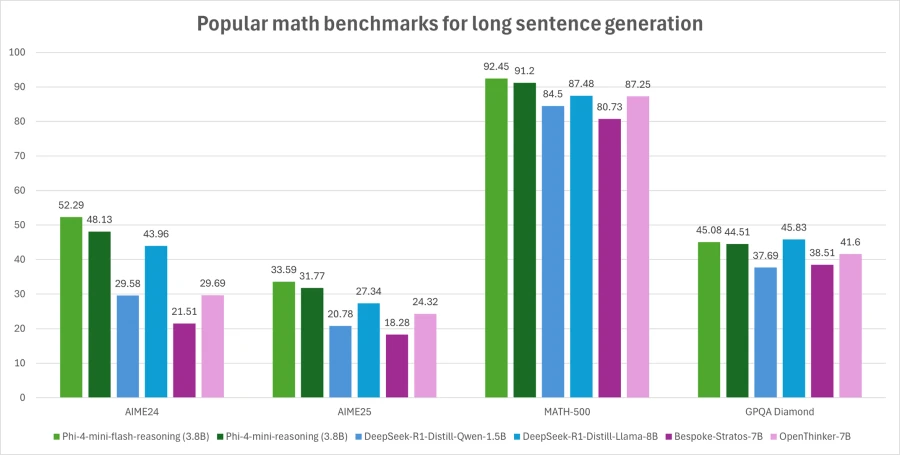
Phi-4-mini-Flash-Flash balança a capacidade de raciocínio matemático com eficiência, tornando-o potencialmente adequado para aplicações educacionais, aplicativos baseados em lógica em tempo actual e muito mais.
Semelhante ao seu antecessor, o areio de Phi-4-Mini-Flash é um modelo aberto de 3,8 bilhões de parâmetros otimizado para o raciocínio avançado de matemática. Ele suporta um comprimento de contexto de 64 mil token e é ajustado em dados sintéticos de alta qualidade para fornecer implantação confiável e intensiva de lógica.
O que há de novo?
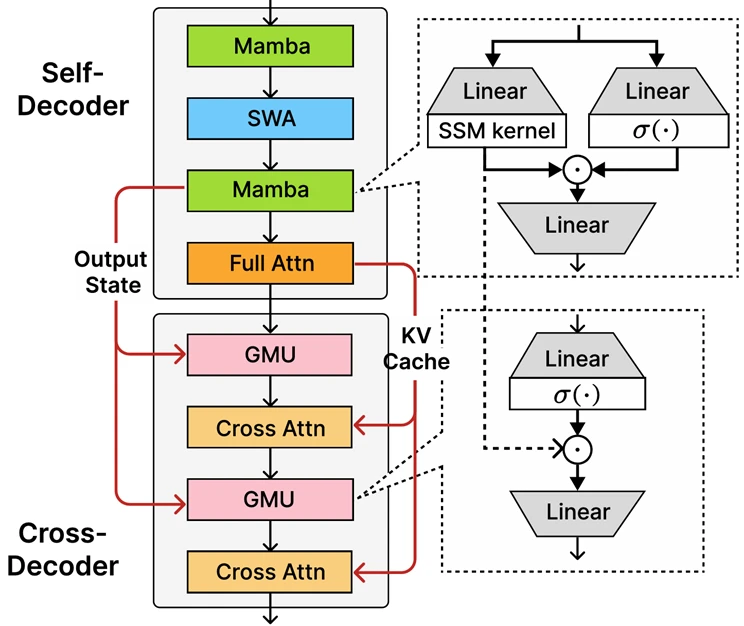
No centro da PHI-4-Mini-Flash-Flash, está a arquitetura decodificadora-híbrida recém-introduzida, Sambay, cuja inovação central é a unidade de memória fechada (GMU), um mecanismo simples, mas eficaz, para compartilhar representações entre camadas. A arquitetura inclui um autocopodidor que combina Mamba (um modelo de espaço de estado) e a atenção da janela deslizante (SWA), juntamente com uma única camada de atenção whole. A arquitetura também envolve um decodificador cruzado que intercala camadas caras de atendimento cruzado com as novas GMus eficientes. Essa nova arquitetura com módulos GMU melhora drasticamente a eficiência de decodificação, aumenta o desempenho de recuperação de longo contexto e permite que a arquitetura ofereça desempenho excepcional em uma ampla gama de tarefas.
Os principais benefícios da arquitetura de Sambay incluem:
- Eficiência aprimorada de decodificação.
- Preserva a complexidade do tempo de pré -aterramento linear.
- Maior escalabilidade e melhor desempenho de contexto longo.
- Até 10 vezes maior taxa de transferência.
PHI-4-MINI-FLASH RESÍCULOS RECEIROS
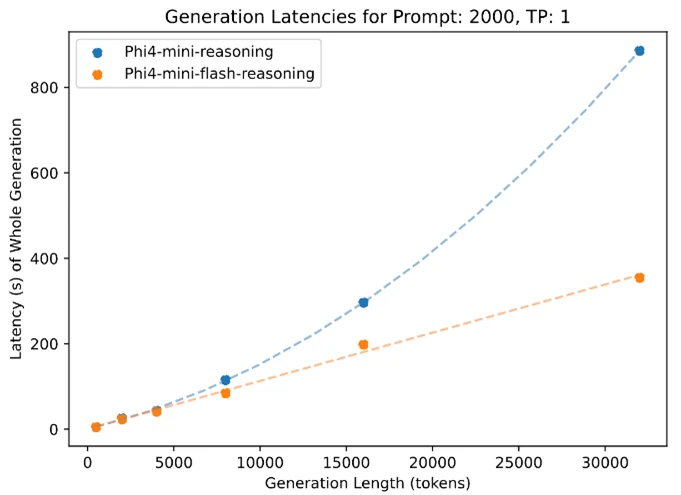
Como todos os modelos da família Phi, o areio de Phi-4-Mini-Flash é implantável em uma única GPU, tornando-a acessível para uma ampla gama de casos de uso. No entanto, o que o diferencia é sua vantagem arquitetônica. Esse novo modelo alcança uma latência significativamente menor e maior taxa de transferência em comparação com as tarefas de raciocínio sensível ao raciocínio sensíveis ao PHI-4-Mini, particularmente em tarefas de raciocínio sensíveis ao contexto.
Isso faz com que o Phi-4-Mini-Flash-Flash uma opção atraente para desenvolvedores e empresas que desejam implantar sistemas inteligentes que requerem raciocínio rápido, escalável e eficiente-seja em premissas ou no dispositivo.
Quais são os casos de uso potencial?
Graças à sua latência reduzida, taxa de transferência aprimorada e foco no raciocínio matemático, o modelo é very best para:
- Plataformas de aprendizado adaptativoonde os loops de suggestions em tempo actual são essenciais.
- Assistentes de raciocínio no dispositivocomo auxílios móveis de estudo ou agentes lógicos baseados em borda.
- Sistemas de tutoria interativa Isso ajusta dinamicamente a dificuldade de conteúdo com base no desempenho de um aluno.
Sua força em matemática e raciocínio estruturado o torna especialmente valioso para a tecnologia educacional, simulações leves e ferramentas de avaliação automatizadas que requerem inferência lógica confiável com tempos de resposta rápidos.
Os desenvolvedores são incentivados a se conectar com colegas e engenheiros da Microsoft através do Comunidade de Discord de desenvolvedor da Microsoft Para fazer perguntas, compartilhar suggestions e explorar casos de uso do mundo actual juntos.
Compromisso da Microsoft com AI confiável
Organizações de todas as indústrias estão alavancando o Azure AI e Microsoft 365 Copilot Recursos para impulsionar o crescimento, aumentar a produtividade e criar experiências de valor agregado.
Estamos comprometidos em ajudar as organizações a usar e construir Ai que é confiávelo que significa que é seguro, privado e seguro. Trazemos as melhores práticas e aprendizados de décadas de pesquisa e construção de produtos de IA em escala para fornecer compromissos e capacidades líderes do setor que abrangem nossos três pilares de segurança, privacidade e segurança. A IA confiável só é possível quando você combina nossos compromissos, como nosso Iniciativa futura segura e nosso Princípios de IA responsáveiscom nossos recursos de produto para desbloquear a transformação da IA com confiança.
Os modelos PHI são desenvolvidos de acordo com os princípios da Microsoft AI: responsabilidade, transparência, justiça, confiabilidade e segurança, privacidade e segurança e inclusão.
A família Modelo PHI, incluindo o rendimento do PHI-4-mini-flash, emprega uma robusta estratégia pós-treinamento de segurança que integra o ajuste fino supervisionado (SFT), a otimização direta de preferência (DPO) e o aprendizado de reforço com o suggestions humano (RLHF). Essas técnicas são aplicadas usando uma combinação de conjuntos de dados de código aberto e proprietários, com uma forte ênfase em garantir a utilidade, minimizar resultados nocivos e abordar uma ampla gama de categorias de segurança. Os desenvolvedores são incentivados a aplicar as melhores práticas responsáveis de IA adaptadas aos seus casos de uso específicos e contextos culturais.
Leia o cartão do modelo para saber mais sobre quaisquer estratégias de risco e mitigação.
Saiba mais sobre o novo modelo
Crie com o Azure AI Foundry