O panorama de inteligência syntheticparticularmente no processamento de linguagem pure (PNL), está passando por uma mudança transformadora com a introdução do Transformador Latente de Byte (BLT) e O último artigo de pesquisa da Meta derrama alguns feijões sobre o mesmo. Esta arquitetura inovadora, desenvolvida por pesquisadores da Meta IAdesafia a dependência tradicional da tokenização em grandes modelos de linguagem (LLMs), abrindo caminho para um processamento de linguagem mais eficiente e robusto. Esta visão geral explora os principais recursos, vantagens e implicações do BLT para o futuro da PNLcomo uma cartilha para o amanhecer onde provavelmente os tokens podem ser substituídos para sempre.
")
Figura 1: Arquitetura BLT: Composta por três módulos, um codificador native leve que codifica bytes de entrada em representações de patch, um transformador latente computacionalmente caro sobre representações de patch e um decodificador native leve para decodificar o próximo patch de bytes.
O problema da tokenização
A tokenização tem sido uma pedra angular na preparação do texto dados para treinamento de modelo de linguagem, convertendo texto bruto em um conjunto fixo de tokens. No entanto, este método apresenta várias limitações:
- Viés de linguagem: A tokenização pode criar desigualdades em diferentes idiomas, muitas vezes favorecendo aqueles com conjuntos de tokens mais robustos.
- Sensibilidade ao Ruído: os tokens corrigidos têm dificuldade para representar com precisão entradas ruidosas ou variantes, o que pode degradar o desempenho do modelo.
- Compreensão ortográfica limitada: A tokenização tradicional muitas vezes ignora detalhes linguísticos diferenciados que são críticos para uma compreensão da linguagem.
Apresentando o transformador latente de bytes
O BLT aborda esses desafios processando a linguagem diretamente no nível do byte, eliminando a necessidade de um vocabulário fixo. Em vez de tokens predefinidos, ele utiliza um mecanismo de patch dinâmico que agrupa bytes com base em sua complexidade e previsibilidade, medida por entropia. Isto permite que o modelo aloque recursos computacionais de forma mais eficaz e se concentre em áreas onde é necessária uma compreensão mais profunda.
Principais inovações técnicas
- Patching de Byte Dinâmico: O BLT segmenta dinamicamente o byte dados em patches adaptados à complexidade de suas informações, aumentando a eficiência computacional.
- Arquitetura de três camadas:
- Codificador native leve: converte fluxos de bytes em representações de patch.
- Grande Transformador Latente International: processa essas representações em nível de patch.
- Decodificador native leve: traduz representações de patch de volta em sequências de bytes.
Principais vantagens do BLT
- Eficiência aprimorada: A arquitetura BLT reduz significativamente os custos computacionais durante o treinamento e a inferência, ajustando dinamicamente os tamanhos dos patches, levando a uma redução de até 50% nas operações de ponto flutuante (FLOPs) em comparação com modelos tradicionais como o Llama 3.
- Robustez ao Ruído: Trabalhando diretamente com nível de byte dadoso BLT apresenta maior resiliência ao ruído de entrada, garantindo desempenho confiável em diversas tarefas.
- Melhor compreensão das estruturas de subpalavras: A abordagem em nível de byte permite capturar detalhes intrincados da linguagem que os modelos baseados em tokens podem perder, particularmente benéfico para tarefas que exigem compreensão fonológica e ortográfica profunda.
- Escalabilidade: a arquitetura foi projetada para ser dimensionada de maneira eficaz, acomodando modelos e conjuntos de dados maiores sem comprometer o desempenho.
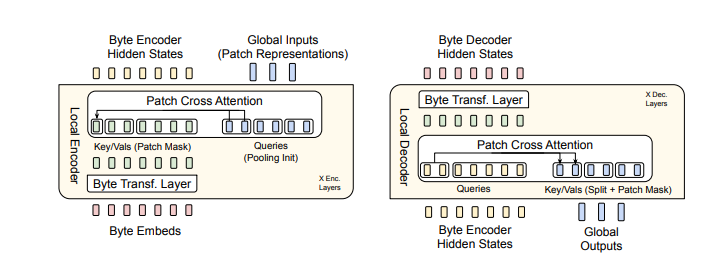
Figura 2: BLT utiliza incorporações de n-gramas de bytes junto com um mecanismo de atenção cruzada para melhorar o fluxo de informações entre o Transformador Latente e os módulos de nível de byte (veja a Figura 5). Em contraste com a tokenização de vocabulário fixo, o BLT organiza dinamicamente os bytes em patches, mantendo assim o acesso às informações em nível de byte.
Resultados Experimentais
Extensos experimentos demonstraram que o BLT corresponde ou excede o desempenho dos modelos baseados em tokenização estabelecidos, ao mesmo tempo que utiliza menos recursos. Por exemplo:
- No HellaSwag barulhento dados benchmark, o Llama 3 alcançou 56,9% de precisão, enquanto o BLT atingiu 64,3%.
- Em tarefas de compreensão em nível de personagem, como benchmarks de similaridade ortográfica e semântica, alcançou taxas de precisão quase perfeitas.
Estes resultados sublinham o potencial do BLT como uma alternativa atraente em PNL aplicações.
Implicações no mundo actual
A introdução do BLT abre possibilidades interessantes para:
- Mais eficiente IA processos de treinamento e inferência.
- Manipulação aprimorada de linguagens morfologicamente ricas.
- Desempenho aprimorado em entradas ruidosas ou variantes.
- Maior equidade no processamento de linguagem multilíngue.
Limitações e Trabalho Futuro
Apesar da sua natureza inovadora, os investigadores reconhecem várias áreas para exploração futura:
- Desenvolvimento de modelos de patches aprendidos ponta a ponta.
- Otimização adicional de técnicas de processamento em nível de byte.
- Investigação sobre leis de escala específicas para transformadores de nível de byte.
Conclusão
O Byte Latent Transformer marca um avanço significativo na modelagem de linguagem, indo além dos métodos tradicionais de tokenização. A sua arquitectura inovadora não só aumenta a eficiência e a robustez, mas também redefine a forma como IA pode compreender e gerar a linguagem humana. À medida que os pesquisadores continuam a explorar suas capacidades, antecipamos avanços emocionantes em PNL que levará a sistemas mais inteligentes e adaptáveis IA sistemas. Em resumo, o BLT representa um mudança de paradigma no processamento de linguagem – um que poderia redefinir as capacidades da IA na compreensão e geração eficaz da linguagem humana.
A postagem Revolucionando modelos de linguagem: o transformador latente de bytes (BLT) apareceu primeiro em Datafloq.