Nossos clientes continuam mudança desde prompts monolíticos com modelos de uso geral até sistemas de agentes especializados para alcançar a qualidade necessária para impulsionar o ROI com IA generativa. No início deste ano, nós lançado o Mosaic AI Agent Framework e Agent Analysis, que agora são usados por muitas empresas para construir sistemas de agentes capazes de raciocínio complexo sobre dados corporativos e executar tarefas como abrir tickets de suporte e responder a e-mails.
Hoje, temos o prazer de anunciar uma melhoria significativa na Avaliação de Agentes: um API de geração de dados sintéticos. A geração de dados sintéticos envolve a criação de conjuntos de dados artificiais que imitam dados do mundo actual – mas é importante observar que não se trata de informações “inventadas”. Nossa API aproveita seus dados proprietários para gerar conjuntos de avaliação personalizados com base nesses dados proprietários e em seus casos de uso exclusivos. Os dados de avaliação, semelhantes a um conjunto de testes em engenharia de software program ou dados de validação em ML tradicional, permitem avaliar e melhorar a qualidade do agente.
Isso permite que você gere dados de avaliação rapidamente – evitando semanas ou meses de rotulagem de dados de avaliação com especialistas no assunto (PMEs). Os clientes já estão obtendo sucesso com esses recursos, acelerando o tempo de produção e aumentando a qualidade do agente, ao mesmo tempo que reduzem os custos de desenvolvimento:
“Os recursos de dados sintéticos na avaliação de agentes de IA do Mosaic aceleraram significativamente nosso processo de melhoria da qualidade de resposta dos agentes de IA. Ao pré-gerar perguntas e respostas sintéticas de alta qualidade, minimizamos o tempo que nossos especialistas no assunto gastaram criando conjuntos de avaliação de verdade, permitindo para que eles se concentrassem na validação e em pequenas modificações. Essa abordagem nos permitiu melhorar a qualidade relativa da resposta do modelo em 60%, mesmo antes de envolver os especialistas.”
– Chris Nishnick, Diretor de Inteligência Synthetic da Lippert
Apresentando a API de geração de dados sintéticos
Avaliar e melhorar a qualidade dos agentes é basic para proporcionar melhores resultados de negócios, mas muitas organizações enfrentam os gargalos da criação de conjuntos de dados de avaliação de alta qualidade para medir e melhorar seus agentes. Os processos de rotulagem demorados, a disponibilidade limitada de (PME) e o desafio de gerar questões diversas e significativas atrasam frequentemente o progresso e sufocam a inovação.
Avaliação do Agente API de geração de dados sintéticos resolve esses desafios capacitando os desenvolvedores a criar um conjunto de avaliação de alta qualidade com base em seus dados proprietários em minutos, permitindo-lhes avaliar e melhorar a qualidade de seus agentes sem a necessidade de bloquear a entrada de PMEs. Pense em um conjunto de avaliação semelhante ao conjunto de validação no ML tradicional ou em um conjunto de testes na engenharia de software program. A API de geração sintética está totalmente integrada com Avaliação de Agente, MLflow, Mosaic AI e o restante da Plataforma de Inteligência de Dados Databricks, permitindo que você use os dados para avaliar e melhorar rapidamente a qualidade das respostas do seu agente. Para começar, veja o caderno de início rápido.

Como funciona?
Projetamos a API para ser simples de usar. Primeiro, chame a API com a seguinte entrada:
- Um quadro de dados Spark ou Pandas contendo os documentos/conhecimento empresarial que seu agente usará
- O número de perguntas a serem geradas
- Opcionalmente, um conjunto de diretrizes em linguagem simples para orientar a geração sintética.
- Por exemplo, você pode explicar o caso de uso do agente, a personalidade do usuário ultimate ou o estilo de perguntas desejado
Com base nesta entrada, a API gera um conjunto de mflow.consider(...)que executa juízes LLM proprietários da Agent Analysis para avaliar a qualidade do seu agente e identificar a causa raiz de quaisquer problemas de qualidade para que você possa corrigi-los rapidamente.
Você pode revisar os resultados da análise de qualidade usando a IU de avaliação do MLflow, fazer alterações em seu agente para melhorar a qualidade e, em seguida, verificar se essas melhorias de qualidade funcionaram executando novamente mlflow.consider(...).
Opcionalmente, você pode compartilhar os dados gerados sinteticamente com suas PMEs para revisar a precisão das perguntas/respostas. É importante ressaltar que a resposta sintética gerada é um conjunto de fatos necessários para responder à pergunta, e não uma resposta escrita pelo LLM. Esta abordagem tem o benefício distinto de tornar mais rápido para uma PME revisar e editar esses fatos em vez de uma resposta completa gerada.
Aumente o desempenho do agente em cinco minutos
Para se aprofundar mais, você pode acompanhar este caderno de exemplo que demonstra como os desenvolvedores podem melhorar a qualidade de seu agente com as seguintes etapas:
- Gere um conjunto de dados de avaliação sintético
- Construa e avalie um Agente de linha de base
- Examine o agente de linha de base em diversas configurações (prompts, and many others.) e modelos básicos para encontrar o equilíbrio certo entre qualidade, custo e latência
- Implante o agente em uma UI da net para permitir que as partes interessadas testem e forneçam suggestions adicional

A API de geração de dados sintéticos
Para sintetizar avaliações para um agente, os desenvolvedores podem chamar o generate_evals_df método para gerar um conjunto de avaliação representativo a partir de seus documentos.
from databricks.brokers.evals import generate_evals_df
evals = generate_evals_df(
docs, # Delta Desk or Pandas / Spark Dataframe with "content material" and "doc_uri" columns.
num_evals=10,
agent_description="...", # Non-obligatory, describe the duty of the Agent
question_guidelines = "..." # Non-obligatory, management type and sort of questions.
)
outcomes = mlflow.consider(
mannequin=my_agent, # Agent's code, logged as an MLflow mannequin
information=evals, # Artificial analysis information from the API
model_type="databricks-agent" # Activate Agent Analysis's LLM judges
)Rubrica: um exemplo de uso da API de geração de dados sintéticos.
Personalização e controle
Através de nossas conversas com clientes, descobrimos que os desenvolvedores desejam fornecer mais do que apenas uma lista de documentos: eles buscam maior controle sobre o processo de geração de perguntas. Para atender a essa necessidade, nossa API inclui recursos opcionais que capacitam os desenvolvedores a criar perguntas de alta qualidade adaptadas aos seus casos de uso específicos.
agent_descriptionque descrevem a tarefa do agentequestion_guidelinesque controlam o estilo e o tipo de perguntas.
agent_description = """
The Agent is a RAG chatbot that solutions questions on Databricks.
"""
question_guidelines="""
# Person personas
- A developer who's new to the Databricks platform
- An skilled, extremely technical Knowledge Scientist or Knowledge Engineer
# Instance questions
- what API lets me parallelize operations over rows of a delta desk?
- Which cluster settings will give me one of the best efficiency when utilizing Spark?
# Further Tips
- Questions needs to be succinct, and human-like
"""Rubrica: Exemplo agent_description e question_guidelines para um chatbot Databricks RAG.
Saída da API de geração sintética
Para explicar os resultados da API, passamos esta postagem do weblog como um documento de entrada para a API com as seguintes diretrizes de perguntas:
Crie perguntas apenas sobre o conteúdo e não sobre o código. Perguntas são aquelas que seriam feitas por um desenvolvedor tentando entender se este é um bom produto para ele. As perguntas devem ser curtas, como uma consulta em um mecanismo de pesquisa para encontrar resultados específicos.
Perguntas de exemplo:
– para que são utilizados os dados sintéticos?
– como personalizar dados sintéticos?
A saída da API de geração de dados sintéticos é uma tabela que segue nossa Esquema de avaliação do agente. Cada linha do conjunto de dados contém um único caso de teste, usado pelo juiz de correção de resposta da Avaliação do Agente para avaliar se o seu agente pode gerar uma resposta à pergunta que inclua todos os fatos esperados.
Nome do campo | Descrição | Exemplo desta postagem do weblog |
| Uma pergunta que o usuário provavelmente fará ao seu agente | Como posso personalizar a geração de perguntas com a API de dados sintéticos? |
| A passagem específica do documento fonte do qual o | Através de nossas conversas com clientes, descobrimos que os desenvolvedores desejam fornecer mais do que apenas uma lista de documentos: eles buscam maior controle sobre o processo de geração de perguntas. Para atender a essa necessidade, nossa API inclui recursos opcionais que capacitam os desenvolvedores a criar perguntas de alta qualidade adaptadas aos seus casos de uso específicos.
|
| Uma lista de fatos, sintetizada a partir do | – Usar – Usar |
| O ID exclusivo do documento de origem de origem deste caso de teste. | https://weblog.databricks.com/weblog/streamline-ai-agent-evaluation-with-new-synthetic-data-capabilities |
Rubrica: os campos de saída da API de geração de avaliação sintética e uma linha de amostra produzida pela API com base no conteúdo deste weblog.
Abaixo incluímos uma amostra de alguns outros requests e expected_facts gerado pelo código acima.
|
|
Quais benefícios os clientes obtêm ao usar recursos de dados sintéticos na avaliação de agentes do Mosaic AI? | – Acelerando o tempo de produção – Aumentando a qualidade do agente – Redução do custo de desenvolvimento |
Quais entradas são necessárias para usar a API de geração de dados sintéticos? | – É necessário um quadro de dados Spark ou Pandas – O quadro de dados deve conter documentos ou conhecimento empresarial – O número de perguntas a gerar deve ser especificado. |
O que é um conjunto de avaliação comparado ao aprendizado de máquina tradicional e à engenharia de software program? | – Um conjunto de avaliação é comparado a um conjunto de validação no aprendizado de máquina tradicional – Um conjunto de avaliação é comparado a um conjunto de testes em engenharia de software program. |
Rubrica: amostra de linha adicional produzida pela API com base no conteúdo deste weblog.
Integração com MLFlow e avaliação de agente
O conjunto de dados de avaliação gerado pode ser usado diretamente com mlflow.consider(..., model_type=”databricks-agent”) e a nova IU de avaliação MLFlow. Resumindo, o desenvolvedor pode medir rapidamente a qualidade de seu agente usando juízes LLM integrados e personalizados, inspecionar as métricas de qualidade na IU de avaliação do MLflow, identificar as causas principais por trás dos resultados de baixa qualidade e determinar como corrigir o problema subjacente. emitir. Depois de corrigir o problema, o desenvolvedor pode executar uma avaliação na nova versão do agente e comparar a qualidade com a versão anterior diretamente na IU de avaliação do MLFlow.
Implantação through Agent Framework
Depois de ter um agente que atenda aos seus requisitos de negócios em termos de qualidade, custo e latência, você pode implantar rapidamente uma API REST escalonável e pronta para produção e uma UI de bate-papo baseada na net usando uma linha de código por meio do Agent Framework: brokers.deploy(...).
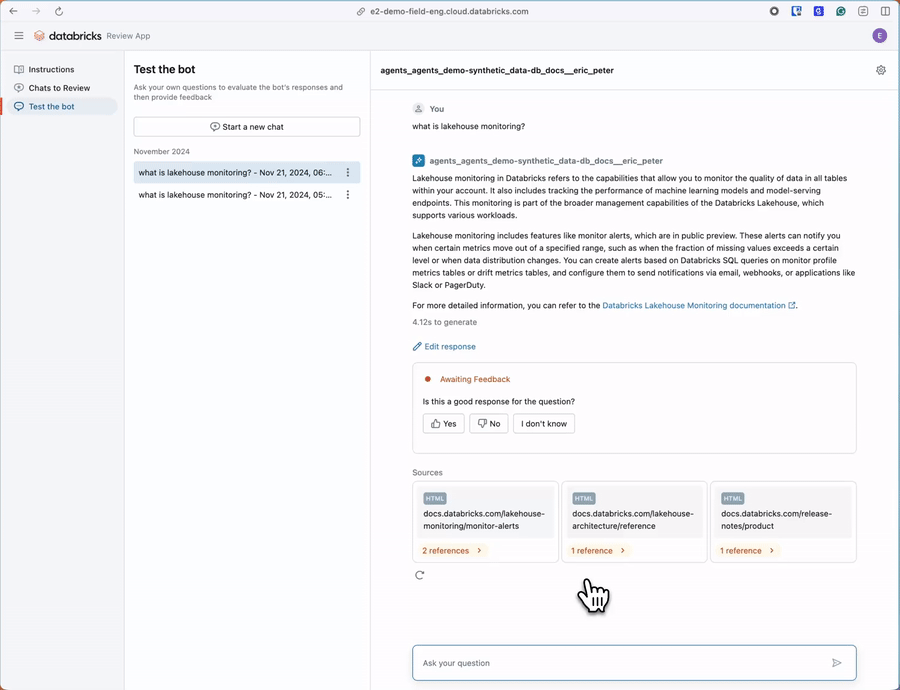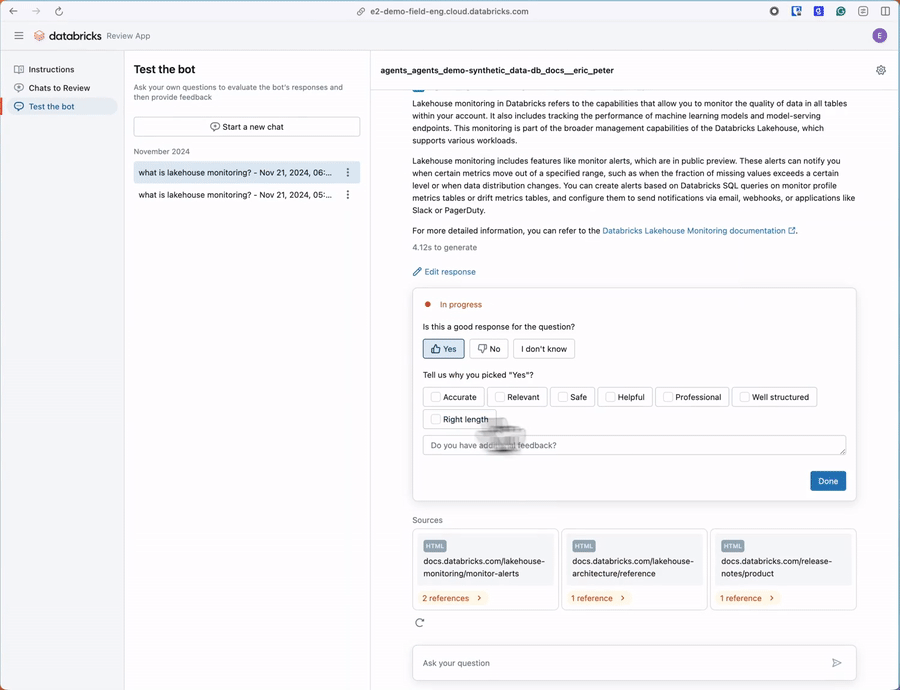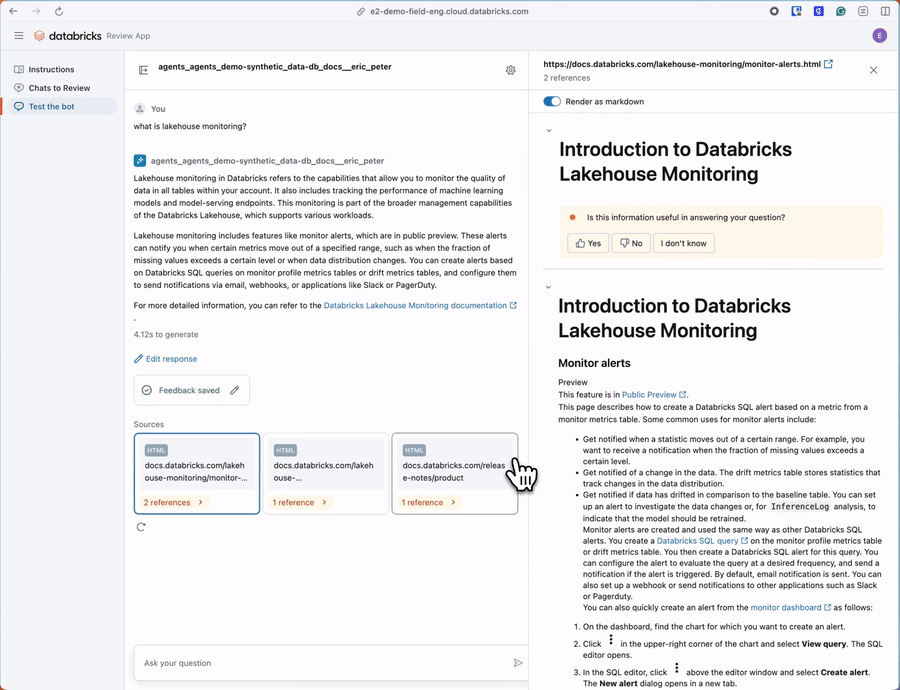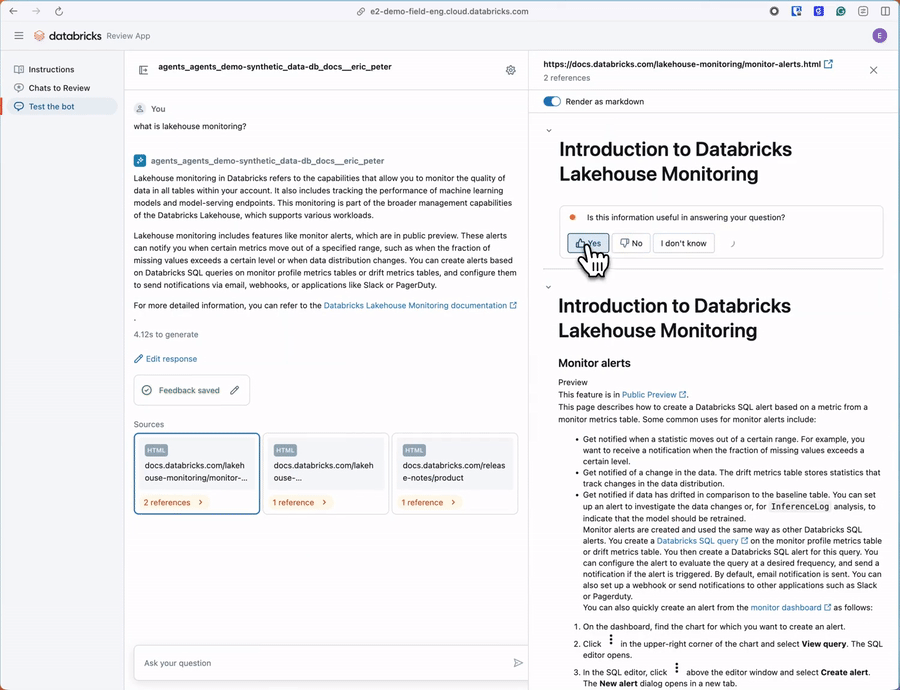
Comece com a geração de dados sintéticos
O que vem a seguir?
Estamos trabalhando em vários novos recursos para ajudá-lo a gerenciar conjuntos de dados de avaliação e coletar informações de suas PMEs.
A IU de revisão especializada no assunto é um novo recurso que permite que suas PMEs revisem rapidamente os dados de avaliação gerados sinteticamente para obter precisão e, opcionalmente, adicionem perguntas adicionais. Essas UIs são projetadas para tornar os especialistas de negócios eficientes no processo de revisão, garantindo que eles passem o mínimo de tempo longe de seus trabalhos diários.

O conjunto de dados de avaliação gerenciado é um serviço projetado para ajudar a gerenciar o ciclo de vida dos seus dados de avaliação. O serviço fornece uma Tabela Delta controlada por versão que permite que desenvolvedores e PMEs rastreiem o histórico de versão de seus registros de avaliação, por exemplo, as perguntas, informações básicas e metadados, como tags:
- Adicionado novo registro de avaliação
- Registro de avaliação alterado, por exemplo, pergunta, verdade básica, and many others.
- Registro de avaliação excluído
Alguns clientes já têm acesso a uma prévia desses recursos. Para se inscrever nesses recursos e em outras visualizações da Avaliação do Agente e da Estrutura do Agente, fale com sua equipe de conta ou preencha este formulário.