À medida que as empresas constroem sistemas de agentes para fornecer aplicativos de IA de alta qualidade, continuamos a fornecer otimizações para oferecer a melhor relação custo-benefício geral aos nossos clientes. Temos o prazer de anunciar a disponibilidade do modelo Meta Llama 3.3 no Plataforma de inteligência de dados Databrickse atualizações significativas no Mosaic AI Exibição de modelo preços e eficiência. Juntas, essas atualizações reduzirão seus custos de inferência em até 80%, tornando-o significativamente mais econômico do que antes para empresas que criam agentes de IA ou fazem processamento LLM em lote.
- 80% de economia de custos: Obtenha economias de custos significativas com o novo modelo Llama 3.3 e preços reduzidos.
- Velocidades de inferência mais rápidas: Obtenha respostas 40% mais rápidas e reduza o tempo de processamento em lote, proporcionando melhores experiências ao cliente e insights mais rápidos.
- Acesso ao novo modelo Meta Llama 3.3: aproveite o que há de mais recente no Meta para obter maior qualidade e desempenho.
Crie agentes empresariais de IA com Mosaic AI e Llama 3.3
Estamos orgulhosos da parceria com a Meta para trazer Lhama 3.3 70B para Databricks. Este modelo rivaliza com o maior Llama 3.1 405B em tarefas de acompanhamento de instruções, matemática, multilíngue e codificação, ao mesmo tempo que oferece uma solução econômica para chatbots de domínio específico, agentes inteligentes e processamento de documentos em grande escala.
Embora o Llama 3.3 estabeleça uma nova referência para modelos de base aberta, a construção de agentes de IA prontos para produção requer mais do que apenas um modelo poderoso. Databricks Mosaic AI é a plataforma mais abrangente para implantação e gerenciamento de modelos Llama, com um conjunto robusto de ferramentas para construir sistemas de agentes de IA seguros, escaláveis e confiáveis que podem raciocinar sobre seus dados corporativos.
- Acesse o Llama com uma API unificada: Acesse facilmente o Llama e outros modelos de base líderes, incluindo OpenAI e Anthropic, por meio de um interface única. Experimente, examine e alterne modelos sem esforço para obter máxima flexibilidade.
- Proteja e monitore o tráfego com o AI Gateway: Monitore o uso e a solicitação/resposta usando Gateway de IA do Mosaico ao mesmo tempo que aplica políticas de segurança como detecção de PII e filtragem de conteúdo prejudicial para interações seguras e compatíveis.
- Crie agentes em tempo actual mais rápidos: Crie agentes em tempo actual de alta qualidade com velocidades de inferência 40% mais rápidas, recursos de chamada de função e suporte para operações manuais ou automatizadas avaliação do agente.
- Processar fluxos de trabalho em lote em escala: Aplique LLMs facilmente para grandes conjuntos de dados diretamente em seus dados governados usando uma interface SQL simples, com velocidades de processamento 40% mais rápidas e tolerância a falhas.
- Personalize modelos para obter alta qualidade: Lhama de ajuste fino com dados proprietários para criar soluções específicas de domínio e de alta qualidade.
- Escale com confiança: Aumente as implantações com serviços apoiados por SLA, configurações seguras e soluções prontas para conformidade projetadas para serem escalonadas automaticamente de acordo com as crescentes demandas de sua empresa.
Tornando o GenAI mais acessível com novos preços:
Estamos implementando melhorias de eficiência proprietárias em nossa pilha de inferência, o que nos permite reduzir preços e tornar o GenAI ainda mais acessível a todos. Aqui está uma visão mais detalhada das novas mudanças de preços:
Reduções de preços de veiculação de pagamento por token:
- Modelo Llama 3.1 405B: redução de 50% no preço do token de entrada, redução de 33% no preço do token de saída.
- Modelo Llama 3.1 70B: redução de 50% para tokens de entrada e saída.
Reduções de preços de rendimento provisionado:
- Lhama 3.1 405B: Redução de custos de 44% por token processado.
- Llama 3.3 70B e Llama 3.1 70B: redução de 49% em dólares por whole de tokens processados.
Reduzindo o custo whole de implantação em 80%
Com o modelo Llama 3.3 70B mais eficiente e de alta qualidade, combinado com as reduções de preços, agora você pode obter uma redução de até 80% no seu TCO whole.
Vejamos um exemplo concreto. Suponha que você esteja construindo um agente chatbot de atendimento ao cliente projetado para lidar com 120 solicitações por minuto (RPM). Este chatbot processa uma média de 3.500 tokens de entrada e gera 300 tokens de saída por interação, criando respostas contextualmente ricas para os usuários.
Usando o Llama 3.3 70B, o custo mensal de execução deste chatbot, focado exclusivamente no uso do LLM, seria Custo 88% menor em comparação com Llama 3.1 405B e 72% mais econômico em comparação com os principais modelos proprietários.

Agora vamos dar uma olhada em um exemplo de inferência em lote. Para tarefas como classificação de documentos ou extração de entidades em um conjunto de dados de 100 mil registros, o modelo Llama 3.3 70B oferece eficiência notável em comparação com o Llama 3.1 405B. Processando linhas com 3.500 tokens de entrada e gerando 300 tokens de saída cada, o modelo atinge os mesmos resultados de alta qualidade enquanto reduzindo custos em 88%, isso é 58% mais econômico do que usar modelos proprietários líderes. Isso permite classificar documentos, extrair entidades-chave e gerar insights acionáveis em escala, sem despesas operacionais excessivas.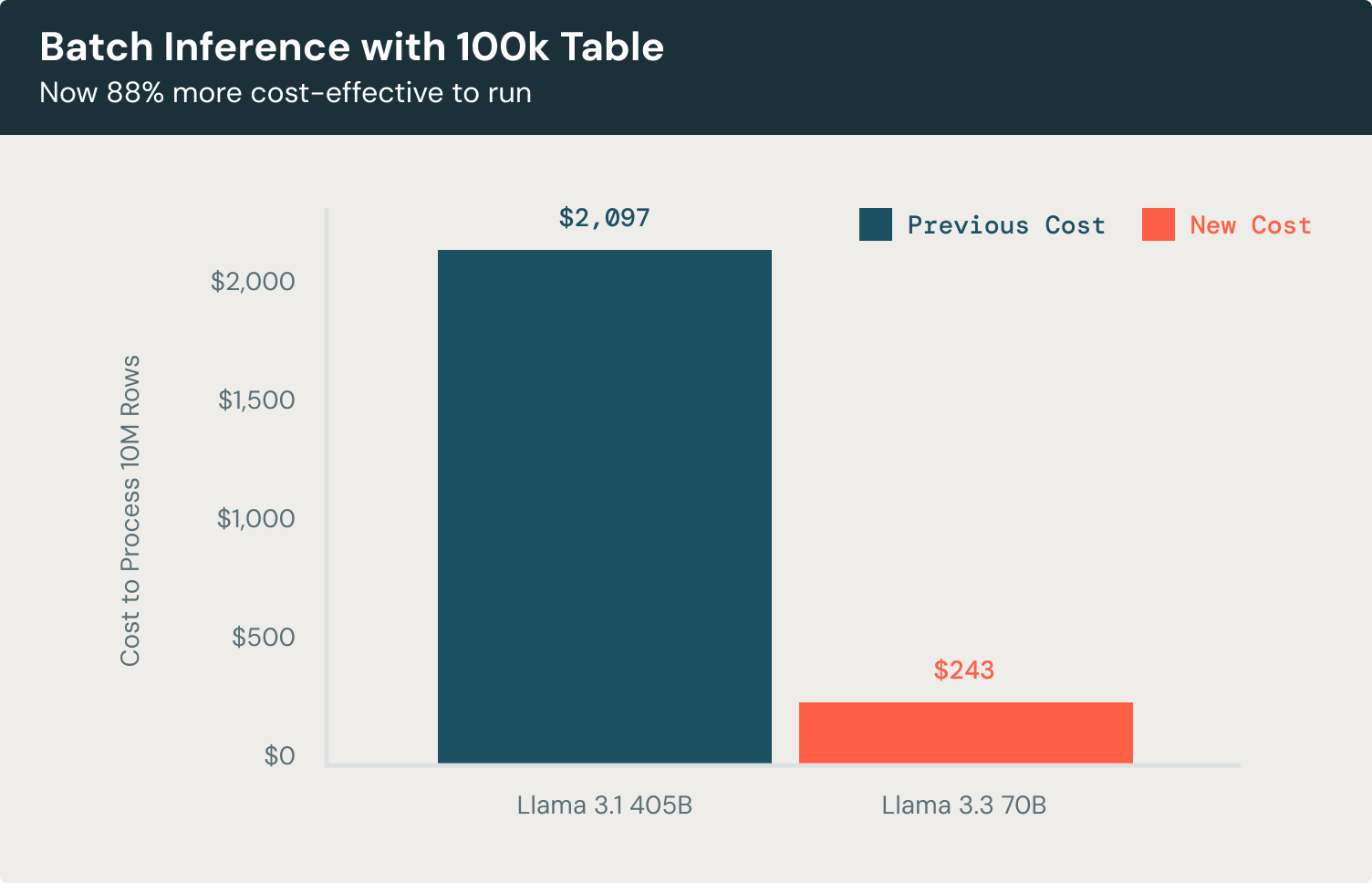
Comece hoje
Visite o Parque de IA para experimentar rapidamente o Llama 3.3 diretamente do seu espaço de trabalho. Para obter mais informações, consulte os seguintes recursos: