Rockset apresenta uma nova arquitetura que permite que instâncias virtuais separadas isolem a ingestão de streaming de consultas e um aplicativo de outro. A separação entre computação na nuvem oferece novas eficiências para análises em tempo actual em escala, com dados compartilhados em tempo actual, zero contenção de computação, aumento ou redução rápida e escalabilidade de simultaneidade ilimitada.
O problema da contenção computacional
A análise em tempo actual, incluindo mecanismos de personalização, aplicativos de rastreamento logístico e aplicativos de detecção de anomalias, é um desafio para escalar com eficiência. Os aplicativos de dados competem constantemente pelo mesmo conjunto de recursos computacionais para suportar gravações de streaming de alto quantity, consultas de baixa latência e cargas de trabalho de alta simultaneidade. Como resultado, surge a contenção computacional, causando vários problemas para clientes e clientes potenciais:
- A análise voltada ao usuário em meu aplicativo SaaS só pode ser atualizada a cada 30 minutos, pois o banco de dados subjacente fica instável sempre que tento processar dados de streaming continuamente.
- Quando meu website de comércio eletrônico realiza promoções, a enorme quantidade de gravações afeta o desempenho do meu mecanismo de personalização porque meu banco de dados não consegue isolar as gravações das leituras.
- Começamos a executar um único aplicativo de rastreamento logístico no cluster de banco de dados. No entanto, quando adicionamos um ETA em tempo actual e um aplicativo de roteamento automatizado, as cargas de trabalho adicionais degradaram o desempenho do cluster. Como solução alternativa, adicionei réplicas para isolamento, mas o custo adicional de computação e armazenamento é caro.
- O uso do meu aplicativo de jogos disparou no ano passado. Infelizmente, à medida que o número de usuários e consultas simultâneas em meu aplicativo aumenta, fui forçado a dobrar o tamanho do meu cluster, pois não há como adicionar mais recursos de forma incremental.
Com todos os cenários acima, as organizações devem provisionar recursos em excesso, criar réplicas para isolamento ou reverter para lotes.
Benefícios da separação computação-computação
Nesta nova arquitetura, as instâncias virtuais contêm a computação e a memória necessárias para a ingestão e consultas de streaming. Os desenvolvedores podem ativar ou desativar instâncias virtuais com base nos requisitos de desempenho de suas cargas de trabalho de ingestão ou consulta de streaming. Além disso, o Rockset fornece acesso rápido aos dados por meio do uso de armazenamento quente de melhor desempenho, enquanto o armazenamento em nuvem é usado para maior durabilidade. A capacidade da Rockset de explorar a nuvem torna possível o isolamento completo dos recursos computacionais.

A separação computação-computação oferece as seguintes vantagens:
- Isolamento de ingestão e consultas de streaming
- Vários aplicativos em dados compartilhados em tempo actual
- Dimensionamento de simultaneidade ilimitado
Isolamento de ingestão e consultas de streaming
Nas arquiteturas de banco de dados de primeira geração, incluindo Elasticsearch e Druid, os clusters contêm a computação e a memória para ingestão e consultas de streaming, causando contenção de computação. O Elasticsearch tentou resolver a contenção computacional criando nós de ingestão dedicados para transformar e enriquecer o documento, mas isso acontece antes da indexação, que ainda ocorre nos nós de dados junto com as consultas. A indexação e a compactação exigem muita computação e colocar essas cargas de trabalho em cada nó de dados impacta negativamente o desempenho da consulta.
Por outro lado, o Rockset permite múltiplas instâncias virtuais para isolamento computacional. O Rockset coloca operações de ingestão com uso intensivo de computação, incluindo indexação e manipulação de atualizações, na instância digital de ingestão de streaming e, em seguida, usa um log RocksDB CDC para enviar atualizações, inserções e exclusões para consultar instâncias virtuais. Como resultado, o Rockset é agora o único banco de dados analítico em tempo actual que isola a ingestão de streaming da computação de consulta sem a necessidade de criar réplicas.
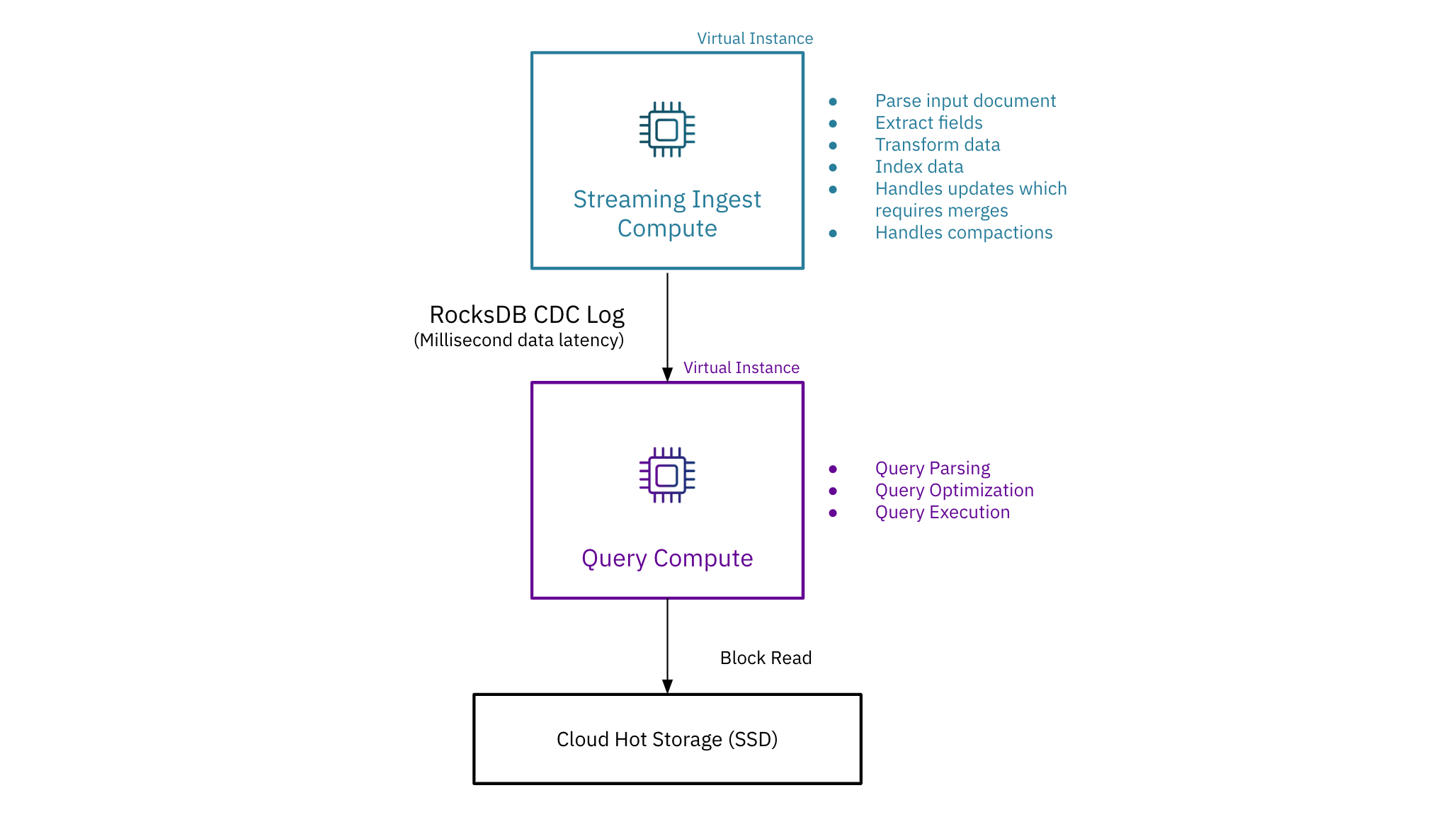
Vários aplicativos em dados compartilhados em tempo actual
Até este ponto, a separação entre armazenamento e computação dependia do armazenamento de objetos em nuvem, que é econômico, mas não consegue atender às demandas de velocidade da análise em tempo actual. Agora, os usuários podem executar vários aplicativos com dados de segundos, onde cada aplicativo é isolado e dimensionado com base em seus requisitos de desempenho. A criação de instâncias virtuais separadas, cada uma dimensionada de acordo com as necessidades do aplicativo, elimina a contenção de computação e a necessidade de provisionar recursos de computação em excesso para atender ao desempenho. Além disso, os dados compartilhados em tempo actual reduzem significativamente o custo do armazenamento a quente, pois é necessária apenas uma cópia dos dados.
Simultaneidade ilimitada
Os clientes podem dimensionar a instância digital para o desempenho de consulta desejado e, em seguida, ampliar a computação para cargas de trabalho de maior simultaneidade. Em outros sistemas que usam réplicas para escalonamento de simultaneidade, cada réplica precisa processar individualmente os dados recebidos do fluxo que exige muita computação. Isso também adiciona carga à fonte de dados, pois ela precisa dar suporte a diversas réplicas. O Rockset processa os dados de streaming uma vez e depois aumenta, deixando recursos de computação para execução de consultas.
Como funciona a separação computação-computação
Vamos ver como funciona a separação computação-computação usando streaming de dados do Twitter firehose para atender vários aplicativos:
- um aplicativo com os símbolos de cotação da bolsa mais tweetados
- um aplicativo com as hashtags mais tuitadas
Veja como será a arquitetura:
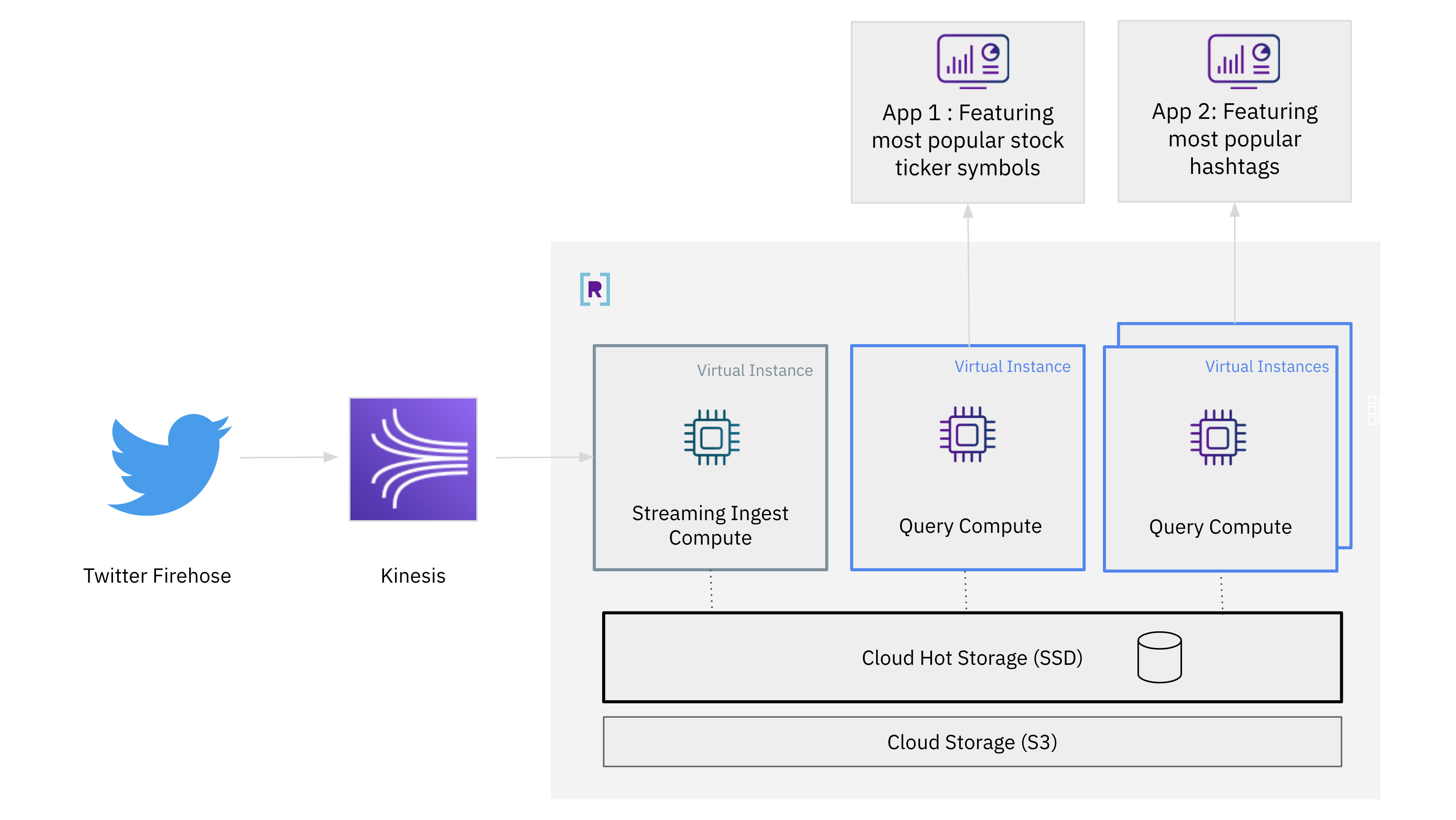
- Transmitiremos dados do Twitter Firehose para o Rockset usando a plataforma de streaming de eventos Amazon Kinesis
- Em seguida, criaremos uma coleção a partir dos dados do Twitter. A instância digital padrão será dedicada à ingestão de streaming neste exemplo.
- Em seguida, criaremos uma instância digital adicional para processamento de consultas. Esta instância digital encontrará os símbolos de cotações da bolsa mais tweetados no Twitter.
- Repetindo o mesmo processo, podemos criar outra instância digital para processamento de consultas. Esta instância digital encontrará as hashtags mais populares no Twitter.
- Expandiremos a escala para várias instâncias virtuais para lidar com cargas de trabalho de alta simultaneidade.
Etapa 1: crie uma coleção que sincronize dados do Twitter do Kinesis Stream
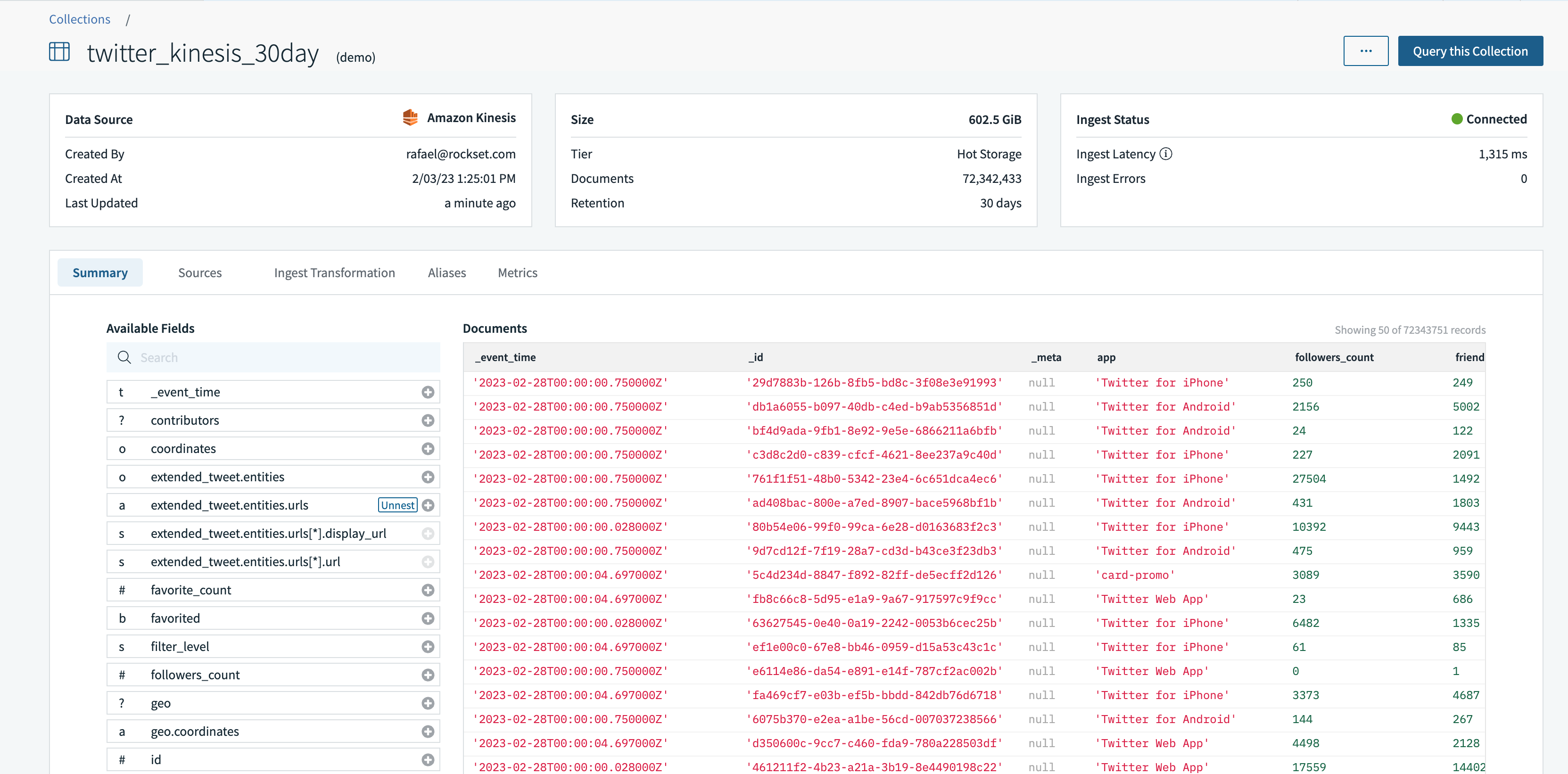
Em preparação para o passo a passo da separação computação-computação, configurei um integração com Amazon Kinesis usando funções IAM entre contas da AWS e chaves de acesso da AWS. Então usei a integração para criar uma coleção, twitter_kinesis_30dayque sincroniza dados do Twitter do stream do Kinesis.
No momento da criação da coleção, também posso criar transformações de ingestão, incluindo o uso de rollups SQL para agregar dados continuamente. Neste exemplo, usei transformações de ingestão para converter uma information como carimbo de information/hora, analisar um campo e extrair campos aninhados.
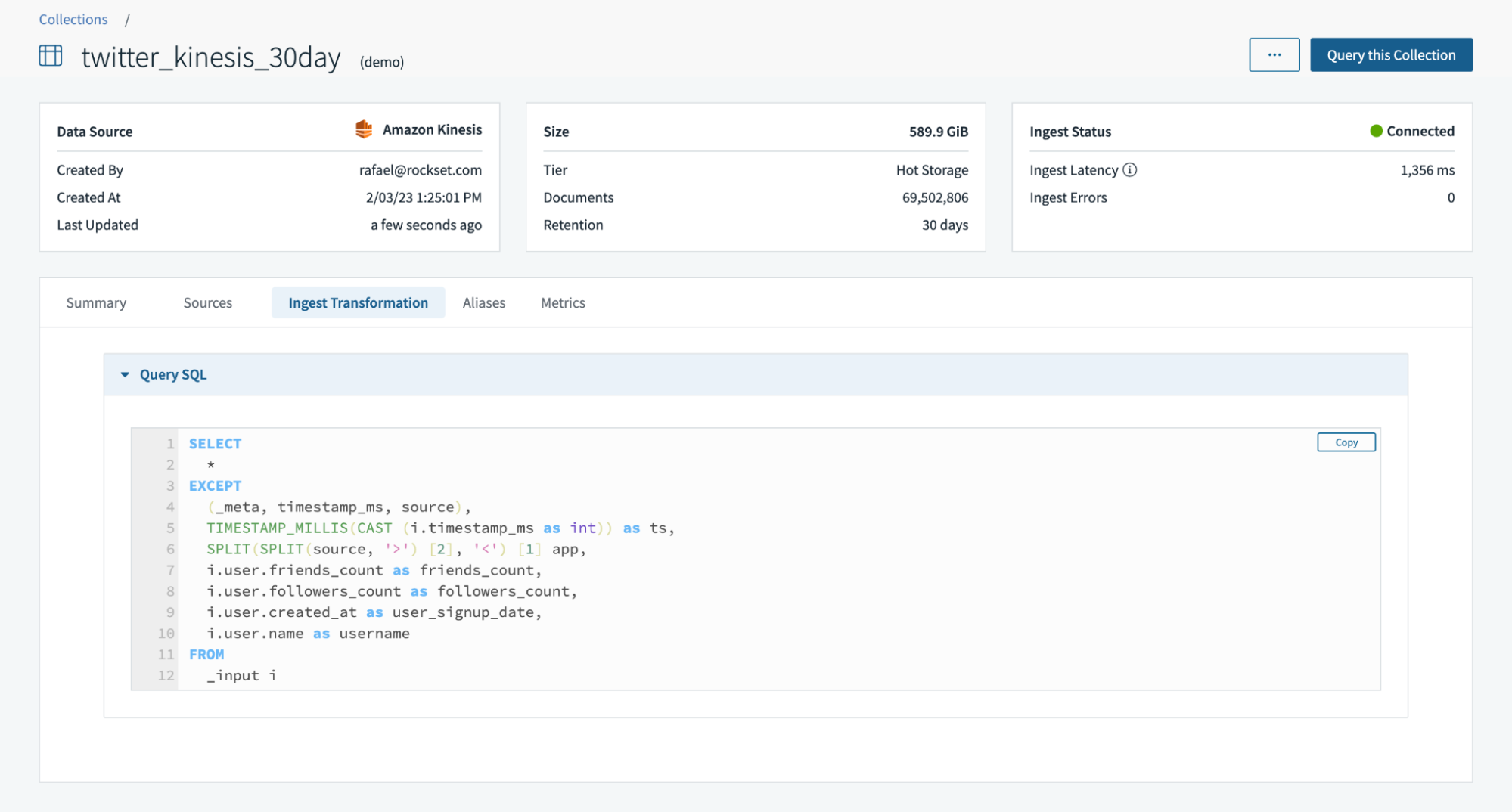
A instância digital padrão é responsável por transmitir a ingestão de dados e as transformações de ingestão.
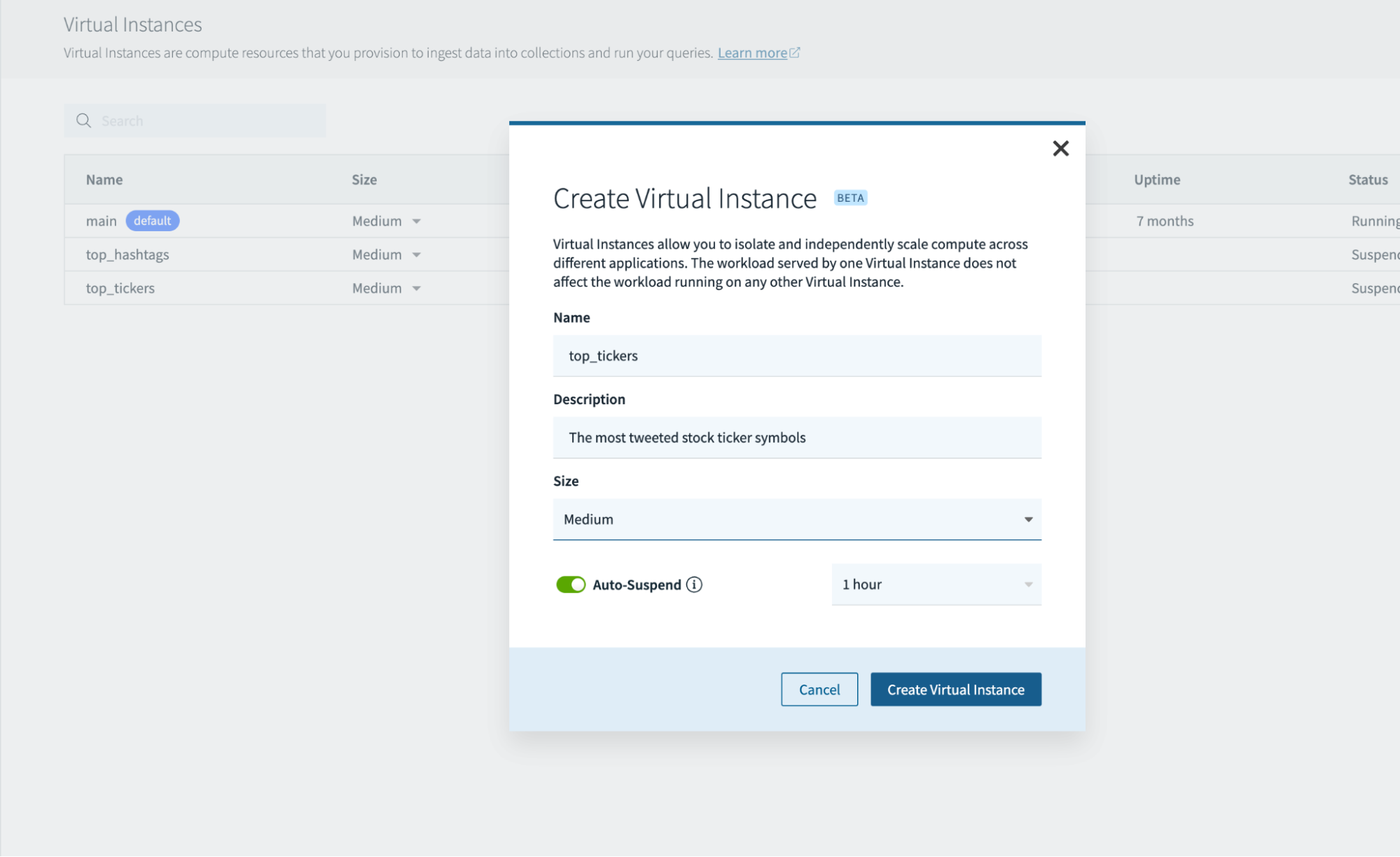
Etapa 2: criar várias instâncias virtuais
Indo para a guia de instâncias virtuais, agora posso criar e gerenciar várias instâncias virtuais, incluindo:
- alterando o número de recursos em uma instância digital
- montando ou associando uma instância digital a uma coleção
- definir a política de suspensão de uma instância digital para economizar recursos de computação
Neste cenário, quero isolar a computação de ingestão de streaming e a computação de consulta. Criaremos instâncias virtuais secundárias para atender consultas com:
- os símbolos de cotação da bolsa mais tweetados
- as hashtags mais tuitadas
A instância digital é dimensionada com base nos requisitos de latência do aplicativo. Também pode ser suspenso automaticamente devido à inatividade.
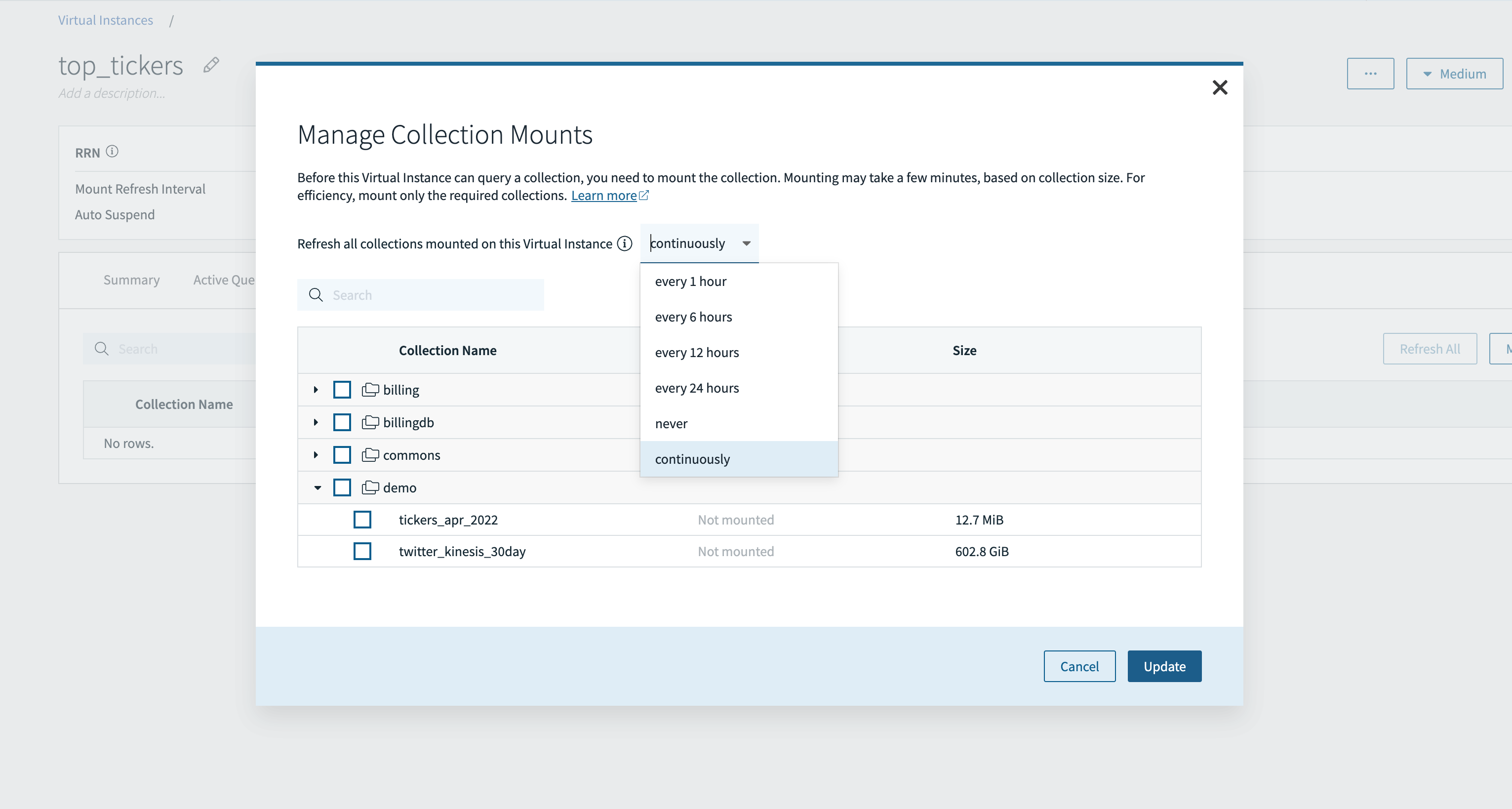
Etapa 3: montar coleções em instâncias virtuais
Antes de poder consultar uma coleção, primeiro preciso montar a coleção na instância digital.
Neste exemplo, montarei a coleção Twitter kinesis no top_tickers instância digital, para que eu possa executar consultas para encontrar os símbolos mais tweetados sobre as cotações da bolsa. Além disso, posso escolher uma atualização periódica ou contínua dependendo dos requisitos de latência de dados da minha aplicação. A opção de atualização contínua está atualmente disponível no acesso antecipado.
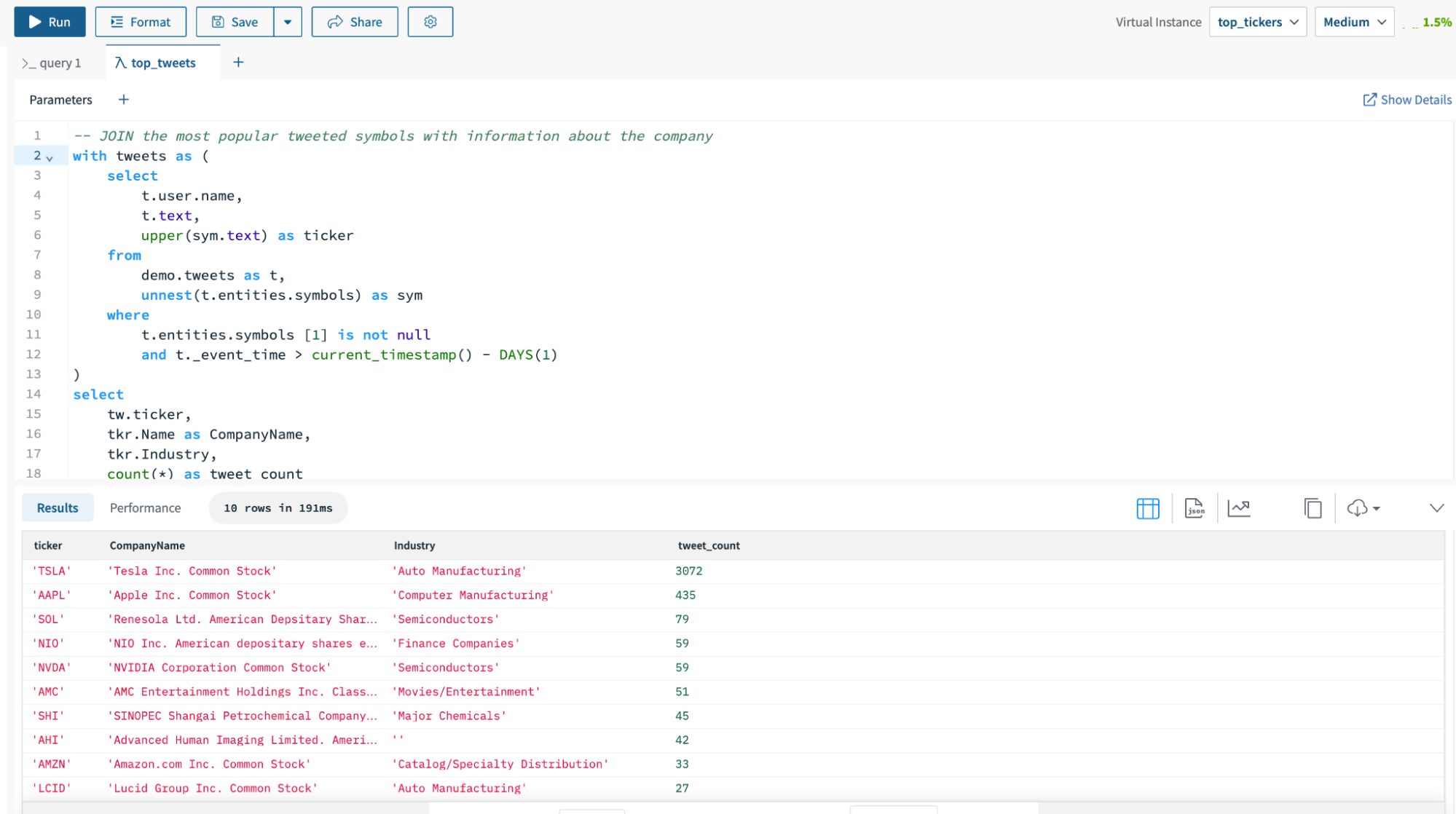
Etapa 4: executar consultas na instância digital
Irei ao editor de consultas para executar a consulta SQL no top_tickers instância digital.
Criei uma consulta SQL para encontrar os símbolos da bolsa com mais menções no Twitter nas últimas 24 horas. No canto superior direito do editor de consultas, selecionei a instância digital top_tickers para atender a consulta. Você pode ver que a consulta foi executada em 191 ms.
Etapa 5: Expandir para suportar cargas de trabalho de alta simultaneidade
Vamos agora expandir para dar suporte a cargas de trabalho de alta simultaneidade. No JMeter simulei 20 consultas por segundo e registrei uma latência média de 1613 ms para as consultas.
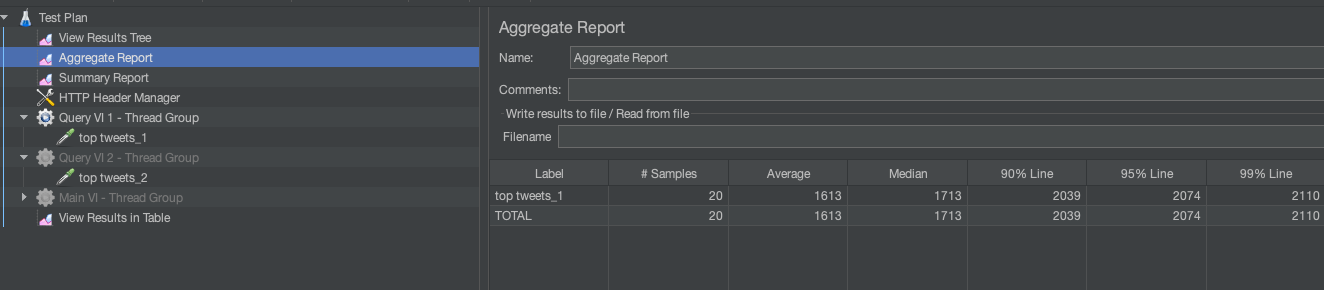
Se meu SLA para meu aplicativo for inferior a 1 segundo, desejarei aumentar a computação. Posso expandir instantaneamente e você pode ver que adicionar outra Instância Digital média reduziu a latência de 20 consultas para uma média de 457 ms.
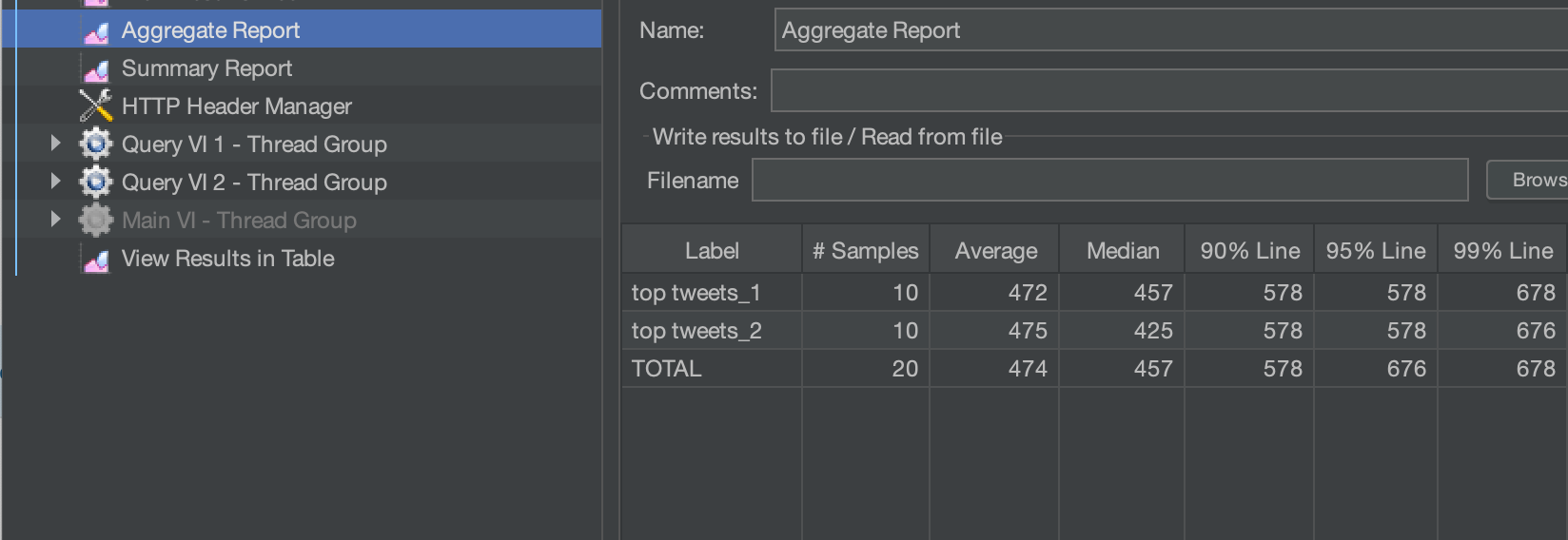
Discover a separação computação-computação
Exploramos como criar várias instâncias virtuais para ingestão de streaming, consultas de baixa latência e vários aplicativos. Com o lançamento da separação computação-computação na nuvem, estamos entusiasmados em tornar a análise em tempo actual mais eficiente e acessível. Experimente o beta público de separação computação-computação hoje, iniciando um teste gratuito do Rockset.