Neste artigo, focaremos em unidades recorrentes fechadas (GRAS)- uma alternativa mais direta e poderosa que ganhou tração por sua eficiência e desempenho.
Se você é novo para sequenciar modelagem ou procura aprimorar seu entendimento, este guia explicará como os Grus funcionam, onde eles brilham e por que eles importam no cenário de aprendizado profundo de hoje.
Em aprendizado profundonem todos os dados chegam em pedaços arrumados e independentes. Muito do que encontramos: linguagem, música, preços das ações, se desenrola com o tempo, com cada momento moldado pelo que veio antes. É aí que entra dados seqüenciais e, com eles, a necessidade de modelos que entendam contexto e memória.
Redes neurais recorrentes (RNNs) foram construídos para enfrentar o desafio de trabalhar com sequências, possibilitando que as máquinas sigam os padrões ao longo do tempo, como como as pessoas processam linguagem ou eventos.
Ainda assim, os RNNs tradicionais tendem a perder informações mais antigas, o que pode levar a previsões mais fracas. É por isso que modelos mais recentes como LSTMS e GRUS entraram em cena, projetados para melhor manter detalhes relevantes em sequências mais longas.
O que são Grus?
Unidades recorrentes fechadas, ou grus, são um tipo de Rede Neural Isso ajuda os computadores a entender as seqüências- coisas como frases, séries temporais ou até música. Diferentemente das redes padrão que tratam cada entrada separadamente, o Grus lembra o que veio antes, o que é basic quando o contexto é importante.

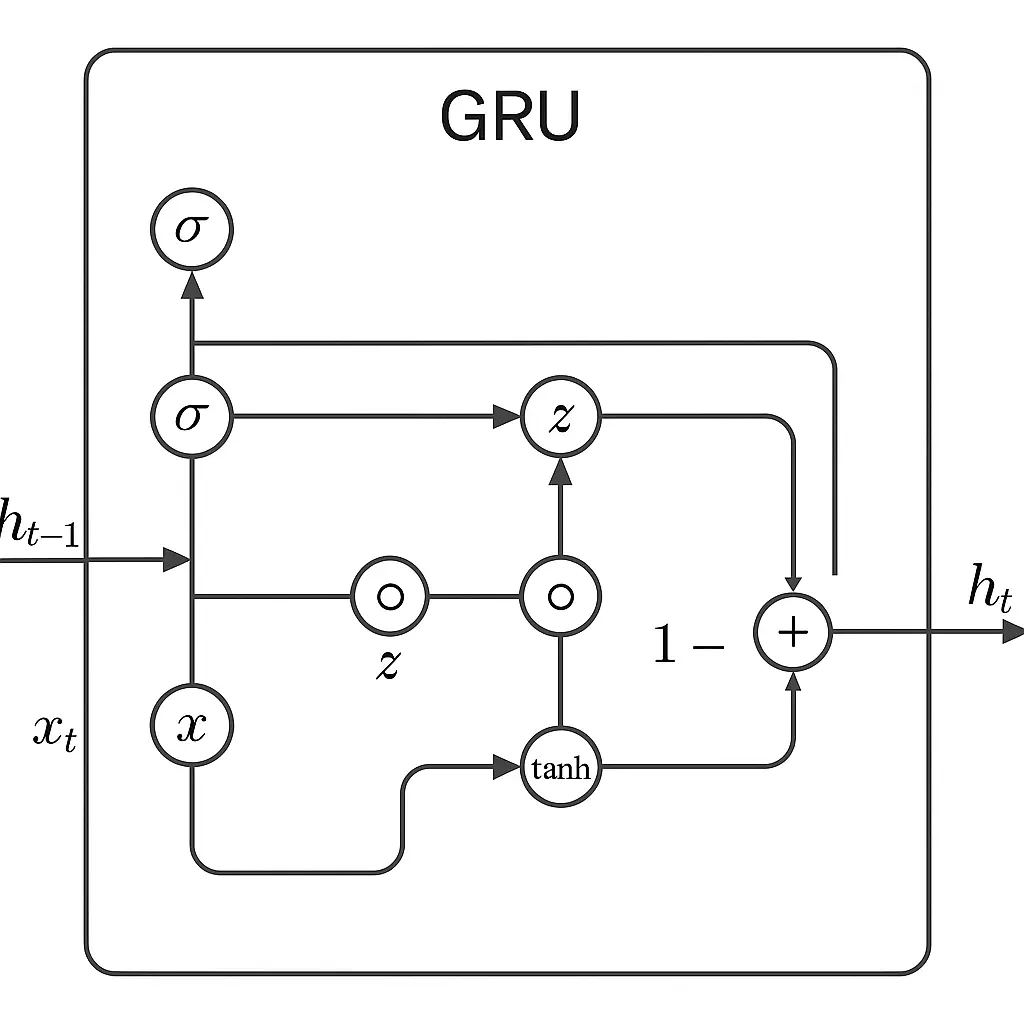
Grus trabalha usando dois “portões” principais para gerenciar informações. O portão de atualização resolve quanto do passado deve ser mantido por perto, e o portão de redefinição ajuda o modelo a descobrir quanto do passado esquecer quando vê uma nova entrada.
Esses portões permitem que o modelo se concentre no que é importante e ignore ruído ou dados irrelevantes.
À medida que novos dados entram, esses portões trabalham juntos para misturar o antigo e o novo de maneira inteligente. Se algo do início da sequência ainda importa, o GRU o mantém. Caso contrário, o GRU deixa ir.
Esse equilíbrio ajuda a aprender padrões ao longo do tempo sem ficar sobrecarregado.
Comparado aos LSTMs (memória de curto prazo longa), que usam três portões e uma estrutura de memória mais complexa, os grus são mais leves e rápidos. Eles não precisam de tantos parâmetros e geralmente são mais rápidos de treinar.
O GRUS tem um desempenho tão bom em muitos casos, especialmente quando o conjunto de dados não é enorme ou excessivamente complexo. Isso os torna uma escolha sólida para muitas tarefas profundas de aprendizado envolvendo sequências.
No geral, o Grus oferece uma mistura prática de poder e simplicidade. Eles foram projetados para capturar padrões essenciais em dados seqüenciais sem complicar demais, o que é uma qualidade que os torna eficazes e eficientes no uso do mundo actual.
Equações GRU e funcionamento
Uma célula GRU usa algumas equações importantes para decidir quais informações manter e o que descartar à medida que se transfer através de uma sequência. Gru combina informações antigas e novas com base no que os portões decidem. Isso permite manter o contexto prático em sequências longas, ajudando o modelo a entender as dependências que se estendem ao longo do tempo.
Diagrama Gru
Vantagens e limitações do Grus
Vantagens
- Grus tem uma reputação de ser simples e eficaz.
- Um de seus maiores pontos fortes é como eles lidam com a memória. Eles foram projetados para manter as coisas importantes do início em uma sequência, o que ajuda ao trabalhar com dados que se desenrolam ao longo do tempo, como idioma, áudio ou séries temporais.
- O Grus usa menos parâmetros do que alguns de seus colegas, especialmente LSTMs. Com menos peças móveis, elas treinam mais rapidamente e precisam de menos dados para continuar. Isso é ótimo quando com pouca computação ou trabalho com conjuntos de dados menores.
- Eles também tendem a convergir mais rápido. Isso significa que o processo de treinamento geralmente leva menos tempo para atingir um bom nível de precisão. Se você está em um ambiente onde a iteração rápida é importante, isso pode ser um benefício actual.
Limitações
- Nas tarefas em que a sequência de entrada é muito longa ou complexa, elas podem não ter um desempenho tão bom quanto o LSTMS. Os LSTMs têm uma unidade de memória additional que os ajuda a lidar com essas dependências mais profundas com mais eficiência.
- Grus também luta com sequências muito longas. Embora sejam melhores do que os RNNs simples, eles ainda podem perder as informações no início da entrada. Isso pode ser um problema se seus dados tiverem dependências distantes, como o início e o fim de um longo parágrafo.
Então, enquanto Grus atingiu um bom equilíbrio para muitos empregos, eles não são uma correção common. Eles brilham em configurações leves e eficientes, mas podem ficar aquém quando a tarefa exige mais memória ou nuance.
Aplicações de Grus em cenários do mundo actual
As unidades recorrentes fechadas (GRUS) estão sendo amplamente utilizadas em vários aplicativos do mundo actual devido à sua capacidade de processar dados seqüenciais.
- No processamento de linguagem pure (PNL), o GRUS ajuda com tarefas como tradução de máquinas e análise de sentimentos.
- Esses recursos são especialmente relevantes em práticos Projetos de PNL como chatbots, classificação de texto ou geração de idiomas, onde a capacidade de entender e responder a sequências desempenha um papel central significativo.
- Na previsão de séries temporais, as GRUs são especialmente úteis para prever tendências. Pense nos preços das ações, atualizações meteorológicas ou quaisquer dados que se movam em uma linha do tempo
- Grus pode entender os padrões e ajudar a fazer palpites inteligentes sobre o que está por vir.
- Eles são projetados para se apegar à quantidade certa de informações anteriores sem ficar atolado, o que ajuda a evitar problemas comuns de treinamento.
- No reconhecimento de voz, Grus ajuda a transformar palavras faladas em escritas. Como lidam bem com as sequências, eles podem se ajustar a diferentes estilos e sotaques, tornando a saída mais confiável.
- No mundo médico, o GRus está sendo usado para identificar padrões incomuns nos dados do paciente, como detectar batimentos cardíacos irregulares ou prever riscos à saúde. Eles podem peneirar os registros baseados no tempo e destacar coisas que os médicos podem não pegar imediatamente.
GRUS e LSTMS são projetados para lidar com dados seqüenciais, superando questões como os gradientes de fuga, mas cada um tem seus pontos fortes, dependendo da situação.
Quando escolher Grus em vez de LSTMs ou outros modelos
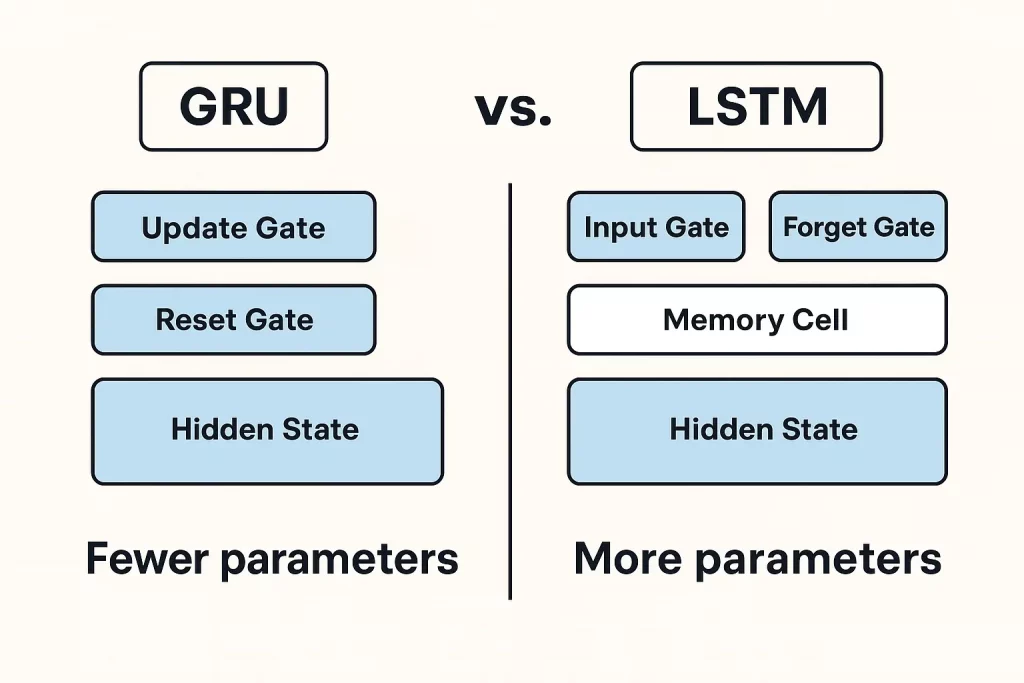
Tanto o GRus quanto o LSTMS são redes neurais recorrentes usadas para o processamento de sequências e são distinguidas entre si por complexidade e métricas computacionais.
A simplicidade deles, ou seja, menos parâmetros, o Grus treina mais rápido e usa menos poder computacional. Portanto, eles são amplamente aplicados em casos de uso em que a velocidade ofusca lidando com memórias grandes e complexas, por exemplo, análises on-line/ao vivo.
Eles são usados rotineiramente em aplicativos que exigem processamento rápido, como reconhecimento de fala ao vivo ou previsão on-the-fly, onde é essencial operação rápida e não uma análise complicada dos dados.
Pelo contrário, os LSTMs suportam os aplicativos que podem ser altamente dependentes do controle de memória de granulação fina, por exemplo, tradução da máquina ou análise de sentimentos. Existem portões de entrada, esquecimento e saída presentes nos LSTMs que aumentam sua capacidade de processar dependências de longo prazo com eficiência.
Embora exijam mais capacidade de análise, os LSTMs geralmente são preferidos para abordar as tarefas que envolvem sequências extensas e dependências complicadas, com o LSTMS sendo especialista em esse processamento de memória.
No geral, o Grus tem melhor desempenho em situações em que as dependências de sequência são moderadas e a velocidade é um problema, enquanto os LSTMs são melhores para aplicações que requerem memória detalhada e dependências complexas de longo prazo, embora com um aumento nas demandas computacionais.
Futuro de Gru em Deep Studying
Os Grus continuam a evoluir como componentes leves e eficientes em pipelines modernos de aprendizado profundo. Uma grande tendência é sua integração com arquiteturas baseadas em transformador, onde
GRUS são usados para codificar padrões temporais locais ou servir como módulos de sequência eficientes em modelos híbridos, especialmente em tarefas de série e séries temporais.
Gru + Atenção é outro paradigma crescente. Ao combinar o Grus com os mecanismos de atenção, os modelos ganham memória seqüencial e a capacidade de se concentrar em insumos importantes.
Esses híbridos são amplamente utilizados na tradução da máquina neural, previsão de séries temporais e detecção de anomalia.
Na frente de implantação, o GRus é splendid para dispositivos de borda e plataformas móveis devido à sua estrutura compacta e inferência rápida. Eles já estão sendo usados em aplicativos como reconhecimento de fala em tempo actual, monitoramento de saúde vestível e análise de IoT.
Os Grus também são mais passíveis de quantização e poda, tornando -os uma escolha sólida para Tinyml e IA incorporada.
Embora o GRus possa não substituir os transformadores em PNL em larga escala, eles permanecem relevantes em ambientes que exigem baixa latência, menos parâmetros e inteligência no dispositivo.
Conclusão
O Grus oferece uma mistura prática de velocidade e eficiência, tornando -as úteis para tarefas como reconhecimento de fala e previsão de séries temporais, especialmente quando os recursos são apertados.
Os LSTMs, embora mais pesados, lidam com padrões de longo prazo melhor e atendem a problemas mais complexos. Os transformadores estão ultrapassando os limites em muitas áreas, mas vêm com custos computacionais mais altos. Cada modelo tem seus pontos fortes, dependendo da tarefa.
Manter -se atualizado sobre pesquisas e experimentar abordagens diferentes, como combinar RNNs e mecanismos de atenção, podem ajudar a encontrar o ajuste certo. Programas estruturados que combinam a teoria com aplicativos de ciência de dados do mundo actual podem fornecer clareza e direção.
Ótimo aprendizado Programa PG em AI e aprendizado de máquina é uma dessas avenidas que pode fortalecer sua compreensão do aprendizado profundo e seu papel na modelagem de sequências.