Amazon Redshift suportes Dados de consulta armazenados usando tabelas Apache icebergum formato de tabela aberta que simplifica o gerenciamento de dados tabulares que residem nos lagos de dados em Amazon Easy Storage Service (Amazon S3). Tabelas Amazon S3 entrega o primeiro armazenamento de objetos em nuvem com suporte de iceberg embutido e linhas de otimização que armazenam dados tabulares em escala, incluindo otimizações contínuas de tabela que ajudam melhorar o desempenho da consulta. Amazon Sagemaker Lakehouse Unifica seus dados nos lagos de dados S3, incluindo tabelas S3 e Warehouses de dados do Amazon Redshift, ajuda a criar análises poderosas e inteligência synthetic e aprendizado de máquina (AI/ml) em uma única cópia de dados, consultando dados armazenados em tabelas S3 sem a necessidade de extrato complexo, transformação e carga (ETL) ou processos de dados. Você pode aproveitar a escalabilidade das tabelas S3 para armazenar e gerenciar grandes volumes de dados, otimizar os custos, evitando etapas adicionais de movimento de dados e simplificar o gerenciamento de dados por meio de controle de acesso de granulação fina centralizada do Sagemaker Lakehouse.
Neste submit, demonstramos como começar com as mesas S3 e Amazon Redshift sem servidor Para consultar dados em tabelas de iceberg. Mostramos como configurar tabelas S3, carregar dados, registrá -los no catálogo Unified Knowledge Lake, configurar controles básicos de acesso no Sagemaker Lakehouse através Formação do lago AWSe consulte os dados usando o Amazon Redshift.
Nota – o Amazon Redshift é apenas uma opção para consultar dados armazenados nas tabelas S3. Você pode aprender mais sobre tabelas S3 e maneiras adicionais de consultar e analisar dados sobre o Página do produto S3 Tabelas.
Visão geral da solução
Nesta solução, mostramos como consultar as mesas de iceberg gerenciadas em tabelas S3 usando o Amazon Redshift. Especificamente, carregamos um conjunto de dados em tabelas S3, vinculamos os dados nas tabelas S3 a um grupo de trabalho sem servidor Redshift com permissões apropriadas e, finalmente, executamos consultas para analisar nosso conjunto de dados para tendências e insights. O diagrama a seguir ilustra esse fluxo de trabalho.

Neste submit, passaremos pelas seguintes etapas:
- Crie um balde de tabela em tabelas S3 e integra -se a outros serviços de análise da AWS.
- Configure as permissões e crie mesas de iceberg com a Sagemaker Lakehouse usando a formação do lago.
- Carregar dados com Amazon Athena. Existem diferentes maneiras de ingerir dados nas tabelas S3, mas para este submit, mostramos como podemos começar rapidamente com Athena.
- Use o Amazon Redshift para consultar suas mesas de iceberg armazenadas em mesas S3 através do catálogo montado automático.
Pré -requisitos
Os exemplos desta postagem exigem que você use os seguintes serviços e recursos da AWS:
Crie um balde de mesa em mesas S3
Antes de usar o Amazon Redshift para consultar os dados nas tabelas S3, você deve primeiro criar um balde de tabela. Full as seguintes etapas:
- No console Amazon S3, escolha Baldes de mesa no painel de navegação esquerda.
- No Integração com serviços de análise da AWS Seção, escolha Ativar integração Se você não configurou isso anteriormente.
Isso configura a integração com os serviços de análise da AWS, incluindo o Amazon Redshift, Amazon emre Athena.

Depois de alguns segundos, o standing mudará para Habilitado.

- Escolher Crie o balde de tabela.
- Digite um nome de balde. Para este exemplo, usamos o nome do balde
redshifticeberg. - Escolher Crie o balde de tabela.

Depois que o balde de tabela S3 for criado, você será redirecionado para a lista de baldes da tabela.

Agora que o seu balde de mesa é criado, o próximo passo é configurar o catálogo unificado em Sagemaker Lakehouse através do Console de Formação do Lago. Isso disponibilizará o balde de mesa em mesas S3 para o Amazon Redshift para consultar mesas de iceberg.
Publicação de mesas de iceberg em mesas S3 para Sagemaker Lakehouse
Antes de poder consultar as mesas de iceberg nas mesas S3 com o Amazon Redshift, você deve primeiro disponibilizar o balde de mesa no catálogo unificado em Sagemaker Lakehouse. Você pode fazer isso através do console de formação do lago, o que permite Publique catálogos e gerencie mesas Através do recurso Catálogo e atribua permissões aos usuários. As etapas a seguir mostram como configurar a formação do lago para que você possa usar o Amazon Redshift para consultar mesas de iceberg no seu balde de mesa:
- Se você nunca visitou o console de formação do lago antes, primeiro deve fazê -lo como usuário da AWS com permissões de administrador para ativar a formação do lago.
Você será redirecionado para o Catálogos Página no console de formação do lago. Você verá que um dos catálogos disponíveis é o s3tablescatalogque mantém um catálogo dos baldes de mesa que você criou. As etapas a seguir configurarão a formação do lago para fazer dados no s3tablescatalog Catálogo disponível para o Amazon Redshift.

Em seguida, você precisa criar um banco de dados na formação do lago. O banco de dados de formação do lago mapeia para um esquema de desvio para o vermelho.
- Escolher Bancos de dados sob Catálogo de dados no painel de navegação.
- No Criar menu, escolha Banco de dados.

- Digite um nome para este banco de dados. Este exemplo usa
icebergsons3. - Para Catálogoescolha o balde de tabela que você criou. Neste exemplo, o nome terá o formato
:s3tablescatalog/redshifticeberg - Escolher Crie banco de dados.

Você será redirecionado no console de formação do lago para uma página com mais informações sobre seu novo banco de dados. Agora você pode criar uma mesa de iceberg nas tabelas S3.
- Na página Detalhes do banco de dados, na Visualizar menu, escolha Mesas.

Isso abrirá uma nova janela do navegador com o editor de tabela para este banco de dados.
- Após a transmissão da tabela, escolha, escolha Criar tabela Para começar a criar a tabela.

- No editor, digite o nome da tabela. Nós chamamos esta tabela
examples. - Escolha o catálogo (
:s3tablescatalog/redshifticeberg icebergsons3).

Em seguida, adicione colunas à sua mesa.
- No Esquema Seção, escolha Adicione colunae adicione uma coluna que represente um ID.

- Repita esta etapa e adicione colunas para dados adicionais:
category_id(longo)insert_date(knowledge)knowledge(corda)
O esquema ultimate se parece com a seguinte captura de tela.

- Escolher Enviar Para criar a tabela.
Em seguida, você precisa configurar uma permissão somente leitura para poder consultar dados de iceberg em tabelas S3 usando o Amazon Redshift Consulta Editor V2. Para mais informações, consulte Pré -requisitos para gerenciar namespaces de desvio para o Amazon no catálogo de dados da AWS Glue.
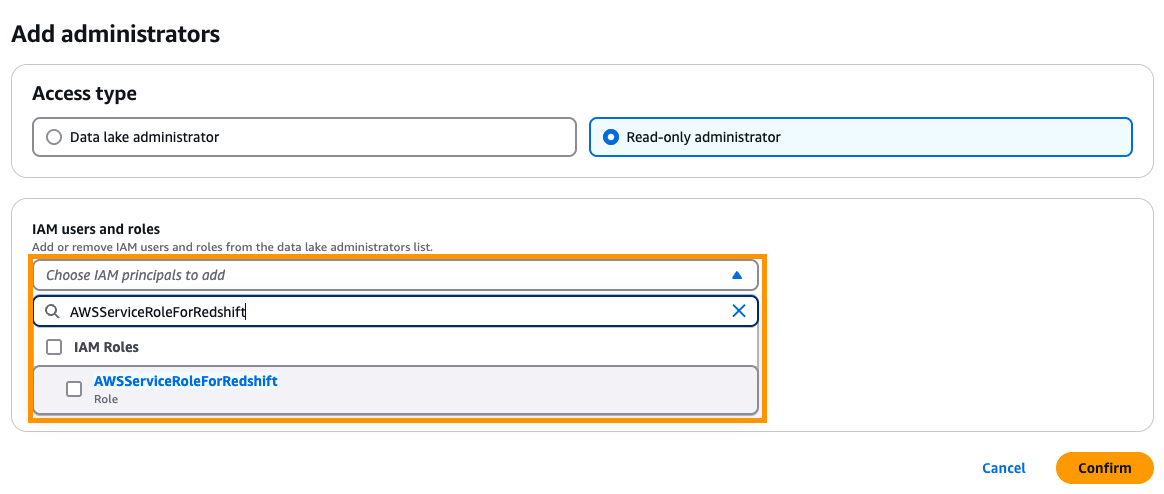
- Sob Administração No painel de navegação, escolha Funções e tarefas administrativas.
- No Administradores de Knowledge Lake Seção, escolha Adicionar.

- Para Tipo de acessoselecione Administrador somente leitura.
- Para Usuários e funções do IAMdigitar
AWSServiceRoleForRedshift.
AWSServiceRoleForRedshift é a função vinculada ao serviço Isso é gerenciado pela AWS.
- Escolher Confirmar.
Agora você configurou o Sagemaker Lakehouse usando a formação do lago para permitir que o Amazon Redshift consulte as mesas de iceberg nas mesas S3. Em seguida, você preenche alguns dados na tabela de iceberg e consulte -os com o Amazon Redshift.
Use SQL para consultar dados de iceberg com Amazon Redshift
Para este exemplo, usamos Athena para carregar dados em nossa tabela de iceberg. Esta é uma opção para ingerir dados em uma tabela de iceberg; ver Usando tabelas Amazon S3 com serviços de análise da AWS Para outras opções, incluindo Amazon emr com faíscaAssim, Amazon Knowledge Firehosee AWS GULE ETL.
- No console Athena, navegue até o editor de consultas.
- Se esta é a sua primeira vez usando Athena, você deve primeiro Especifique um native de resultado da consulta Antes de executar sua primeira consulta.
- No editor de consultas, sob Dadosescolha sua fonte de dados (
AwsDataCatalog). - Para Catálogoescolha o balde de mesa que você criou (
s3tablescatalog/redshifticeberg). - Para Banco de dadosescolha o banco de dados que você criou (
icebergsons3).

- Vamos executar uma consulta para gerar dados para a tabela de exemplos. A consulta a seguir gera mais de 1,5 milhão de linhas correspondentes a 30 dias de dados. Insira a consulta e escolha Correr.
A captura de tela a seguir mostra nossa consulta.

A consulta leva cerca de 10 segundos para executar.
Agora você pode usar o Redshift sem servidor para consultar os dados.
- No console sem servidor Redshift, forneça um grupo de trabalho sem servidor Redshift, se você ainda não o fez. Para instruções, veja Comece com o Amazon Redshift Sem servidor Knowledge Warehouses guia. Neste exemplo, usamos um grupo de trabalho sem servidor Redshift chamado
iceberg. - Certifique -se de que sua versão do Amazon Redshift Patch seja o patch 188 ou superior.

- Escolher Dados de consulta Para abrir o Amazon Redshift Question Editor V2.

- No editor de consultas, escolha o grupo de trabalho que você deseja usar.
Uma janela pop-up aparecerá, solicitando qual usuário usar.
- Selecione Usuário federadoque usará sua conta corrente e escolherá Criar conexão.

Levará alguns segundos para iniciar a conexão. Quando estiver conectado, você verá uma lista de bancos de dados disponíveis.
- Escolher Bancos de dados externos.
Você verá o balde de mesa das tabelas S3 na vista (neste exemplo, este é redshifticeberg@s3tablescatalog).
- Se você continuar clicando na árvore, verá o
examplesTabela, que é a mesa de iceberg que você criou anteriormente que é armazenada no balde de mesa.

Agora você pode usar o Amazon Redshift para consultar a mesa do iceberg nas mesas S3.
Antes de executar a consulta, revise a sintaxe do Amazon Redshift para Catálogos de consulta registrados em Sagemaker Lakehouse. O Amazon Redshift usa a seguinte sintaxe para fazer referência a uma tabela: database@namespace.schema.desk ou database@namespace".schema.desk.
Neste exemplo, usamos a seguinte sintaxe para consultar o examples Tabela no balde da tabela: redshifticeberg@s3tablescatalog.icebergsons3.examples.
Saiba mais sobre esse mapeamento Usando tabelas Amazon S3 com serviços de análise da AWS.
Vamos executar algumas consultas. Primeiro, vamos ver quantas linhas estão na tabela de exemplos.
- Execute a seguinte consulta no editor de consultas:
A consulta levará alguns segundos para executar. Você verá o seguinte resultado.

Vamos tentar uma consulta um pouco mais complicada. Nesse caso, queremos encontrar todos os dias que tiveram dados de exemplo começando com 0.2 e a category_id entre 50 a 75 com pelo menos 130 linhas. Pediremos os resultados da maioria para menos.
- Execute a seguinte consulta:
Você pode ver resultados diferentes das seguintes capturas de tela devido aos dados de origem gerados aleatoriamente.

Parabéns, você configurou e consultou dados de iceberg em tabelas S3 da Amazon Redshift!
Limpar
Se você implementou o exemplo e deseja remover os recursos, full as seguintes etapas:
- Se você não precisar mais do seu grupo de trabalho sem servidor Redshift, Exclua o grupo de trabalho.
- Se você não precisar acessar os dados do Sagemaker Lakehouse do Amazon Redshift Question Editor V2, remova o Administrador do Knowledge Lake:
- No console de formação do lago, escolha Funções e tarefas administrativas no painel de navegação.
- Remova o administrador de dados apenas de dados somente leitura que possui o
AWSServiceRoleForRedshiftprivilégio.
- Se você deseja excluir permanentemente os dados deste submit, exclua o banco de dados:
- No console de formação do lago, escolha Bancos de dados no painel de navegação.
- Exclua o
icebergsaheadbanco de dados.
- Se você não precisar mais do balde de mesa, Exclua o balde de mesa.
- Em você deseja desativar a integração entre tabelas S3 e serviços de análise da AWS, consulte Migrando para o processo de integração atualizado.
Conclusão
Neste submit, mostramos como começar o Amazon Redshift para consultar mesas de iceberg armazenadas em mesas S3. Este é apenas o começo de como você pode usar o Amazon Redshift para analisar seus dados de iceberg armazenados em tabelas S3-você pode combinar isso com outros recursos do Amazon Redshift, incluindo consultas de gravação que ingressam em dados de tabelas de tabelas de iceberg que oferecem tabelas de s3 e controles de controle de REDs para o RELMs para o S3, para o S3, o S3 Management Storage (RMS) ou implementam controles de acesso aos dados. Além disso, você pode usar recursos como o Redshift sem servidor para selecionar automaticamente a quantidade de computação para analisar suas tabelas de iceberg e usar a IA para escalar de forma inteligente sob demanda e otimizar as características de desempenho da consulta para sua carga de trabalho analítica.
Convidamos você a deixar suggestions nos comentários.
Sobre os autores
 Jonathan Katz é gerente de produto principal – técnico na equipe do Amazon Redshift e está sediada em Nova York. Ele é um membro da equipe central do projeto PostgreSQL de código aberto e um colaborador ativo de código aberto, incluindo o PostgreSQL e o projeto PGVector.
Jonathan Katz é gerente de produto principal – técnico na equipe do Amazon Redshift e está sediada em Nova York. Ele é um membro da equipe central do projeto PostgreSQL de código aberto e um colaborador ativo de código aberto, incluindo o PostgreSQL e o projeto PGVector.
 Satesh Sonti é um arquiteto de soluções especializadas em análise de análise sediada em Atlanta, especializada na construção de plataformas de dados empresariais, soluções de knowledge warehousing e análise. Ele tem mais de 19 anos de experiência na construção de ativos de dados e liderando programas complexos de plataforma de dados para clientes bancários e de seguros em todo o mundo.
Satesh Sonti é um arquiteto de soluções especializadas em análise de análise sediada em Atlanta, especializada na construção de plataformas de dados empresariais, soluções de knowledge warehousing e análise. Ele tem mais de 19 anos de experiência na construção de ativos de dados e liderando programas complexos de plataforma de dados para clientes bancários e de seguros em todo o mundo.