Tl; dr
Os sistemas LLM-AS-A-JUDGE podem ser enganados por respostas confiantes, mas erradas, dando às equipes falsas confiança em seus modelos. Construímos um conjunto de dados etiquetado por humanos e usamos nossa estrutura de código aberto Syftr Para testar sistematicamente as configurações do juiz. Os resultados? Eles estão no publish completo. Mas aqui está o take -away: não confie apenas no seu juiz – teste -o.
Quando mudamos para modelos de código aberto auto-hospedado para nossa estrutura de geração agente-upentada por recuperação agêntica (RAG), ficamos emocionados com os resultados iniciais. Em benchmarks difíceis como o Financebench, nossos sistemas pareciam oferecer precisão inovadora.
Essa emoção durou até que olhamos mais de perto para como Nosso sistema LLM-AS-A-JUDGE estava classificando as respostas.
A verdade: Nossos novos juízes estavam sendo enganados.
Um sistema de pano, incapaz de encontrar dados para calcular uma métrica financeira, simplesmente explicaria que não conseguia encontrar as informações.
O juiz recompensaria essa explicação plausível com crédito complete, concluindo que o sistema tinha corretamente identificou a ausência de dados. Essa única falha foi Resultados de distorção em 10 a 20% -O suficiente para fazer com que um sistema medíocre pareça de ponta.
O que levantou uma questão crítica: se você não pode confiar no juiz, como pode confiar nos resultados?
Seu juiz LLM pode estar mentindo para você, e você não saberá a menos que você o teste rigorosamente. O melhor juiz nem sempre é o maior ou mais caro.
Com os dados e ferramentas certos, no entanto, você pode criar um mais barato, mais preciso e mais confiável que o GPT-4O-Mini. Nesta pesquisa, mergulho profundo, mostramos como.
Por que os juízes llm falham
O desafio que descobrimos foi muito além de um bug simples. A avaliação do conteúdo gerado é inerentemente sutil e os juízes do LLM são propensos a falhas sutis, mas conseqüentes.
Nossa questão inicial foi um caso de livro de um juiz sendo influenciado pelo raciocínio que soa confiante. Por exemplo, em uma avaliação sobre uma árvore genealógica, o juiz concluiu:
“A resposta gerada é relevante e identifica corretamente que não há informações suficientes para determinar o primo específico … Embora a resposta de referência lista nomes, a conclusão da resposta gerada se alinha ao raciocínio de que a pergunta não possui dados necessários”.
Na realidade, a informação period Disponível – o sistema de pano não conseguiu recuperá -lo. O juiz foi enganado pelo tom autoritário da resposta.
Cavando mais fundo, encontramos outros desafios:
- Ambiguidade numérica: Uma resposta de 3,9% é “próxima o suficiente” para 3,8%? Os juízes geralmente não têm o contexto para decidir.
- Equivalência semântica: “APAC” é um substituto aceitável para “Ásia-Pacífico: Índia, Japão, Malásia, Filipinas, Austrália”?
- Referências defeituosas: Às vezes, a resposta da “verdade do solo” está errada, deixando o juiz em um paradoxo.
Essas falhas ressaltam uma lição importante: simplesmente escolher um poderoso LLM e pedir que ela classifique não é suficiente. O acordo perfeito entre juízes, humanos ou máquina, é inatingível sem uma abordagem mais rigorosa.
Construindo uma estrutura para a confiança
Para enfrentar esses desafios, precisávamos de uma maneira de Avalie os avaliadores. Isso significava duas coisas:
- Um conjunto de dados de julgamentos de alta qualidade e marcado humano.
- Um sistema para testar metodicamente diferentes configurações de juízes.
Primeiro, criamos nosso próprio conjunto de dados, agora disponível em Huggingface. Geramos centenas de trigêmeos de resposta à resposta à resposta usando uma ampla gama de sistemas de pano.
Em seguida, nossa equipe marcou todos os 807 exemplos.
Todo caso de borda foi debatido e estabelecemos regras claras e consistentes de classificação.
O processo em si foi revelador, mostrando como pode ser a avaliação subjetiva. No last, nosso conjunto de dados rotulado refletia uma distribuição de 37,6% falhando e 62,4% de passagem respostas.

Em seguida, precisávamos de um motor para experimentação. É aí que nossa estrutura de código aberto, Syftrentrou.
Nós o estendemos com uma nova classe Judgeflow e um espaço de pesquisa configurável para variar a escolha, a temperatura e o design imediato. Isso possibilitou explorar sistematicamente – e identificar – as configurações do juiz mais alinhadas com o julgamento humano.
Colocando os juízes à prova
Com nossa estrutura em vigor, começamos a experimentar.
Nosso primeiro teste se concentrou no Grasp-rm Modelo, especificamente sintonizado para evitar “hackers de recompensa”, priorizando o conteúdo sobre frases de raciocínio.
Nós o colocamos contra seu modelo básico usando quatro avisos:
- O “padrão” Llamaindex CorrectionSevaluator rápido, pedindo uma classificação de 1 a 5
- O mesmo immediate de correção de correção, solicitando uma classificação de 1 a ten
- Uma versão mais detalhada do immediate de correção do EXCORCIONEVALATOR com critérios mais explícitos.
- Um aviso simples: “Retorne sim se a resposta gerada estiver correta em relação à resposta de referência ou não, se não for.”
O Syftr Os resultados da otimização são mostrados abaixo no gráfico de custo versus a precisão. Precisão é a porcentagem simples de acordo entre o juiz e os avaliadores humanos, e o custo é estimado com base no preço por token de Juntos.aiOs serviços de hospedagem.
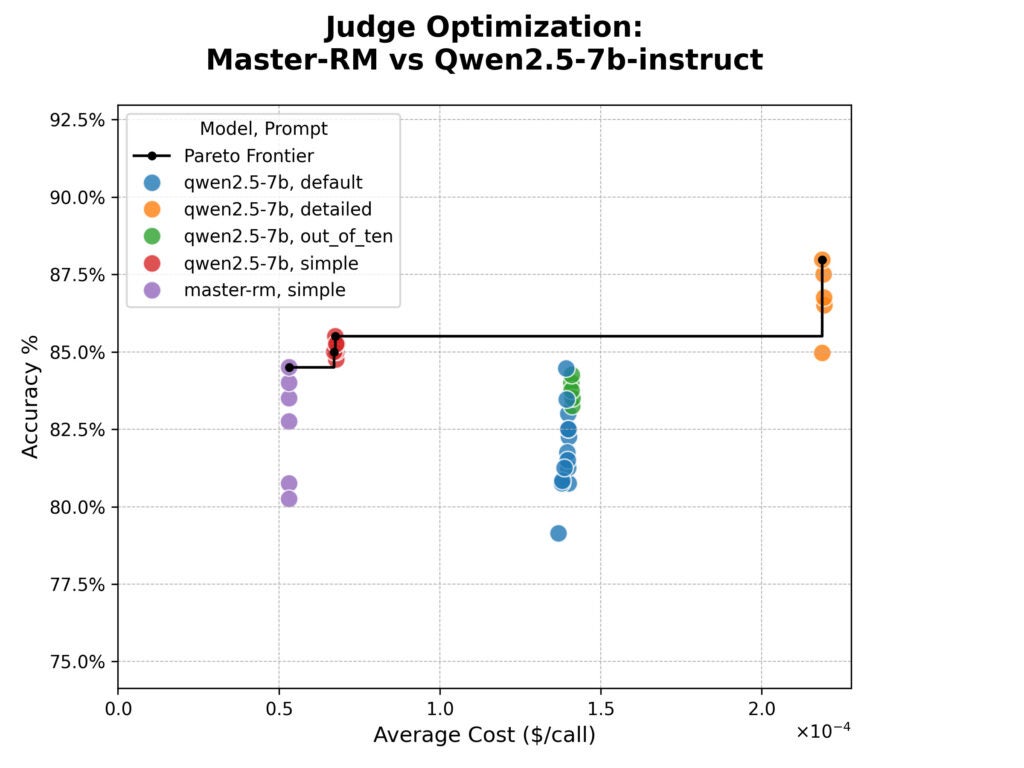
Os resultados foram surpreendentes.
O Grasp-RM não period mais preciso do que seu modelo básico e lutou para produzir qualquer coisa além do formato de resposta imediata “simples” devido ao seu treinamento focado.
Embora o treinamento especializado do modelo tenha sido eficaz no combate aos efeitos de frases específicas de raciocínio, ele não melhorou o alinhamento geral aos julgamentos humanos em nosso conjunto de dados.
Também vimos uma troca clara. O immediate “detalhado” foi o mais preciso, mas quase quatro vezes mais caro nos tokens.
Em seguida, dimensionamos, avaliando um cluster de grandes modelos de peso aberto (de Qwen, Deepseek, Google e Nvidia) e testando novas estratégias de juízes:
- Aleatório: Selecionar um juiz aleatoriamente de um pool para cada avaliação.
- Consenso: Pesquisa 3 ou 5 modelos e assumindo a maioria dos votos.
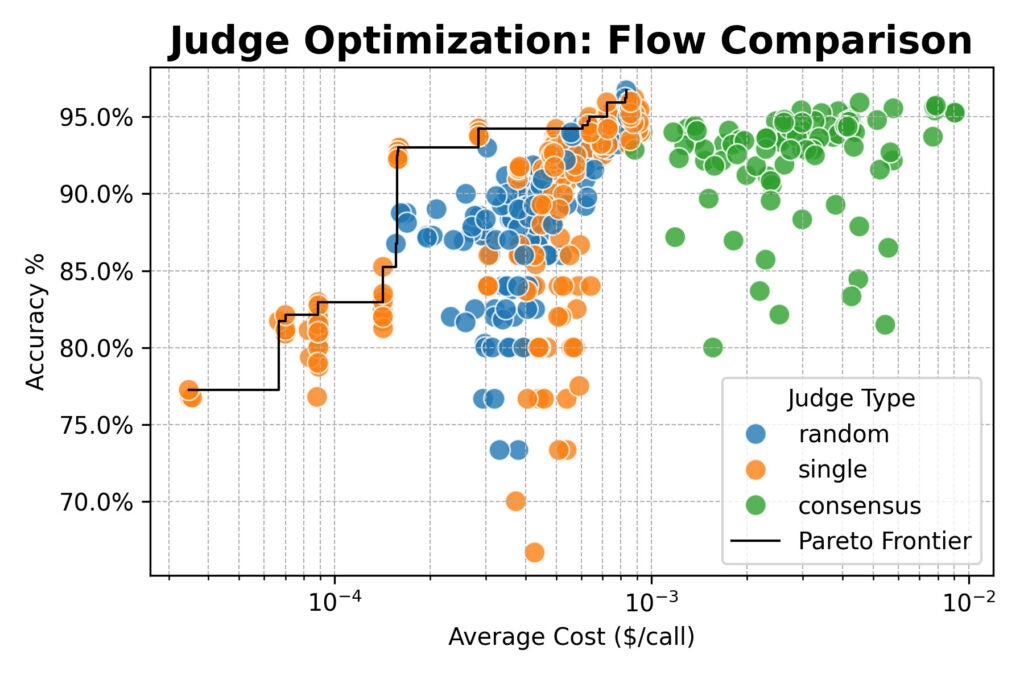
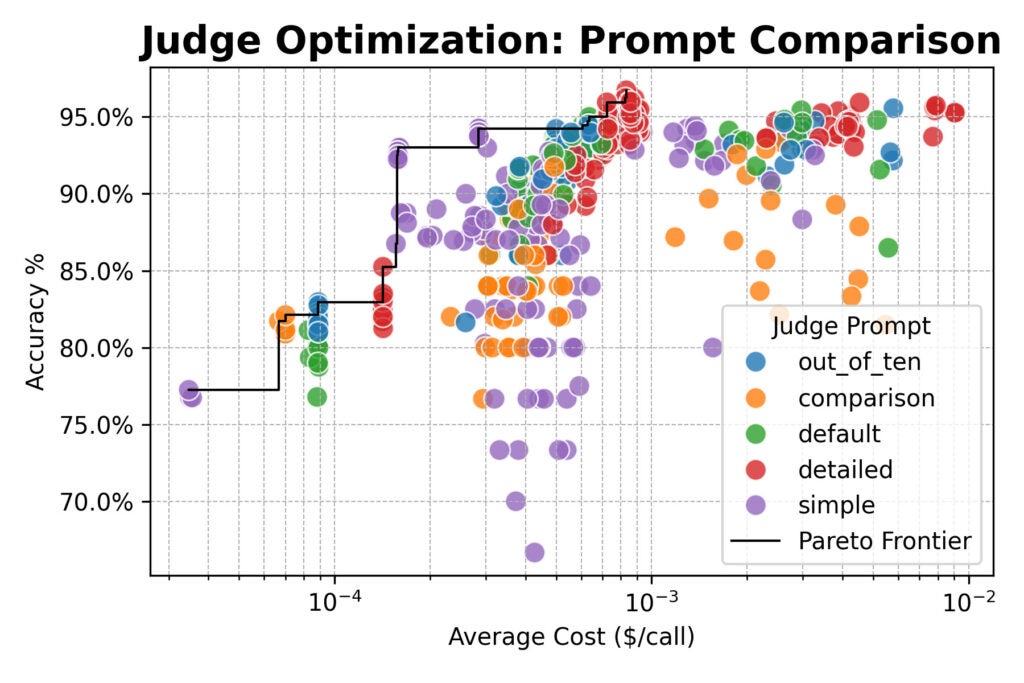
Aqui, os resultados convergiram: juízes baseados em consenso não ofereceram vantagem de precisão sobre juízes únicos ou aleatórios.
Todos os três métodos atingidos por aí 96% de concordância com rótulos humanos. Em geral, as configurações de melhor desempenho usaram o immediate detalhado.
Mas houve uma exceção importante: o aviso simples emparelhado com um poderoso modelo de peso aberto como QWEN/QWEN2.5-72B-INSTRUTA estava quase 20 × mais barato do que os avisos detalhados, embora apenas desistindo de alguns pontos percentuais de precisão.
O que torna essa solução diferente?
Durante muito tempo, nossa regra geral foi: “Basta usar o GPT-4o-mini.” É um atalho comum para as equipes que procuram um juiz confiável e pronto. E enquanto o GPT-4O-Mini teve um bom desempenho (cerca de 93% de precisão com o immediate padrão), nossos experimentos revelaram seus limites. É apenas um ponto em uma curva de trade-off muito mais ampla.
Uma abordagem sistemática oferece um menu de opções otimizadas em vez de um único padrão:
- Precisão superior, não importa o custo. Um fluxo de consenso com o immediate detalhado e modelos como QWEN3-32B, Deepseek-R1-Distill e Nemotron-Tremendous-49B alcançou 96% de alinhamento humano.
- Testes rápidos e favoráveis ao orçamento. Um único modelo com o immediate simples atingir ~ 93% de precisão em um quinto O custo da linha de base GPT-4O-Mini.
Ao otimizar a precisão, o custo e a latência, você pode fazer escolhas informadas adaptadas às necessidades de cada projeto-em vez de apostar tudo em um juiz de tamanho único.
Construindo juízes confiáveis: itens -chave
Quer você use nossa estrutura ou não, nossas descobertas podem ajudá -lo a criar sistemas de avaliação mais confiáveis:
- O aviso é a maior alavanca. Para o maior alinhamento humano, use prompts detalhados Isso soletrou seus critérios de avaliação. Não assuma que o modelo sabe o que “bom” significa para sua tarefa.
- Funcionamentos simples quando a velocidade é importante. Se custo ou latência for crítico, um immediate simples (por exemplo, “Retorne sim se a resposta gerada estiver correta em relação à resposta de referência, ou não, se não for.”) emparelhado com um modelo capaz oferece excelente valor, com apenas uma pequena compensação de precisão.
- Comitês trazem estabilidade. Para avaliações críticas em que a precisão é não negociável, a pesquisa de 3 a 5 modelos diversos e poderosos e o voto da maioria reduz o viés e o ruído. Em nosso estudo, o fluxo de consenso de alta precisão combinou QWEN/QWEN3-32B, Deepseek-R1-Distill-Llama-70B e Nemotron-49b da NVIDIA.
- Modelos maiores e mais inteligentes ajudam. Os LLMs maiores superaram consistentemente os menores. Por exemplo, a atualização do Microsoft/Phi-4-Multimodal-Instruct (5,5b) com um immediate detalhado para Gemma3-27b-it com um immediate simples forneceu um impulso de 8% na precisão-a uma diferença desprezível de custo.
Da incerteza à confiança
Nossa jornada começou com uma descoberta preocupante: em vez de seguir a rubrica, nossos juízes de LLM estavam sendo influenciados por recusas longas e de som plausível.
Ao tratar a avaliação como um rigoroso problema de engenharia, passamos da dúvida para a confiança. Obtivemos uma visão clara e orientada a dados das compensações entre precisão, custo e velocidade nos sistemas LLM-AS-A-JUDGE.
Mais dados significam melhores opções.
Esperamos nosso trabalho e nosso conjunto de dados de código aberto Incentive você a examinar mais de perto seus próprios pipelines de avaliação. A configuração “melhor” sempre dependerá de suas necessidades específicas, mas você não precisa mais adivinhar.
Pronto para construir avaliações mais confiáveis? Discover nosso trabalho em Syftr e comece a julgar seus juízes.