Tl; Dr
A maneira mais rápida de interromper um projeto AI AI é reutilizar um fluxo de trabalho que não se encaixa mais. Usando SyftrIdentificamos os fluxos de “bala de prata” para prioridades de baixa e alta precisão que tenham um bom desempenho consistentemente em vários conjuntos de dados. Esses fluxos superam a semeadura aleatória e transferem o aprendizado no início da otimização. Eles recuperam cerca de 75% do desempenho de uma corrida completa do Syftr por uma fração do custo, o que os torna um ponto de partida rápido, mas ainda deixa espaço para melhorar.
Se você já tentou reutilizar um fluxo de trabalho Agentic de um projeto em outro, sabe com que frequência ele cai. O comprimento do contexto do modelo pode não ser suficiente. O novo caso de uso pode exigir um raciocínio mais profundo. Ou requisitos de latência podem ter mudado.
Mesmo quando a configuração antiga funciona, ela pode ser superada – e muito cara – para o novo problema. Nesses casos, uma configuração mais simples e rápida pode ser tudo o que você precisa.
Decidimos para responder a uma pergunta simples: Existem fluxos agênticos que têm um bom desempenho em muitos casos de uso, para que você possa escolher um com base em suas prioridades e avançar?
Nossa pesquisa sugere que a resposta é sim, e nós os chamamos de “balas de prata”.
Identificamos balas de prata para objetivos de baixa latência e alta precisão. Na otimização precoce, eles vencem consistentemente o aprendizado de transferência e a semeadura aleatória, evitando o custo whole de uma execução completa do SYFTR.
Nas seções a seguir, explicamos como os encontramos e como eles se comparam a outras estratégias de semeadura.
Uma cartilha rápida sobre Pareto-Frontiers
Você não precisa de um diploma de matemática para acompanhar, mas entender o Pareto-Frontier tornará o restante deste publish muito mais fácil de seguir.
A Figura 1 é um gráfico de dispersão ilustrativo – não de nossos experimentos – mostrando concluído Syftr Ensaios de otimização. O sub-gráfico A e o sub-gráfico B são idênticos, mas B destaca os três primeiros pareto-frontiers: P1 (vermelho), P2 (verde) e P3 (azul).

- Cada teste: Uma configuração de fluxo específica é avaliada na precisão e na latência média (maior precisão, menor latência são melhores).
- Pareto-Frontier (P1): Nenhum outro fluxo tem maior precisão e menor latência. Estes são não dominado.
- Fluxos que não são pareto: Pelo menos um fluxo de Pareto os supera nas duas métricas. Estes são dominado.
- P2, P3: Se você remover P1, P2 se tornará a próxima melhor fronteira, então P3 e assim por diante.
Você pode escolher entre os fluxos de Pareto, dependendo de suas prioridades (por exemplo, favorecendo a baixa latência sobre a precisão máxima), mas não há razão para escolher um fluxo dominado – sempre há uma opção melhor na fronteira.
Otimizando a IA Agentic flui com SYFTR
Ao longo de nossos experimentos, usamos Syftr Para otimizar os fluxos agênticos para precisão e latência.
Esta abordagem permite que você:
- Selecione conjuntos de dados contendo pares de perguntas -respostas (QA)
- Defina um espaço de pesquisa para parâmetros de fluxo
- Defina objetivos como precisão e custo, ou neste caso, precisão e latência
Em resumo, o SYFTR automatiza a exploração das configurações de fluxo em relação aos objetivos escolhidos.
A Figura 2 mostra a arquitetura Syftr de alto nível.
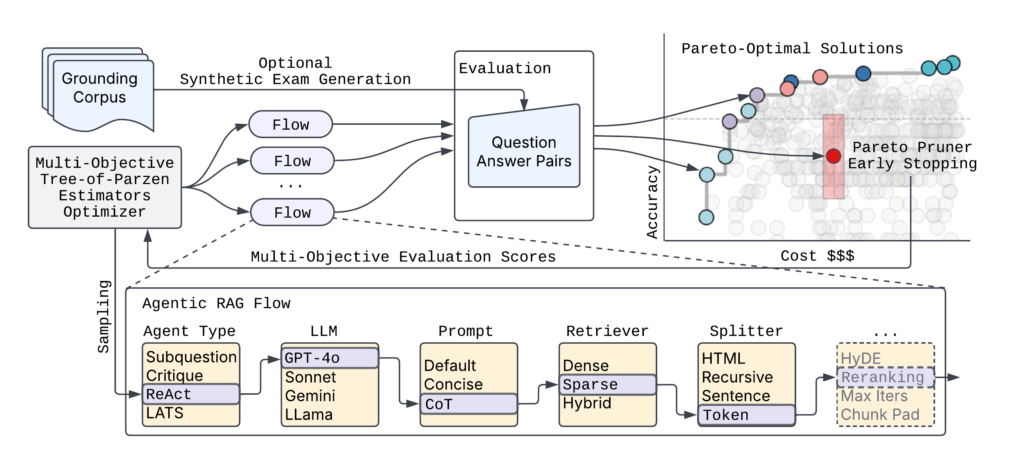
Dado o número praticamente infinito de possíveis parametrizações de fluxo agêntico, o SYFTR conta com duas técnicas principais:
- Otimização bayesiana multi-objetiva Para navegar no espaço de pesquisa com eficiência.
- Paretopruner Para interromper a avaliação dos prováveis fluxos abaixo do supreme, economizando tempo e calcular enquanto ainda aparecem as configurações mais eficazes.
Experimentos de bala de prata
Nossos experimentos seguiram um processo de quatro partes (Figura 3).
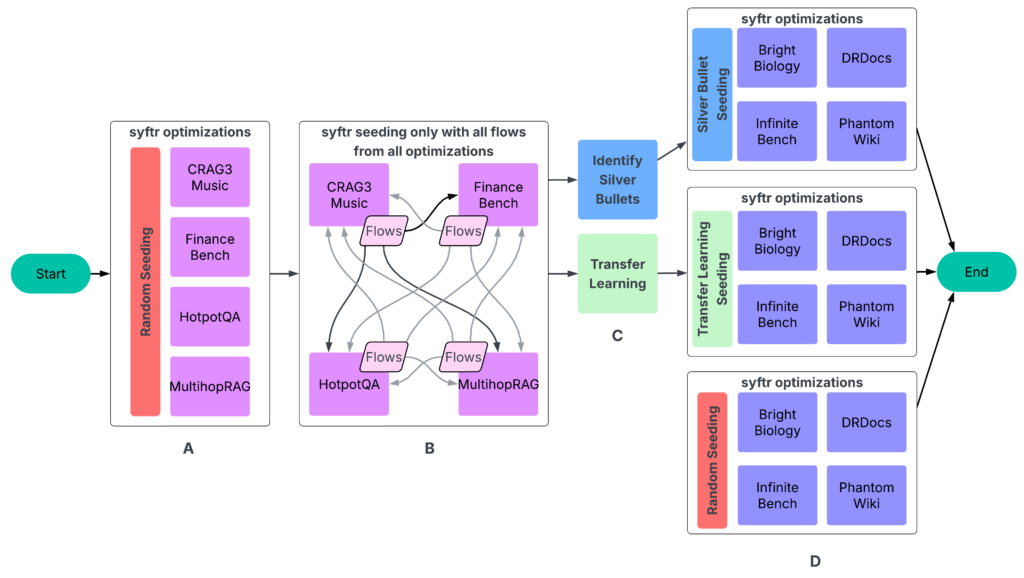
UM: Execute o SYFTR usando amostragem aleatória simples para semeadura.
B: Execute todos os fluxos acabados em todos os outros experimentos. Os dados resultantes então alimentam a próxima etapa.
C: Identificando balas de prata e conduzindo o aprendizado de transferência.
D: Executando o SYFTR em quatro conjuntos de dados detidos três vezes, usando três estratégias de semeadura diferentes.
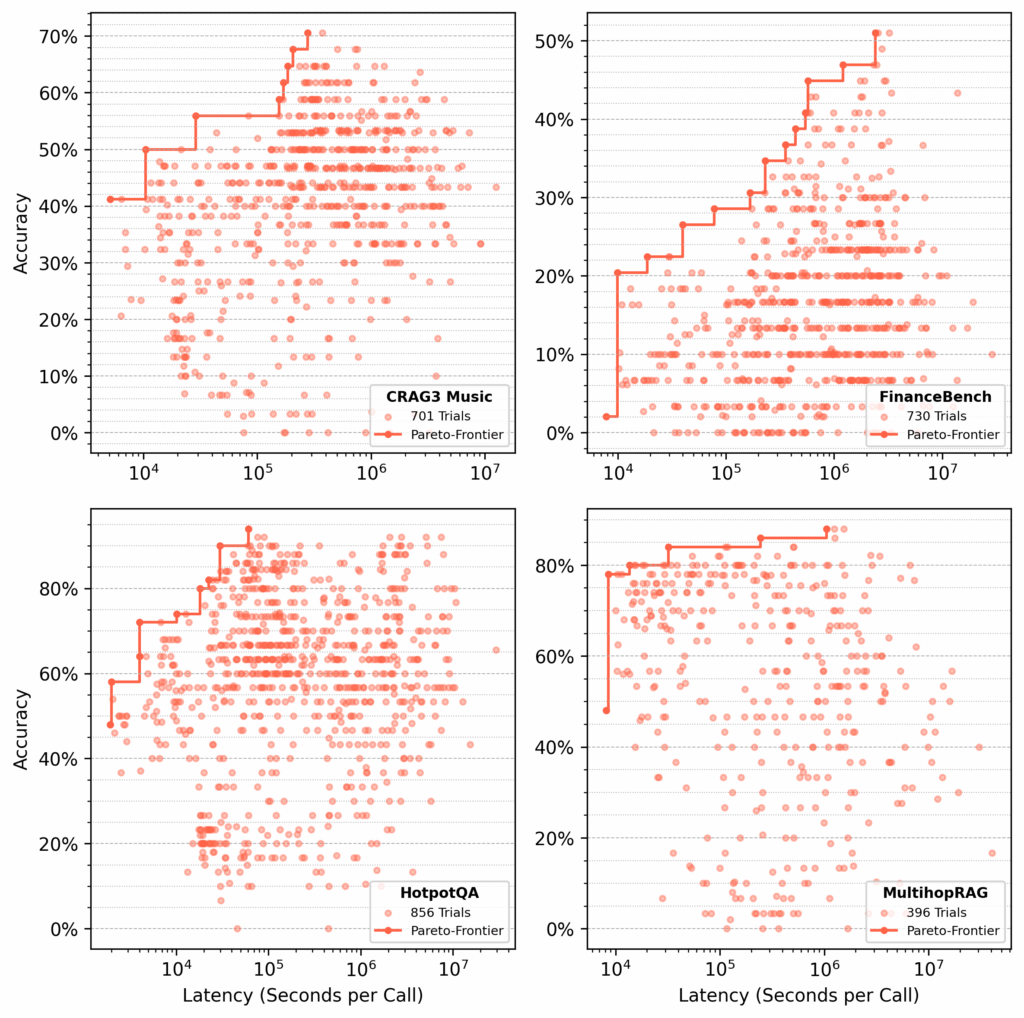
Etapa 1: otimizar os fluxos por conjunto de dados
Realizamos várias centenas de testes em cada um dos seguintes conjuntos de dados:
- Música 3 do Crag Process 3
- Financebench
- Hotpotqa
- Multihoprag
Para cada conjunto de dados, Syftr procurou fluxos de pareto-ideais, otimizando a precisão e a latência (Figura 4).
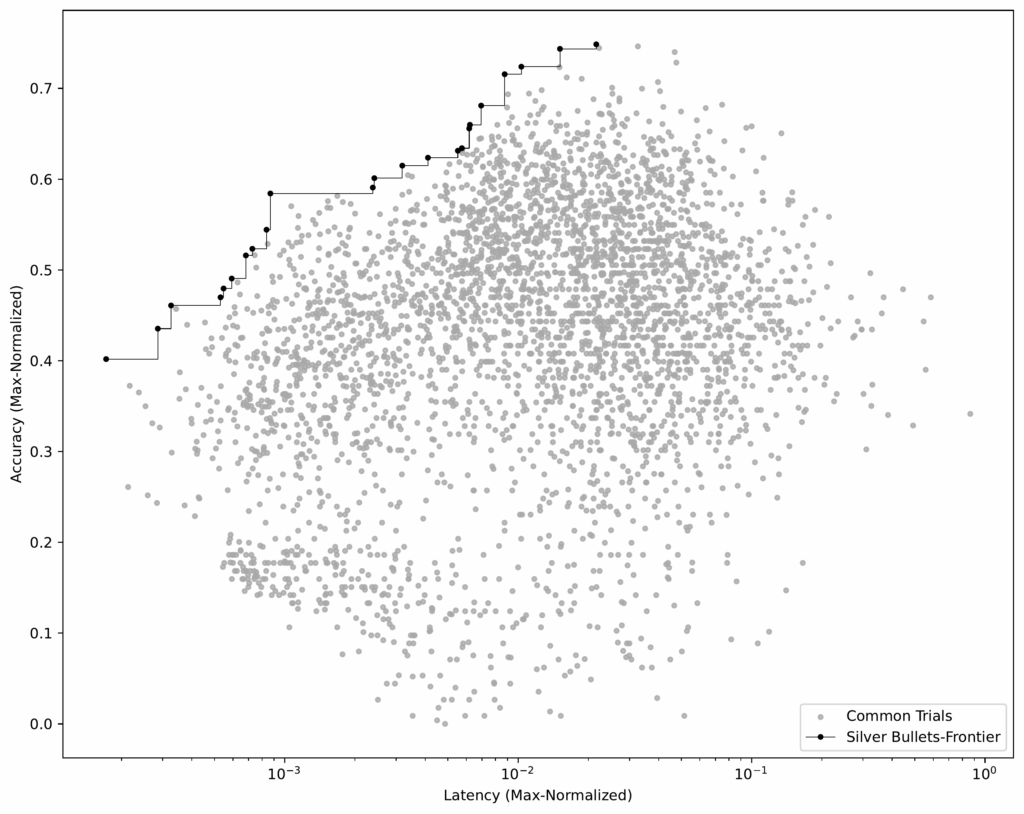
Etapa 3: Identifique balas de prata
Depois que tivemos fluxos idênticos em todos os conjuntos de dados de treinamento, poderíamos identificar as balas de prata-os fluxos que são pareto-ideais em média em todos os conjuntos de dados.
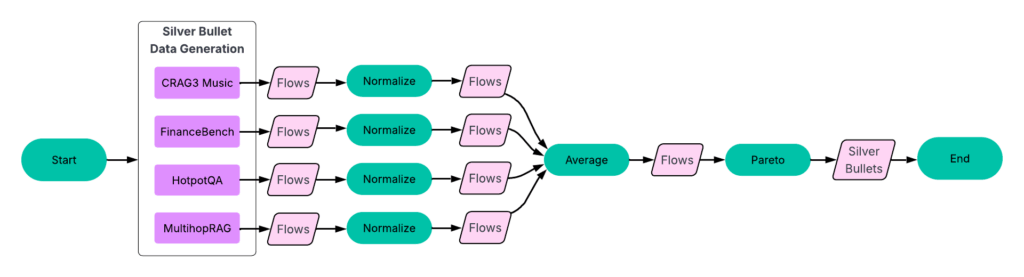
Processo:
- Normalizar resultados por conjunto de dados. Para cada conjunto de dados, normalizamos as pontuações de precisão e latência pelos valores mais altos nesse conjunto de dados.
- Grupo fluxos idênticos. Em seguida, agrupamos os fluxos de correspondência nos conjuntos de dados e calculamos sua precisão e latência média.
- Identifique o Pareto-Frontier. Usando esse conjunto de dados média (veja a Figura 6), selecionamos os fluxos que constroem o Pareto-Frontier.
Esses 23 fluxos são nossas balas de prata – aquelas que têm um bom desempenho em todos os conjuntos de dados de treinamento.
Etapa 4: semente com aprendizado de transferência
No nosso unique papel syftrexploramos o aprendizado de transferência como uma maneira de otimizações de sementes. Aqui, nós o comparamos diretamente contra a semeadura de bala de prata.
Nesse contexto, transferência de aprendizado significa simplesmente selecionar fluxos específicos de alto desempenho dos estudos históricos (de treinamento) e avaliá-los em conjuntos de dados mantidos. Os dados que usamos aqui são os mesmos das balas de prata (Figura 3).
Processo:
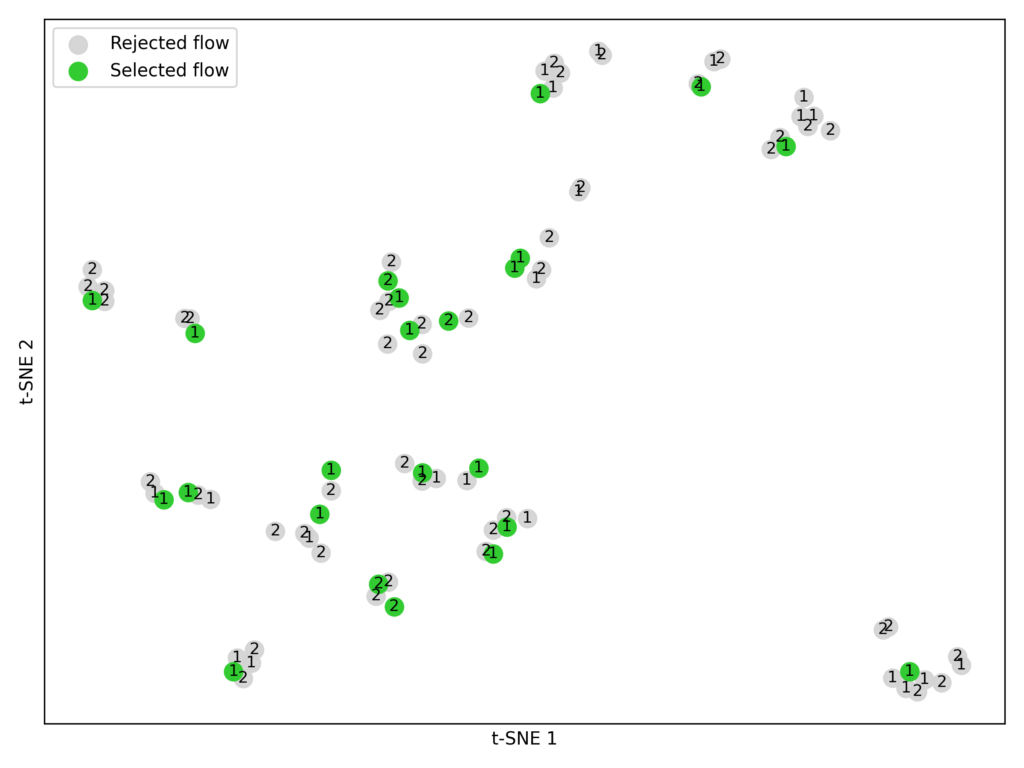
- Selecione candidatos. De cada conjunto de dados de treinamento, pegamos os fluxos de melhor desempenho dos dois primeiros de Pareto-Frontiers (P1 e P2).
- Incorporar e cluster. Usando o modelo de incorporação BAAI/BGE-Giant-en-V1.5, convertemos os parâmetros de cada fluxo em vetores numéricos. Em seguida, aplicamos o agrupamento Ok-Means (ok = 23) para agrupar fluxos semelhantes (Figura 7).
- Combinar restrições de experimentos. Limitamos cada estratégia de semeadura (balas de prata, aprendizado de transferência, amostragem aleatória) a 23 fluxos para uma comparação justa, pois é assim que as balas de prata identificamos.
Observação: O aprendizado de transferência para semeadura ainda não está totalmente otimizado. Poderíamos usar mais Pareto-Frontiers, selecionar mais fluxos ou experimentar diferentes modelos de incorporação.
Etapa 5: testando tudo
Na fase de avaliação remaining (Etapa D na Figura 3), realizamos ~ 1.000 ensaios de otimização em quatro conjuntos de dados de teste – BIOLOGIA BRILHOR, DRDOCS, Infinitebench e Phantomwiki – repetindo o processo três vezes para cada uma das seguintes estratégias de semeadura:
- Semeadura de bala de prata
- Transferir a semeadura de aprendizado
- Amostragem aleatória
Para cada julgamento, o GPT-4O-Mini serviu como juiz, verificando a resposta de um agente contra a resposta da verdadeira-verdade.
Resultados
Partimos para responder:
Qual abordagem de semeadura – amostragem aleatória, aprendizado de transferência ou balas de prata – oferece o melhor desempenho para um novo conjunto de dados no menor número de ensaios?
Para cada um dos quatro conjuntos de dados de teste (biologia brilhante, drdocs, Infinitebench e Phantomwiki), plotamos:
- Precisão
- Latência
- Custo
- Pareto-Space: uma medida de quão próximos os resultados estão do resultado supreme
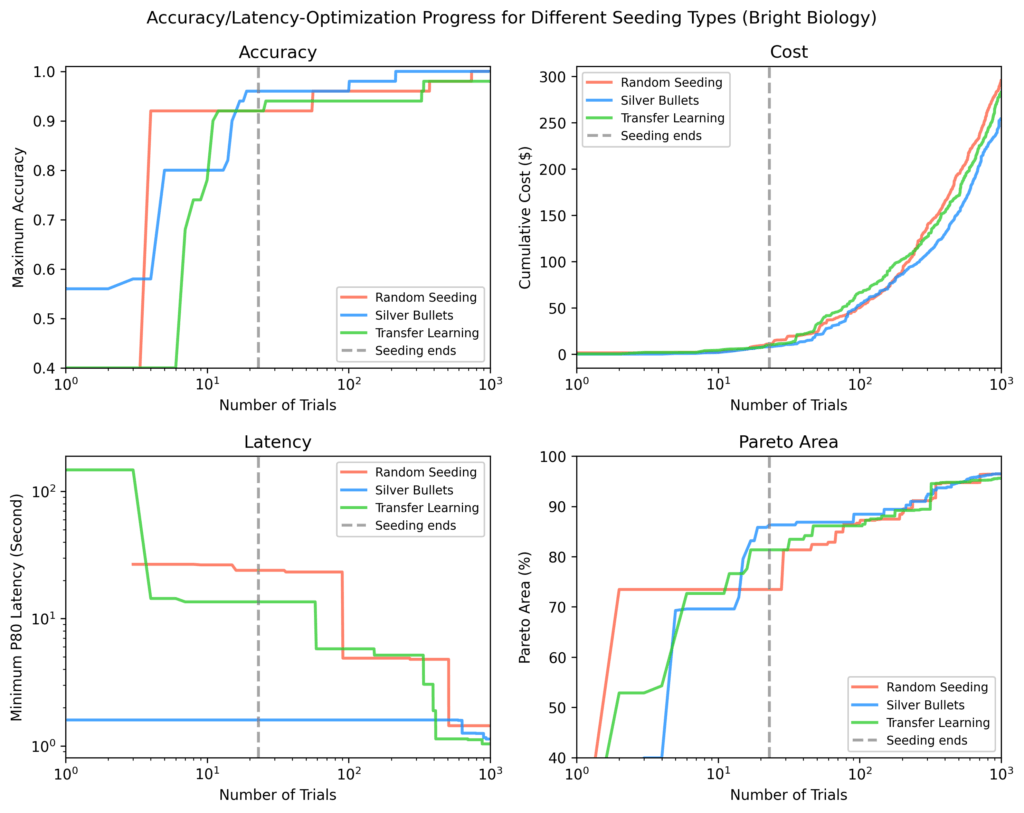
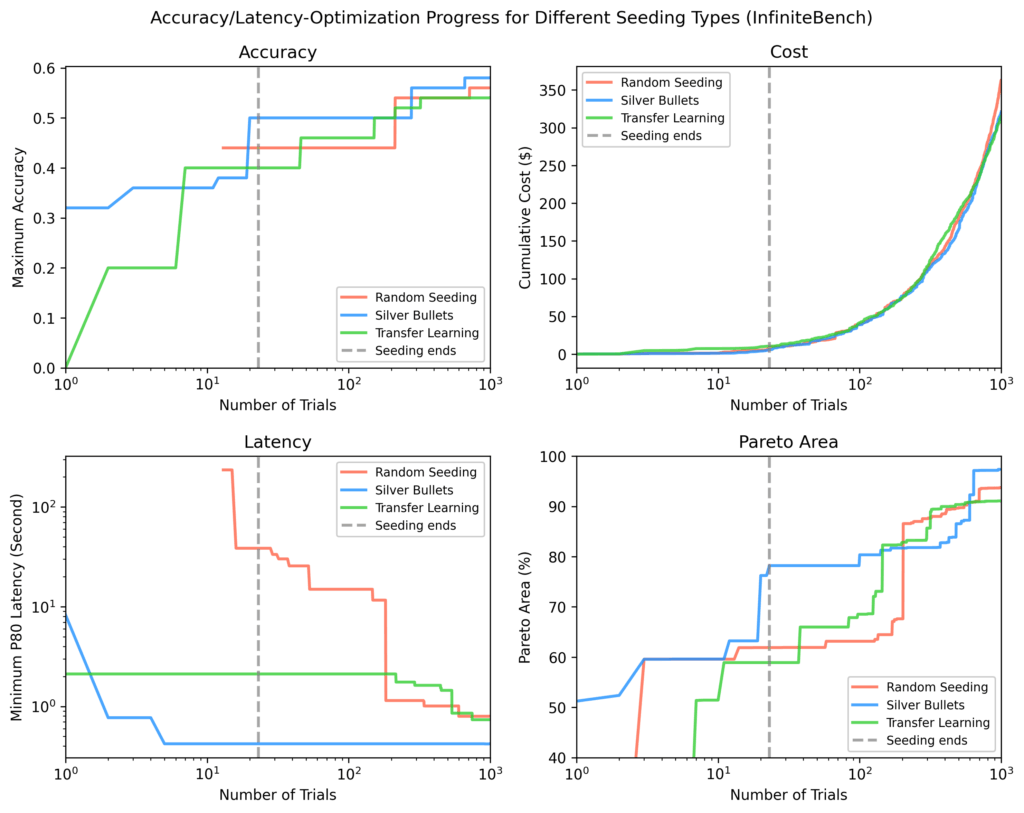
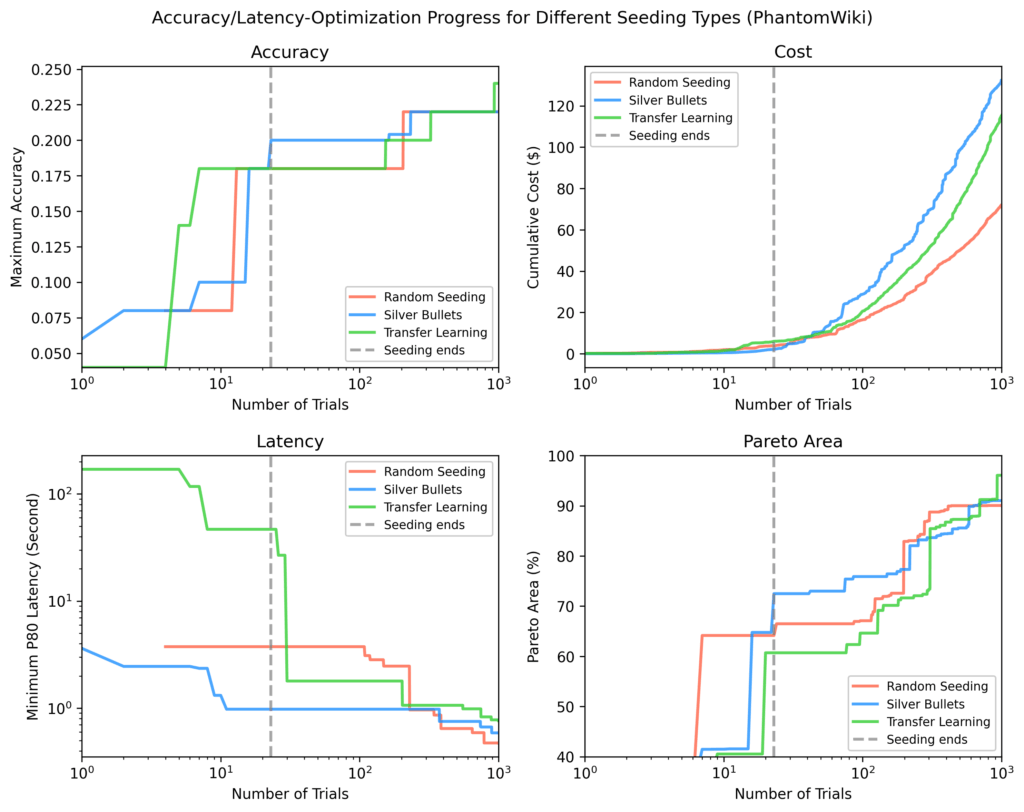
Em cada parcela, o linha pontilhada vertical marca o ponto em que todos os ensaios de semeadura foram concluídos. Após a semeadura, as balas de prata mostraram em média:
- 9% maior precisão máxima
- 84% Latência mínima menor
- 28% maior área de pareto
comparado às outras estratégias.
Biologia brilhante
As balas de prata tiveram a maior precisão, a menor latência e a maior área de pareto após a semeadura. Alguns ensaios de semeadura aleatória não terminaram. As áreas para todos os métodos aumentaram com o tempo, mas estreitaram à medida que a otimização progredia.
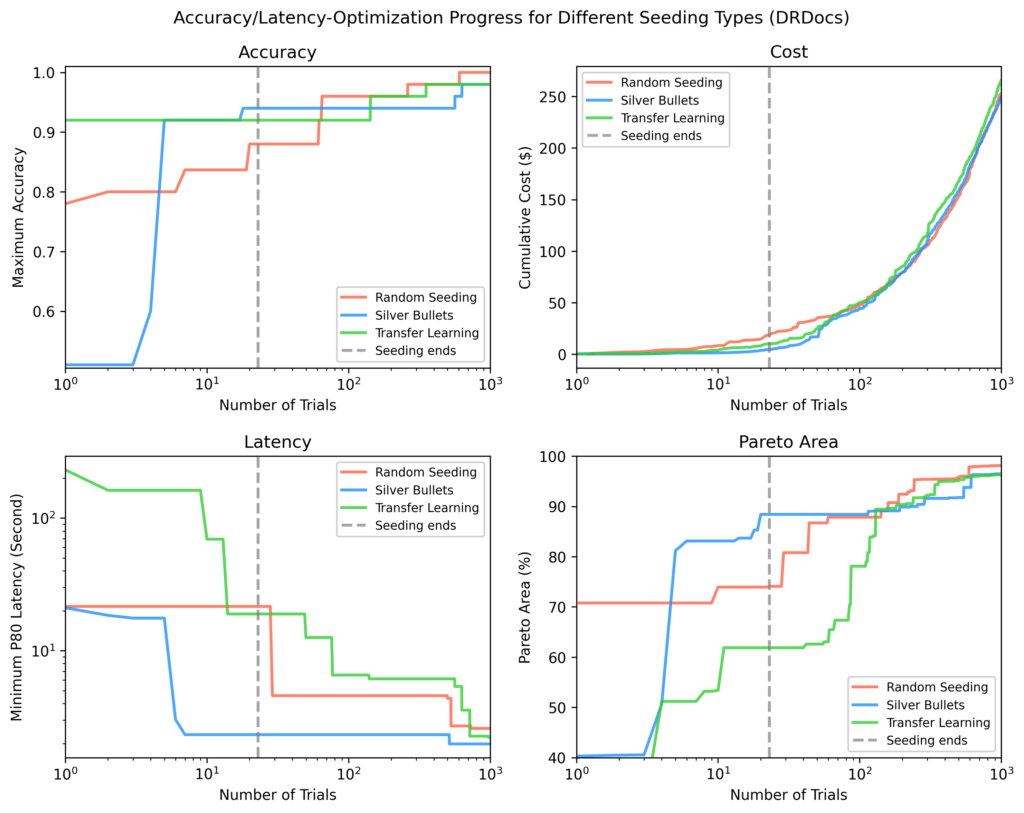
Drdocs
Semelhante à biologia brilhante, as balas de prata atingiram uma área de pareto de 88% após a semeadura vs. 71% (aprendizado de transferência) e 62% (aleatória).
Infinitebench
Outros métodos precisavam de ~ 100 ensaios adicionais para combinar com a área de pareto da bala de prata e ainda não correspondem aos fluxos mais rápidos encontrados através de balas de prata até o remaining de ~ 1.000 ensaios.
Phantomwiki
As balas de prata novamente tiveram melhor desempenho após a semeadura. Esse conjunto de dados mostrou a maior divergência de custos. Após ~ 70 ensaios, o Silver Bullet Run se concentrou brevemente em fluxos mais caros.
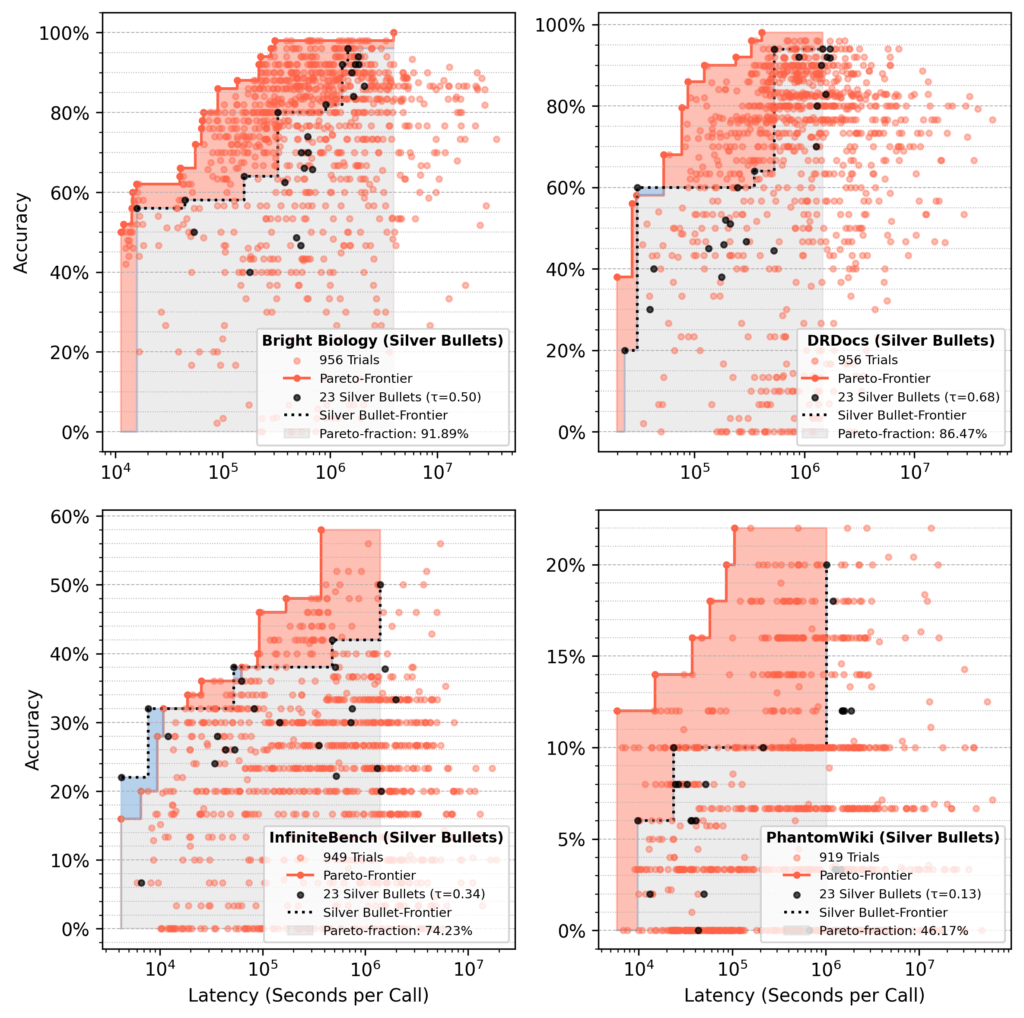
Análise de Pareto-Fração
Nas corridas semeadas com balas de prata, os 23 fluxos de bala de prata representaram ~ 75% da área remaining da área após 1.000 ensaios, em média.
- Área vermelha: ganhos com a otimização sobre o desempenho inicial da bala de prata.
- Área azul: Os fluxos de bala de prata ainda dominam no remaining.
Nosso take -away
A semeadura com balas de prata oferece resultados consistentemente fortes e até supera a transferência do aprendizado, apesar desse método extrair de um conjunto diversificado de fluxos históricos de Pareto-Frontier.
Para nossos dois objetivos (precisão e latência), as balas de prata sempre começam com maior precisão e menor latência do que os fluxos de outras estratégias.
A longo prazo, o amostrador TPE reduz a vantagem inicial. Dentro de algumas centenas de ensaios, os resultados de todas as estratégias geralmente convergem, o que é esperado, pois cada um deve eventualmente encontrar fluxos ideais.
Então, existem fluxos Agentic que funcionam bem em muitos casos de uso? Sim – até certo ponto:
- Em média, um pequeno conjunto de balas de prata recupera cerca de 75% da área de Pareto a partir de uma otimização completa.
- O desempenho varia de acordo com o conjunto de dados, como recuperação de 92% para biologia brilhante em comparação com 46% para o Phantomwiki.
Resumindo: As balas de prata são uma maneira barata e eficiente de aproximar uma corrida completa do Syftr, mas não são um substituto. Seu impacto pode crescer com mais conjuntos de dados de treinamento ou otimizações de treinamento mais longas.
Parametrizações da bala de prata
Usamos o seguinte:
Llms
- Microsoft/Phi-4-Multimodal-Instruct
- Deepseek-AI/Deepseek-R1-Distill-Llama-70B
- QWEN/QWEN2.5
- QWEN/QWEN3-32B
- Google/Gemma-3-27b-it
- Nvidia/LLAMA-3_3-NEMOTRON-SUPER-49B
Modelos de incorporação
- BAAI/BGE-SMALL-EN-V1.5
- Thenlper/gte-large
- Misto-AI-AI/MXBAI-EMBED-LARGE-V1
- Sentença-Transformers/Minilm-L12-V2
- Sentença-transformadores/parafrase-multilingual-mPNet-BASE-V2
- BAAI/BGE-BASE-EN-V1.5
- BAAI/BGE-LARGE-EN-V1.5
- Tencentbac/Conan-Embedding-V1
- Linq-AI-Analysis/Linq-Embetbed-Mistral
- Snowflake/Snowflake-Arctic-Embed-L-V2.0
- BAAI/BGE-Multilingual-Gemma2
Tipos de fluxo
- Rag de baunilha
- Reaja o agente de pano
- Critique Rag Agent
- Pano de subquestão
Aqui está a lista completa de todos 23 balas de prataclassificado de baixa precisão / baixa latência a alta precisão / alta latência: Silver_bullets.json.
Experimente você mesmo
Deseja experimentar essas parametrizações? Use o running_flows.ipynb Pocket book em nosso repositório SYFTR – apenas verifique se você tem acesso aos modelos listados acima.
Para um mergulho mais profundo na arquitetura e parâmetros de Syftr, confira nosso papel técnico ou explorar o CodeBase.
Também estaremos apresentando este trabalho no Conferência Internacional sobre Aprendizado de Máquinas Automatizado (Automl) em setembro de 2025 na cidade de Nova York.