À medida que o quantity de dados aumenta, o mesmo acontece com os riscos para sua plataforma de dados: de pipelines obsoletos a erros ocultos e custos descontrolados. Sem a observabilidade integrada à sua solução de engenharia de dados, você está voando cego e arriscando impactando não apenas a saúde e o frescor de seus pipelines de dados, mas também perdendo problemas sérios em seus dados, análises e cargas de trabalho a jusante. Com Fluxo de lagoSolução de engenharia de dados unificada e inteligente da Databricks, você pode facilmente enfrentar esse desafio com soluções de observabilidade integradas em uma interface intuitiva diretamente na sua plataforma ETL, além da sua inteligência de dados.
Neste weblog, apresentaremos os recursos de observabilidade do Lakeflow e mostraremos como criar pipelines de dados confiáveis, frescos e saudáveis.
A observabilidade é essencial para a engenharia de dados
A observabilidade para a engenharia de dados é a capacidade de descobrir, monitorar e solucionar sistemas para garantir que o ETL opere de maneira correta e eficaz. É a chave para manter pipelines de dados saudáveis e confiáveis, surgir insights e fornecer análises de confiança a jusante.
À medida que as organizações gerenciam um número cada vez mais crescente de pipelines críticos de negócios, o monitoramento e a garantia da confiabilidade de uma plataforma de dados se tornou important para um negócio. Para enfrentar esse desafio, mais engenheiros de dados estão reconhecendo e buscando os benefícios da observabilidade. De acordo com Gartner65% dos líderes de dados e análises esperam que a observabilidade dos dados se torne uma parte central de sua estratégia de dados dentro de dois anos. Os engenheiros de dados que desejam se manter atualizados e encontrar maneiras de melhorar a produtividade, enquanto dirigem dados estáveis em escala, devem implementar práticas de observabilidade em sua plataforma de engenharia de dados.
Estabelecer a observabilidade correta para sua organização envolve trazer os seguintes recursos importantes:
- Visibilidade de ponta a ponta em escala: Elimine pontos cegos e descubra insights do sistema, visualizando e analisando facilmente seus empregos e pipelines de dados em um único native
- Monitoramento proativo e detecção de falha precoce: Identifique possíveis problemas assim que surgirem, antes de impactar qualquer coisa a jusante
- Solução de problemas e otimização: Corrija os problemas para garantir a qualidade de seus resultados e otimizar o desempenho do seu sistema para melhorar os custos operacionais
Proceed lendo para ver como o LakeFlow suporta tudo isso em uma única experiência.
Visibilidade de ponta a ponta em escala em empregos e pipelines
A observabilidade eficaz começa com a visibilidade completa. Lakeflow vem com uma variedade de visualizações prontas para uso e visualizações unificadas Para ajudá -lo a permanecer no topo de seus pipelines de dados e verifique se todo o seu processo ETL está funcionando sem problemas.
Menos pontos cegos com uma vista centralizada e granular de seus empregos e pipelines
O Empregos e pipelines A página centraliza o acesso a todos os seus trabalhos, dutos e sua história de corrida no espaço de trabalho. Essa visão geral unificada de suas execuções simplifica a descoberta e o gerenciamento de seus pipelines de dados e facilita a visualização de execuções e rastreia as tendências para um monitoramento mais proativo.
Procurando mais informações sobre seus empregos? Basta clicar em qualquer trabalho para ir a uma página dedicada que apresenta um Visualização da matriz e destaca detalhes -chave como standing, duração, tendências, avisos e muito mais. Você pode:
- Faça uma corrida facilmente em um trabalho específico para insights adicionaiscomo a visualização do gráfico para visualizar dependências ou ponto de falha
- amplie o zoom para ver o nível da tarefa (como o pipeline, a saída de notebooks, and many others.) para mais detalhes, como Métricas de streaming (Disponível em visualização pública).
O LakeFlow também oferece uma página de execução de oleoduto dedicada, onde você pode monitorar facilmente o standing, as métricas e o progresso da execução do seu pipeline nas mesas.

Mais informações com a visualização de seus dados em escala
Além dessas visões unificadas, o LakeFlow fornece observabilidade histórica para suas cargas de trabalho para obter informações sobre seu uso e tendências. Usando Tabelas do sistemaTabelas gerenciadas por Databricks que rastreiam e consolidam todos os empregos e pipeline criados em todos os espaços de trabalho em uma região, você pode criar painéis detalhados e relatórios para visualizar seu empregos e oleodutos dados em escala. Com o interativo recentemente atualizado Modelo de painel para Tabelas do sistema Lakeflow, É muito mais fácil e mais rápido:
- Rastrear as tendências de execução: insights facilmente superficiais sobre o comportamento do trabalho ao longo do tempo para melhores decisões orientadas a dados
- Identifique gargalos: detecte possíveis problemas de desempenho (abordados com mais detalhes na seção a seguir)
- Referência cruzada com cobrança: melhorar o monitoramento de custos e evitar surpresas de cobrança
As tabelas de sistemas para empregos e pipelines estão atualmente em visualização pública.

A visibilidade se estende além da tarefa ou nível de trabalho. Integração de Lakeflow com Catálogo de unidadesSolução de governança unificada dos Databricks, ajuda a completar a imagem com um visible de todo o seu linhagem de dados. Isso facilita a rastreamento de fluxo de dados e as dependências e obtenha o contexto e o impacto completo de seus oleodutos e trabalhos em um único native.

Monitoramento proativo, detecção precoce de falhas no trabalho, solução de problemas e otimização
Como engenheiros de dados, você não é apenas responsável pelo monitoramento de seus sistemas. Você também precisa ser proativo sobre quaisquer problemas ou lacunas de desempenho que possam surgir no seu desenvolvimento de ETL e resolvê -los antes que eles afetem seus resultados e custos.
Alerta proativa para pegar as coisas mais cedo
Com o nativo de Lakeflow notificaçõesvocê pode escolher se e como ser alertado sobre erros críticos de trabalho, durações ou pedidos de backlogs by way of Slack, e mail ou até PagerDuty. Ganchos de eventos em Oleodutos declarativos do Lakeflow (Atualmente em visualização pública) fornece ainda mais flexibilidade, definindo funções personalizadas de retorno de chamada Python para que você decida o que monitorar ou quando ser alertado em eventos específicos.
Análise de causa raiz mais rápida para remediação rápida
Depois de receber o alerta, o próximo passo é entender por que Algo deu errado.
O LakeFlow permite que você salte da notificação diretamente para a visão detalhada de uma falha específica de trabalho ou tarefa para análise de causa raiz no contexto. O nível de detalhe e flexibilidade com o qual você pode ver seus dados de fluxo de trabalho permite identificar facilmente o que exatamente é responsável pelo erro.
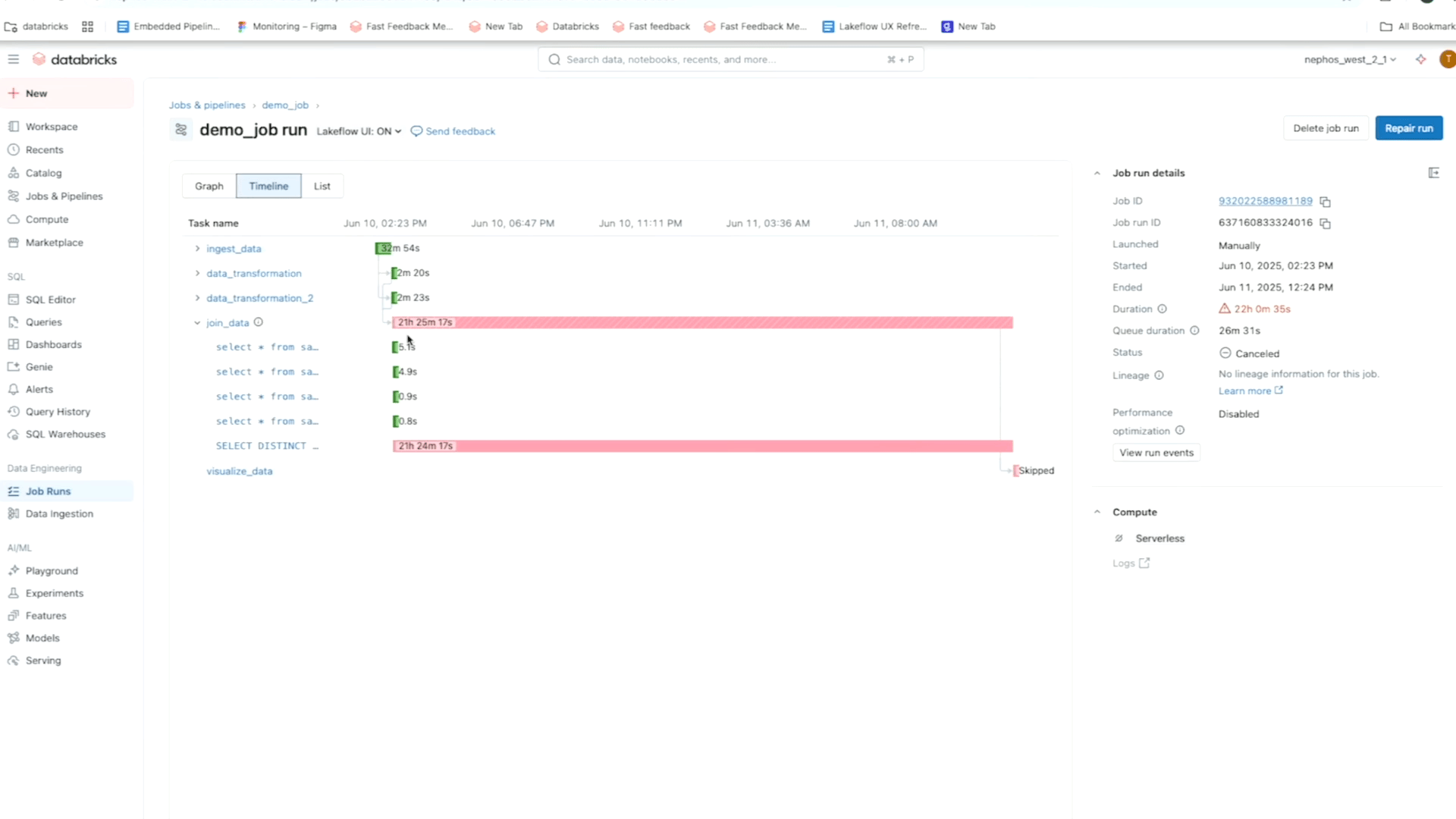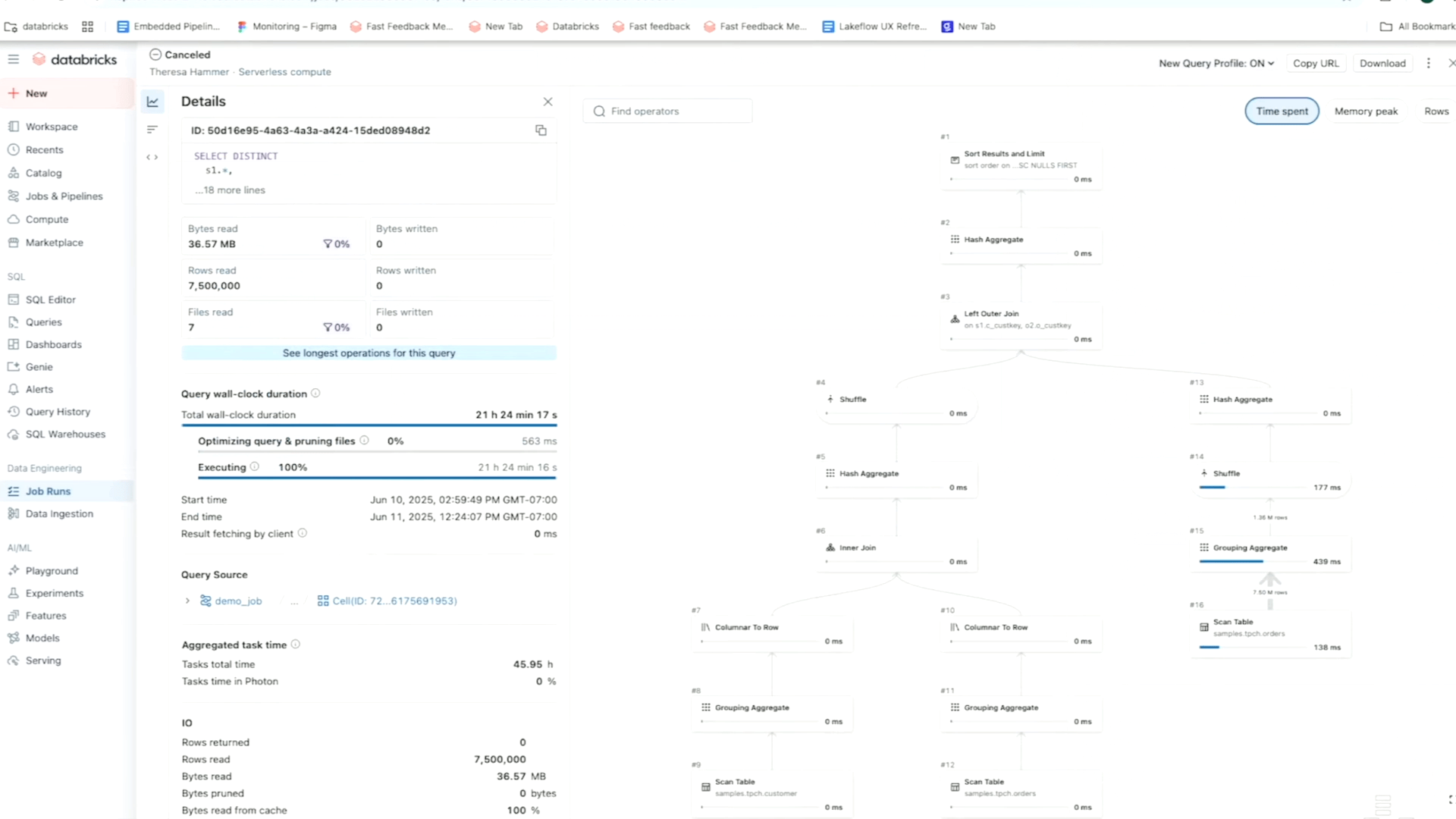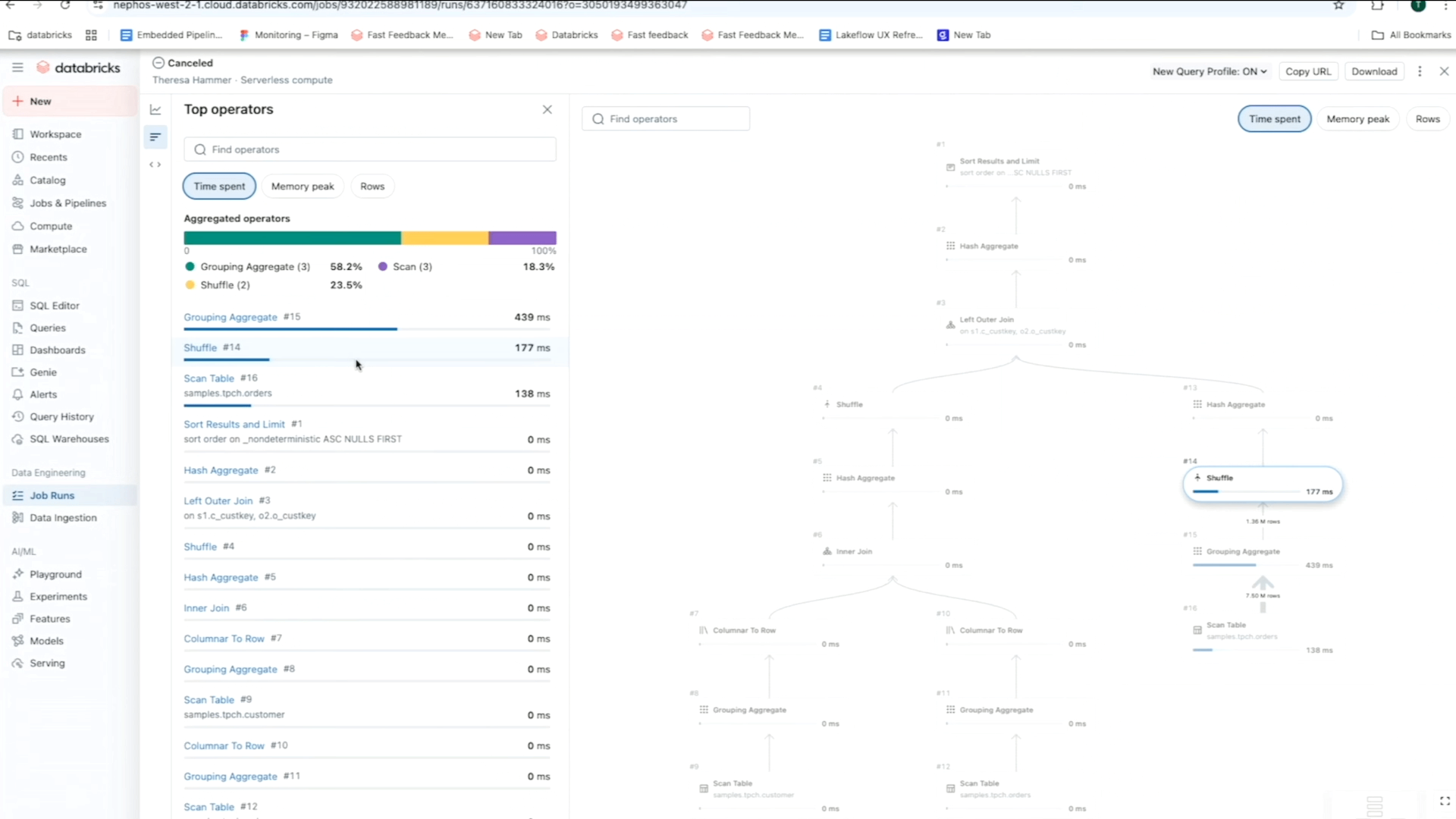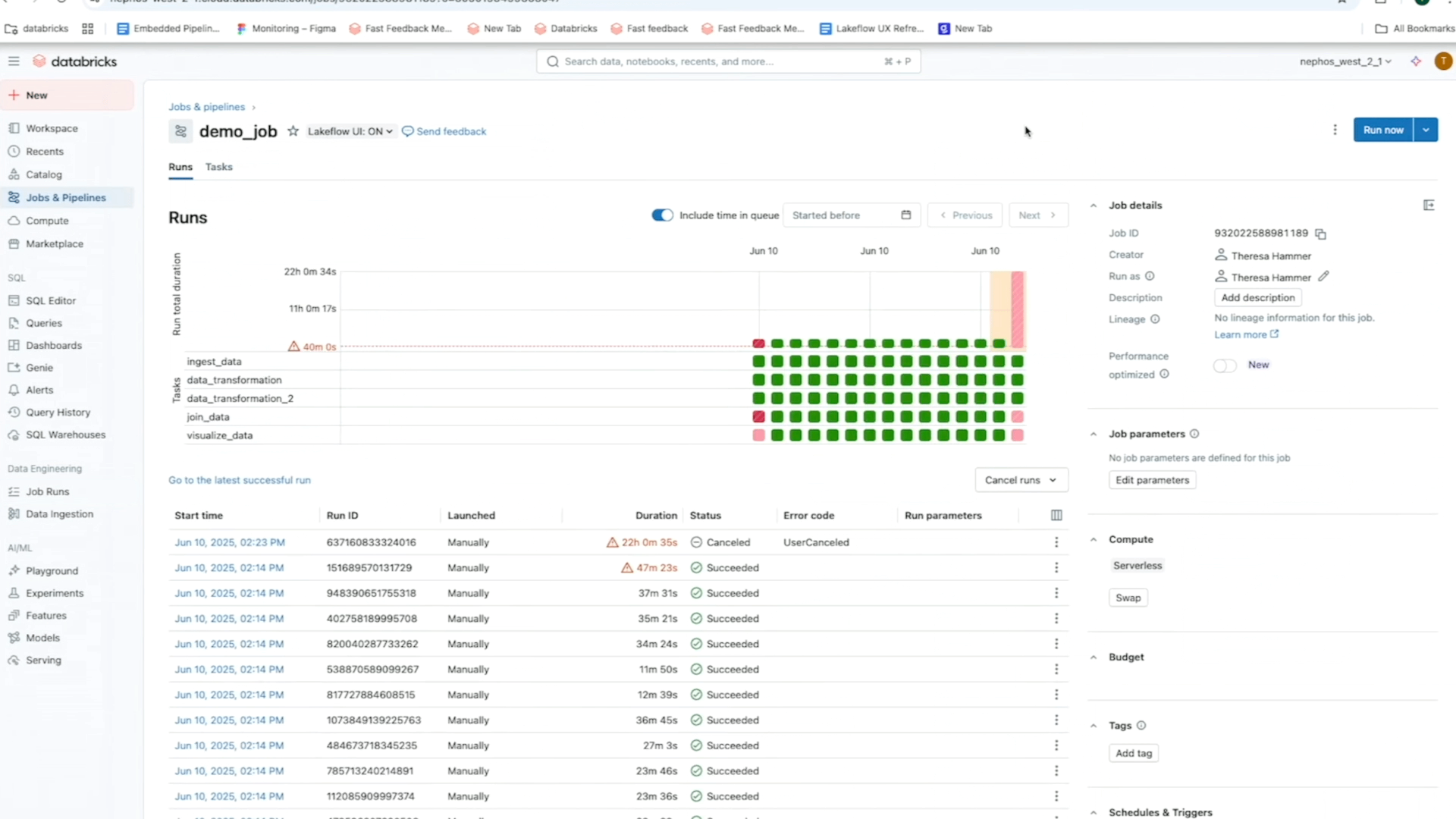
Por exemplo, usando a visualização da matriz de um trabalho, você pode rastrear padrões de falha e desempenho nas tarefas para um fluxo de trabalho específico. Enquanto isso, o linha do tempo (Gantt) Ver quebre a duração de cada tarefa e consulta (para trabalhos sem servidor) para que você possa identificar problemas lentos de desempenho em um emprego e se aprofundar para as causas da raiz usando Perfis de consulta. Como lembrete, Databricks ‘ Perfis de consulta mostre uma rápida visão geral do seu SQL, Python e Oleoduto declarativo execuções, facilitando a identificação de gargalos e otimizam as cargas de trabalho em sua plataforma ETL.
Você também pode confiar em Tabelas do sistema Para facilitar a análise da causa raiz, construindo painéis que destacam irregularidades em seus empregos e suas dependências. Esses painéis ajudam você a identificar rapidamente não apenas falhas, mas também lacunas de desempenho ou oportunidades de melhoria de latência, como latência P50/P90/P99 e métricas de cluster. Para complementar sua análise, você pode aproveitar as tabelas de sistemas de histórico de dados e consultas, para que você possa rastrear facilmente erros upstream e impactos a jusante através da linhagem de dados.
Depuração e otimização para pipelines confiáveis
Além da análise de causa raiz, o LakeFlow fornece ferramentas para Solução de problemas rápidosseja um problema de recurso de cluster ou um erro de configuração. Depois de resolver o problema, você pode executar as tarefas com falha e suas dependências sem executar o trabalho inteiro, economizando recursos computacionais. Enfrentando casos de uso mais complexos de solução de problemas? Assistente de Databricksnosso assistente de IA (atualmente em visualização pública), fornece informações claras e ajuda a diagnosticar erros em seus empregos e pipelines.

No momento, estamos desenvolvendo recursos adicionais de observabilidade para ajudá -lo a monitorar melhor seus pipelines de dados. Em breve, você também poderá visualizar as métricas de saúde de seus fluxos de trabalho e pipelines e entender melhor o comportamento de suas cargas de trabalho com indicadores e sinais emitidos de empregos e pipelines.
Resumo das capacidades de observabilidade do Lakeflow
Comece a construir engenharia de dados confiável com o Lakeflow
O LakeFlow oferece o suporte necessário para garantir que seus empregos e dutos funcionem sem problemas, sejam saudáveis e opere de maneira confiável em escala. Experimente nossas soluções de observabilidade internas e veja como você pode criar uma plataforma de engenharia de dados pronta para seus esforços de inteligência de dados e necessidades de negócios.