
(Mohd.-Afuza/Shutterstock)
Há algo escondido em seus sistemas de arquivos e armazenamentos de objetos. Chamam-se dados não estruturados e estão a transformar-se numa enorme bolha que ameaça consumir custos de armazenamento, violar regulamentos de segurança e privacidade e inviabilizar as suas iniciativas de IA. Existe alguma maneira de conquistá-lo?
Controlar esses dados não estruturados está se tornando uma prioridade do alto escalão, tanto por motivos ofensivos (GenAI) quanto defensivos (regulatórios). Mas a própria natureza dos dados não estruturados torna-os difíceis de gerir. Afinal, como você classifica palavras e imagens? Como você arquiva petabytes de arquivos de log? E talvez o mais importante: como impor o controle de acesso em milhares de silos de dados distintos?
O desafio e a oportunidade do gerenciamento de dados não estruturados estão levando os fornecedores de TI a expandir seu alcance no domínio não estruturado. Um fornecedor que está navegando em águas não estruturadas há algum tempo é Dinâmica de Dados. Piyush Mehta, que se autodenomina “cara de finanças contábeis”, fundou a empresa de software program de Nova Jersey em 2012 com o objetivo de enfrentar alguns dos desafios de gerenciamento de dados que ele viu nas empresas enfrentarem.
A primeira coisa que Mehta notou foi que todos pareciam ter a sua própria definição do que significava “gestão de dados”.

Dados não estruturados incluem texto, imagens, vídeo, áudio, IoT e outros tipos de arquivos
“Se você olhar da perspectiva do CISO, a pergunta é ‘Como faço para gerenciar meu risco associado aos dados?’”, diz Mehta. “Se você falar com o CDO, a pergunta é ‘Tenho o entendimento adequado da classificação e da jornada de como esses dados são canalizados para o native certo?’ E então, se você olhar da perspectiva do CIO, trata-se de gerenciamento do ciclo de vida: como posso garantir que forneço os recursos de armazenamento corretos? Como posso fornecer e ter certeza de que tenho higiene adequada quando esses dados são armazenados e onde e o que encontramos?
Essa siloização do pensamento de gerenciamento de dados leva a uma proliferação de ferramentas de gerenciamento de dados. Não é incomum ver uma única empresa ter de 15 a 18 soluções pontuais diferentes para abordar vários aspectos do desafio do gerenciamento de dados, desde risco, classificação ou gerenciamento do ciclo de vida, diz ele.
“E isso fica extremamente complicado”, diz ele BigDATAwire em uma entrevista recente. “Você está verificando os mesmos dados várias vezes. Então isso nos levou a dizer: ei, deve haver uma maneira melhor.”
Falhas nas ondas de Huge Knowledge
Antigamente (ou seja, na década de 2010), todos pensávamos que um ou dois petabytes de dados armazenados em um sistema de arquivos ou em um armazenamento de objetos period um grande negócio. Mas esses dados residiam principalmente no armazenamento secundário. Os dados realmente importantes, que alimentam os aplicativos de negócios e orientam a tomada de decisões, estavam armazenados em armazenamento em bloco, em SANs que apoiavam o banco de dados.

Piyush Mehta é o CEO da Knowledge Dynamics
Mas as coisas mudaram e hoje não há realmente nenhuma diferença entre o armazenamento em bloco e o armazenamento de arquivos, diz Mehta.
“Você tem aplicativos de alto desempenho em execução com armazenamento de objetos no back-end, porque ele funciona melhor como uma camada única e plana para analisar dados”, diz ele. “Você tem sistemas de arquivos hierárquicos extremamente rápidos e prontos para desempenho.”
Hoje, não é incomum que os clientes tenham centenas de petabytes de dados não estruturados armazenados em sistemas de arquivos e armazenamento de objetos, com centenas e bilhões de arquivos ou objetos. Esses dados estão espalhados por extensões geográficas e por diferentes matrizes de armazenamento.
“E então você adiciona nuvem”, diz Mehta. “Portanto, seu nível de complexidade e expansão é enorme e o controle e o contexto dependem de onde está, de quem é, qual linha de negócios está vinculada a ele.”
Gerenciar essa enorme rede de dados e armazenamento já é bastante difícil. Mas quando você adiciona as visões díspares do CIO, do CDO e do CIO, tudo se torna uma bagunça complicada. O argumento da Knowledge Dynamics é que ele pode ajudar a gerenciar todos os dados não estruturados espalhados por silos distintos, ao mesmo tempo em que fornece recursos diferentes para usuários e casos de uso diferentes.
Por exemplo, as grandes empresas estão especialmente preocupadas neste momento com as implicações de privacidade e segurança da má gestão desses dados (como deveriam ser). Mas, ao mesmo tempo, esses enormes tesouros de dados não estruturados são verdadeiras minas de ouro de dados, apenas esperando para serem explorados pela GenAI. Equilibrar esse desejo de acessar o ouro não estruturado com o desejo de manter a empresa fora da cobertura do mercado Jornal de Wall Avenue por ser vítima do último hack, é o verdadeiro truque.
Tratamento de dados não estruturados
O grande desafio associado aos dados não estruturados é que esses dados não são nada bonitos e estruturados, armazenados em bancos de dados como SQL Server ou Oracle, diz Mehta. Muito disso é gerado por vários aplicativos.
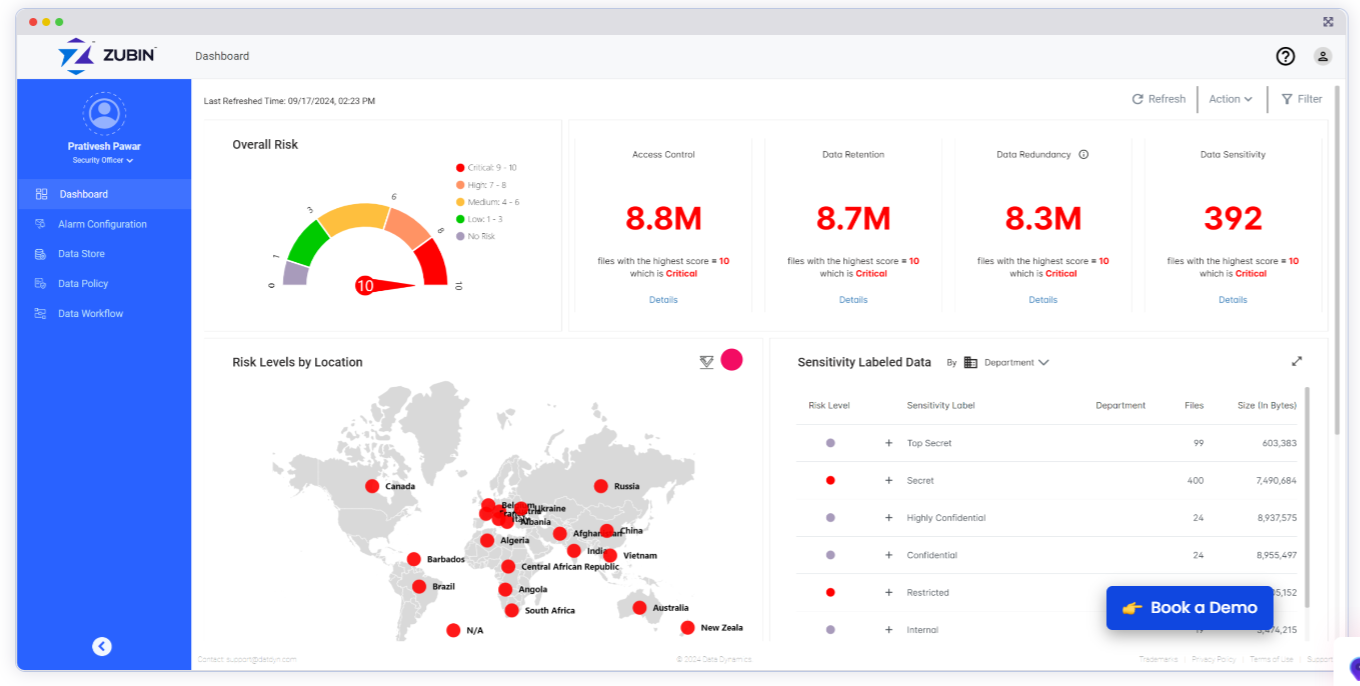
Zubin é o produto mais recente da Knowledge Dynamics para gerenciamento de dados não estruturados
“Podem ser arquivos tick gerados no mundo financeiro”, diz ele. “Podem ser arquivos de log gerados de maneira geral. Podem ser informações do dispositivo IoT. Podem ser arquivos sísmicos no mundo da energia. Podem ser registros de pacientes ou informações de ensaios clínicos ou imagens PACS (sistemas de arquivamento e comunicação de imagens) no mundo da saúde.”
O primeiro produto da Knowledge Dynamics, denominado Storage X, tinha como objetivo principal migrar esses dados de um repositório para outro. Quando Mehta percebeu que os clientes estavam simplesmente levantando e transferindo seus dados, perpetuando assim o problema do GIGO, ele percebeu que period necessária uma análise melhor. Isso levou à aquisição de uma empresa em Pune, na Índia, que desenvolveu uma ferramenta de análise de metadados, que a empresa expandiu.
Análises baseadas em metadados são necessárias para obter melhor inteligência sobre os dados que as empresas armazenaram em sistemas de arquivos e armazenamentos de objetos, incluindo armazenamentos de objetos NFS/SMB e compatíveis com S3, bem como ofertas de armazenamento de fornecedores, como Microsoft SharePoint, Dados VAST, NetApp, Delle Hitachi Vantara.
“A maioria dos nossos clientes corporativos tem centenas de bilhões de arquivos, então se você disser, ei, preciso abrir cada arquivo para ver o conteúdo, vai demorar um pouco”, diz Mehta. “Então acabamos adicionando uma coisa chamada amostragem estatística, que dizia ‘Ei, vamos escolher os metadados como um filtro e então ser espertos sobre o que encontramos e que nível de precisão isso nos oferece em termos do conteúdo que nós’ estamos procurando nesses arquivos.’”![]()
À medida que a empresa amadureceu, mudou o seu foco da otimização do armazenamento e da migração de dados para a democratização dos dados. Sua oferta mais recente, chamada Zubin, baseia-se nos recursos anteriores da Knowledge Dynamics para oferecer aos seus 300 clientes a capacidade de gerenciar centralmente as políticas para diferentes silos de dados não estruturados.
Uma vez que os dados são classificados em nível corporativo no Zubin, que foi revelado no mês passadocabe ao aplicativo particular person ou aos proprietários dos dados definir quais usuários podem acessar esses dados, por meio do controle de acesso baseado em função (RBAC). Isso dá aos clientes a capacidade de definir centralmente o gerenciamento de dados em todo o espectro de repositórios, desde o armazenamento native até o armazenamento em nuvem, ao mesmo tempo que libera os gerentes que estão mais próximos dos usuários para tomar decisões de acesso aos dados.
A empresa tem um tema chamado “Bytes to Rights”, que reflete suas ideias sobre a democratização de dados.
“Como você capacita os dados?” Mehta diz. “Para nós, isso é algo muito importante porque realmente acreditamos que cada empresa é a guardiã dos dados que possui, sejam os dados de seus funcionários ou os dados de seus clientes. Nesse caso, como podemos ajudá-los a se tornarem melhores guardiões? ?”
Itens relacionados:
Nutrindo a soberania dos dados em um mundo movido pela tecnologia
Crescimento de dados não estruturados prejudicando orçamentos de TI