Numa period em que os dados são a força important do avanço médico, a indústria de ensaios clínicos encontra-se numa encruzilhada crítica. O panorama atual da gestão de dados clínicos está repleto de desafios que ameaçam sufocar a inovação e atrasar tratamentos que salvam vidas.
À medida que enfrentamos um dilúvio de informações sem precedentes – com um ensaio típico de Fase III gerando agora impressionantes 3,6 milhões de pontos de dados, o que é três vezes mais do que há 15 anos, e mais de 4.000 novos ensaios autorizados a cada ano – nossas plataformas de dados existentes são curvando-se sob a tensão. Estes sistemas ultrapassados, caracterizados por silos de dados, fraca integração e enorme complexidade, estão a falhar os investigadores, os pacientes e o próprio progresso da ciência médica. A urgência desta situação é sublinhada por estatísticas nítidas: cerca de 80% dos ensaios clínicos enfrentam atrasos ou encerramento prematuro devido a desafios de recrutamento, com 37% dos locais de investigação a lutar para inscrever participantes adequados.
Estas ineficiências têm um custo elevado, com perdas potenciais que variam entre 600.000 dólares e 8 milhões de dólares por dia em que o desenvolvimento e lançamento de um produto atrasa. O mercado de ensaios clínicos, previsto para atingir 886,5 mil milhões de dólares até 2032 (1), exige uma nova geração de Repositórios de Dados Clínicos (CDR).
Reimaginando Repositórios de Dados Clínicos (CDR)
Normalmente, o gerenciamento de dados de ensaios clínicos depende de plataformas especializadas. Há muitas razões para isso, começando pelo processo de submissão padronizado pelas autoridades, a familiaridade do usuário com plataformas e linguagens de programação específicas e a capacidade de confiar no fornecedor da plataforma para fornecer conhecimento de domínio para a indústria.
Com a harmonização international da investigação clínica e a introdução de submissões electrónicas regulamentadas, é essencial compreender e operar no âmbito do desenvolvimento clínico international. Isto envolve a aplicação de padrões para desenvolver e executar arquiteturas, políticas, práticas, diretrizes e procedimentos para gerenciar eficazmente o ciclo de vida dos dados clínicos.
Alguns desses processos incluem:
- Arquitetura e Design de Dados: Modelagem de dados para repositórios ou armazéns de dados clínicos
- Governança e segurança de dados: Gerenciamento de padrões, SOPs e diretrizes juntamente com controle de acesso, arquivamento, privacidade e segurança
- Qualidade de dados e gerenciamento de metadados: Gerenciamento de consultas, integridade de dados e garantia de qualidade, integração de dados, transferência externa de dados, incluindo descoberta, publicação e padronização de metadados
- Armazenamento de dados, BI e gerenciamento de banco de dados: Ferramentas para mineração de dados e processos ETL
Esses elementos são cruciais para gerenciar eficazmente as complexidades dos dados clínicos.

As plataformas universais estão transformando o processamento de dados clínicos na indústria farmacêutica. Embora o software program especializado tenha sido a norma, as plataformas universais oferecem vantagens significativas, incluindo a flexibilidade para incorporar novos tipos de dados, capacidades de processamento quase em tempo actual, integração de tecnologias de ponta como IA e aprendizagem automática, e práticas robustas de processamento de dados refinadas pelo tratamento enormes volumes de dados.
Apesar das preocupações com a personalização e a transição de fornecedores familiares, as plataformas universais podem superar as soluções especializadas no gerenciamento de dados de ensaios clínicos. Databricks, por exemplo, é revolucionando como as empresas de ciências biológicas lidam com dados de ensaios clínicos integrando diversos tipos de dados e fornecendo uma visão abrangente da saúde do paciente.
Em essência, plataformas universais como o Databricks não estão apenas correspondendo às capacidades das plataformas especializadas – elas estão as superando, inaugurando uma nova period de eficiência e inovação no gerenciamento de dados de ensaios clínicos.
Aproveitando a plataforma Databricks Information Intelligence como base para CDR
A plataforma Databricks Information Intelligence é construída sobre arquitetura da casa do lago. A arquitetura Lakehouse é uma arquitetura de dados moderna que combina os melhores recursos de information lakes e information warehouses. Isto corresponde bem às necessidades do CDR moderno.
Embora a maioria dos dados de ensaios clínicos represente dados tabulares estruturados, novas modalidades de dados, como imagens e dispositivos vestíveis, estão ganhando popularidade. Eles são a nova forma de redefinir o processo de ensaios clínicos. O Databricks é hospedado em infraestrutura em nuvem, o que oferece a flexibilidade de usar armazenamento de objetos em nuvem para armazenar dados clínicos em escala. Ele permite armazenar todos os tipos de dados, controlar custos (dados mais antigos podem ser movidos para camadas mais frias para economizar custos, mas acomodar requisitos regulatórios de manutenção de dados) e disponibilidade e replicação de dados. Além disso, usar Databricks como tecnologia subjacente para CDR permite migrar para o modelo de desenvolvimento ágil, onde novos recursos podem ser adicionados em lançamentos controlados em oposição às atualizações de versão de software program do Huge Bang.
O Plataforma de inteligência de dados Databricks é uma plataforma de dados em grande escala que reúne processamento de dados, orquestração e funcionalidade de IA em um só lugar. Ele vem com muitos recursos de ingestão de dados padrão, incluindo conectores nativos e possivelmente implementando conectores personalizados. Ele nos permite integrar facilmente o CDR com fontes de dados e aplicativos downstream. Essa capacidade proporciona flexibilidade e qualidade e monitoramento de dados de ponta a ponta. O suporte nativo de streaming permite enriquecer o CDR com dados IoMT e obter insights quase em tempo actual assim que os dados estiverem disponíveis. A observabilidade da plataforma é um grande tema para o CDR, não apenas devido aos rigorosos requisitos regulamentares, mas também porque permite o uso secundário de dados e a capacidade de gerar insights, o que, em última análise, pode melhorar o processo geral do ensaio clínico. O processamento de dados clínicos em Databricks permite a implementação de soluções flexíveis para obter informações sobre o processo. Por exemplo, o processamento de imagens de ressonância magnética consome mais recursos do que o processamento de resultados de testes de tomografia computadorizada?
Implementando um repositório de dados clínicos: uma abordagem em camadas com databricks
Os Repositórios de Dados Clínicos são plataformas sofisticadas que integram o armazenamento e processamento de dados clínicos. Casa do lago arquitetura medalhãouma abordagem em camadas para processamento de dados, é particularmente adequada para CDRs. Essa arquitetura normalmente consiste em três camadas, cada uma refinando progressivamente a qualidade dos dados:
- Camada de Bronze: Dados brutos ingeridos de várias fontes e protocolos
- Camada Prateada: Dados conformados com formatos padrão (por exemplo, SDTM) e validados
- Camada Dourada: Dados agregados e filtrados prontos para revisão e análise estatística
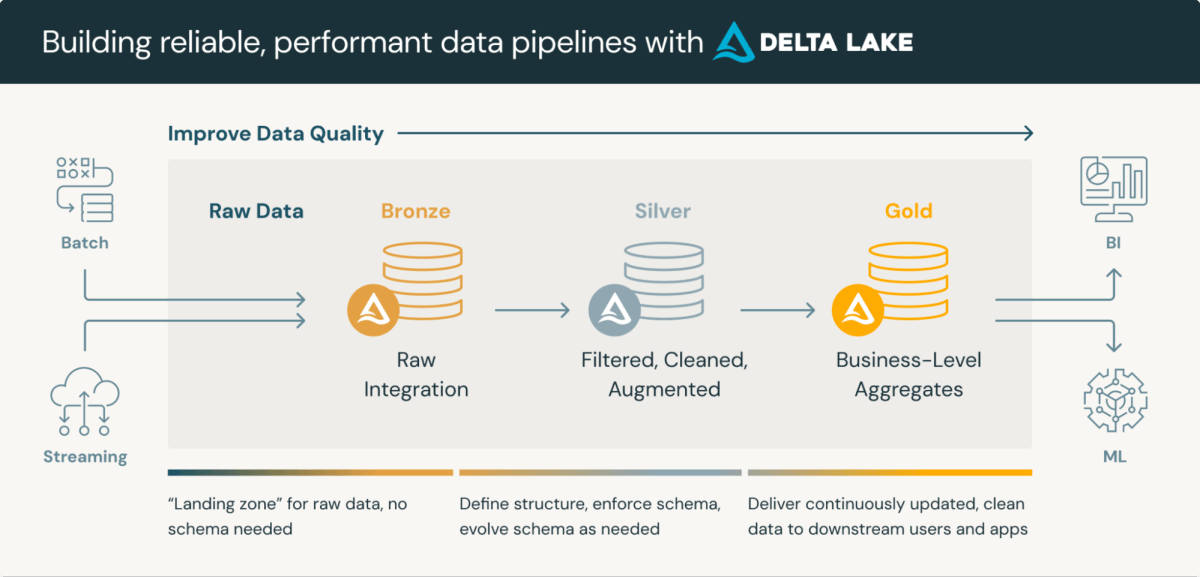
Utilizando Lago Delta formato para armazenamento de dados em Databricks oferece benefícios inerentes, como validação de esquema e recursos de viagem no tempo. Embora esses recursos precisem de aprimoramento para atender plenamente aos requisitos regulatórios, eles fornecem uma base sólida para conformidade e processamento simplificado.
A plataforma Databricks Information Intelligence vem equipada com ferramentas robustas de governança. Catálogo de Unidadeum componente-chave, oferece governança de dados abrangente, auditoria e controle de acesso dentro da plataforma. No contexto dos CDRs, o Unity Catalog permite:
- Rastreamento de linhagem de tabelas e colunas
- Armazenando histórico de dados e logs de alterações
- Controle de acesso refinado e trilhas de auditoria
- Integração de linhagem de sistemas externos
- Implementação de estruturas de permissão rigorosas para evitar acesso não autorizado a dados
Além do processamento de dados, os CDRs são cruciais para manter registros dos processos de validação de dados. As verificações de validação devem ser controladas por versão em um repositório de código, permitindo que múltiplas versões coexistam e se vinculem a diferentes estudos. Suporte para databricks Repositórios Git e práticas estabelecidas de CI/CD, permitindo a implementação de uma biblioteca robusta de verificação de validação.
Esta abordagem à implementação de CDR em Databricks garante a integridade e conformidade dos dados e fornece a flexibilidade e escalabilidade necessárias para a gestão moderna de dados clínicos.

A plataforma de inteligência de dados Databricks se alinha inerentemente com Princípios FAIR de gerenciamento de dados científicosoferecendo uma abordagem avançada para gerenciamento de dados de desenvolvimento clínico. Ele melhora a localização, acessibilidade, interoperabilidade e capacidade de reutilização dos dados, ao mesmo tempo em que mantém a robustez segurança e conformidade em sua essência.
Desafios na implementação de CDRs modernos
Nenhuma nova abordagem vem sem desafios. O gerenciamento de dados clínicos depende muito de SAS, enquanto as plataformas de dados de modem utilizam principalmente Python, R e SQL. Isto obviamente introduz não apenas uma desconexão técnica, mas também desafios de integração mais práticos. R é uma ponte entre dois mundos – Databricks faz parceria com Posit para oferecer experiência R de primeira classe para usuários R. Ao mesmo tempo, é possível integrar Databricks com SAS para apoiar migrações e transições. Assistente de blocos de dados permite que usuários menos familiarizados com uma linguagem específica obtenham o suporte necessário para escrever código de alta qualidade e compreender os exemplos de código existentes.
Uma plataforma de processamento de dados construída sobre uma plataforma common sempre estará atrasada na implementação de recursos específicos de domínio. A forte colaboração com parceiros de implementação ajuda a mitigar este risco. Além disso, a adoção de um modelo de preços baseado no consumo requer atenção redobrada aos custos, que precisam ser abordados para garantir o monitoramento e observabilidade da plataforma, o treinamento adequado dos usuários e a adesão às melhores práticas.
O maior desafio é a taxa geral de sucesso desses tipos de implementações. As empresas farmacêuticas procuram constantemente modernizar as suas plataformas de dados de ensaios clínicos. É uma área atraente para trabalhar para reduzir a duração dos ensaios clínicos ou descontinuar ensaios que provavelmente não terão sucesso mais rapidamente. A quantidade de dados coletados atualmente pela empresa farmacêutica média contém uma vasta quantidade de insights que estão apenas esperando para serem discutidos. Ao mesmo tempo, a maioria desses projetos fracassa. Embora não exista uma receita mágica para garantir uma taxa de sucesso de 100%, a adoção de uma plataforma common como o Databricks permite implementar o CDR como uma camada fina sobre a plataforma existente, eliminando os problemas comuns de dados e infraestrutura.
O que vem a seguir?
Toda implementação de CDR começa com o inventário dos requisitos. Embora a indústria siga padrões rígidos tanto para modelos de dados quanto para processamento de dados, compreender os limites do CDR em cada organização é essencial para garantir o sucesso do projeto. A Databricks Information Intelligence Platform pode abrir muitos recursos adicionais para CDR; é por isso que é necessário entender como funciona e o que oferece. Comece explorando a plataforma Databricks Information Intelligence. Governança unificada com Catálogo de Unidadepipelines de ingestão de dados com Fluxo do lagosuíte de inteligência de dados com IA/BI e recursos de IA com IA em mosaico não deveriam ser termos desconhecidos para implementar um CDR bem-sucedido e preparado para o futuro. Além disso, a integração com o Posit e a observabilidade avançada de dados funcionalmente devem abrir a possibilidade de olhar para o CDR como um núcleo do ecossistema de dados clínicos, em vez de apenas outra parte do pipeline geral de processamento de dados clínicos.
Cada vez mais empresas já estão modernizando suas plataformas de dados clínicos utilizando arquiteturas modernas como Lakehouse. Mas a grande mudança ainda está por vir. A expansão da IA generativa e de outras tecnologias de IA já está a revolucionar outras indústrias, enquanto a indústria farmacêutica está atrasada devido a restrições regulamentares, ao alto risco e ao preço dos resultados errados. Plataformas como o Databricks permitem a inovação intersetorial e o desenvolvimento orientado por dados para ensaios clínicos e criam uma nova maneira de pensar sobre os ensaios clínicos em geral.
Comece hoje com Blocos de dados.
Citação:
(1) Estatísticas de ensaios clínicos 2024 por fases, definição e intervenções
(2) Lu, Z. e Su, J. (2010). Gerenciamento de dados clínicos: standing atual, desafios e direções futuras a partir das perspectivas do setor. Jornal de Ensaios Clínicos de Acesso Aberto, 2, 93–105. https://doi.org/10.2147/OAJCT.S8172
Saber mais sobre a plataforma Databricks Information Intelligence para saúde e ciências biológicas.