
Incerteza no aprendizado de máquina: probabilidade e ruído
Imagem do autor
Nota do editor: Este artigo faz parte de nossa série sobre como visualizar os fundamentos do aprendizado de máquina.
Bem-vindo ao último capítulo de nossa série sobre como visualizar os fundamentos do aprendizado de máquina. Nesta série, nosso objetivo será dividir conceitos técnicos importantes e muitas vezes complexos em guias visuais intuitivos para ajudá-lo a dominar os princípios básicos da área. Esta entrada concentra-se na incerteza, probabilidade e ruído no aprendizado de máquina.
Incerteza no aprendizado de máquina
A incerteza é uma parte inevitável do aprendizado de máquina, surgindo sempre que os modelos tentam fazer previsões sobre o mundo actual. Na sua essência, a incerteza reflecte uma falta de conhecimento completo sobre um resultado e é mais frequentemente quantificado usando probabilidade. Em vez de ser uma falha, a incerteza é algo que os modelos devem explicar explicitamente para produzir previsões fiáveis e fiáveis.
Uma maneira útil de pensar sobre a incerteza é através das lentes da probabilidade e do desconhecido. Assim como jogar uma moeda justa, onde o resultado é incerto, embora as probabilidades sejam bem definidas, os modelos de aprendizado de máquina operam frequentemente em ambientes onde vários resultados são possíveis. À medida que os dados fluem através de um modelo, as previsões se ramificam em caminhos diferentes, influenciadas pela aleatoriedade, informações incompletas e variabilidade nos próprios dados.
O objetivo de trabalhar com a incerteza não é eliminá-la, mas sim medir e gerenciar. Isso envolve a compreensão de vários componentes principais:
- Probabilidade fornece uma estrutura matemática para expressar a probabilidade de um evento ocorrer
- Barulho representa variação irrelevante ou aleatória nos dados que obscurece o sinal verdadeiro e pode ser aleatória ou sistemática
Junto, esses fatores moldam a incerteza presente nas previsões de um modelo.
Nem todas as incertezas são iguais. Incerteza aleatória decorre da aleatoriedade inerente aos dados e não pode ser reduzida, mesmo com mais informações. Incerteza epistêmicapor outro lado, surge da falta de conhecimento sobre o modelo ou processo de geração de dados e pode muitas vezes ser reduzido através da recolha de mais dados ou da melhoria do modelo. Distinguir entre esses dois tipos é essencial para interpretar o comportamento do modelo e decidir como melhorar o desempenho.
Para gerenciar a incerteza, os profissionais de aprendizado de máquina contam com diversas estratégias. Modelos probabilísticos produz distribuições de probabilidade completas em vez de estimativas de ponto único, tornando a incerteza explícita. Métodos de conjunto combinar previsões de vários modelos para reduzir a variância e estimar melhor a incerteza. Limpeza e validação de dados melhorar ainda mais a confiabilidade, reduzindo o ruído e corrigindo erros antes do treinamento.
A incerteza é inerente aos dados do mundo actual e aos sistemas de aprendizado de máquina. Ao reconhecer as suas fontes e incorporá-las diretamente na modelagem e na tomada de decisões, os profissionais podem construir modelos que não são apenas mais precisos, mas também mais precisos. robusto, transparente e confiável.
O visualizador abaixo fornece um resumo conciso dessas informações para referência rápida. Você pode encontrar um PDF do infográfico em alta resolução aqui.
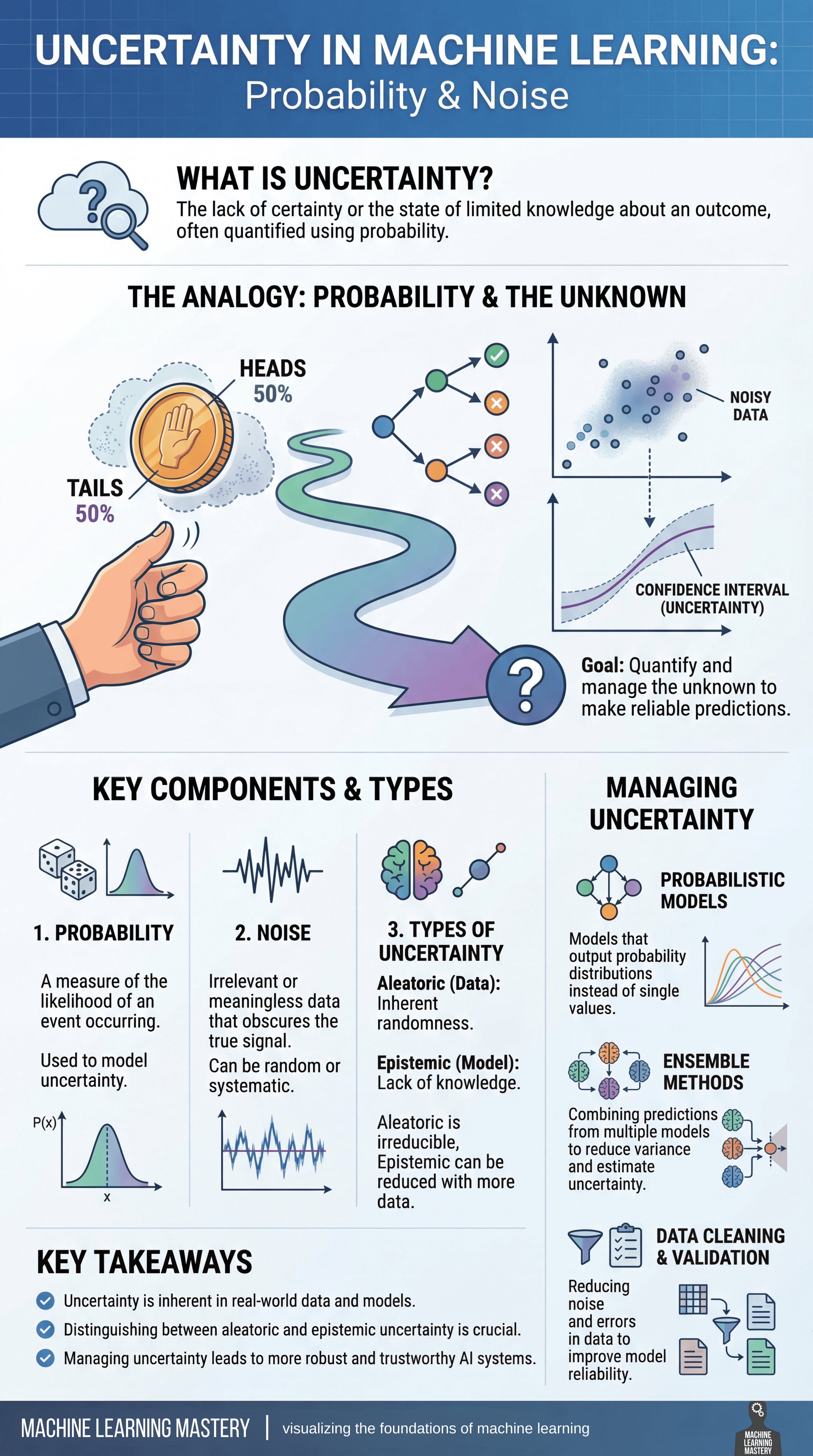
Incerteza, probabilidade e ruído: visualizando os fundamentos do aprendizado de máquina (clique para ampliar)
Imagem do autor
Recursos de domínio de aprendizado de máquina
Estes são alguns recursos selecionados para aprender mais sobre probabilidade e ruído:
- Uma introdução suave à incerteza no aprendizado de máquina – Este artigo explica o que significa incerteza no aprendizado de máquina, explora as principais causas, como ruído nos dados, cobertura incompleta e modelos imperfeitos, e descreve como a probabilidade fornece as ferramentas para quantificar e gerenciar essa incerteza.
Conclusão principal: A probabilidade é essencial para compreender e gerenciar a incerteza na modelagem preditiva. - Probabilidade de aprendizado de máquina (minicurso de 7 dias) – Este curso intensivo estruturado orienta os leitores através dos principais conceitos de probabilidade necessários no aprendizado de máquina, desde tipos básicos de probabilidade e distribuições até Naive Bayes e entropia, com lições práticas projetadas para aumentar a confiança na aplicação dessas ideias em Python.
Conclusão principal: Construir uma base sólida em probabilidade aumenta sua capacidade de aplicar e interpretar modelos de aprendizado de máquina. - Compreendendo distribuições de probabilidade para aprendizado de máquina com Python – Este tutorial apresenta distribuições de probabilidade importantes usadas no aprendizado de máquina, mostra como elas se aplicam a tarefas como modelagem de resíduos e classificação e fornece exemplos de Python para ajudar os profissionais a entendê-las e usá-las de maneira eficaz.
Conclusão principal: Dominar as distribuições de probabilidade ajuda a modelar a incerteza e a escolher ferramentas estatísticas apropriadas em todo o fluxo de trabalho de aprendizado de máquina.
Fique atento a entradas adicionais em nossa série sobre como visualizar os fundamentos do aprendizado de máquina.
Sobre Matheus Mayo
Matheus Mayo (@mattmayo13) possui mestrado em ciência da computação e pós-graduação em mineração de dados. Como editor-chefe da KDnuggets & Estatologiae editor colaborador em Domínio do aprendizado de máquinaMatthew pretende tornar acessíveis conceitos complexos de ciência de dados. Seus interesses profissionais incluem processamento de linguagem pure, modelos de linguagem, algoritmos de aprendizado de máquina e exploração de IA emergente. Ele é movido pela missão de democratizar o conhecimento na comunidade de ciência de dados. Matthew codifica desde os 6 anos de idade.